分布式爬蟲 - scrapy-redis 分布式系統(tǒng)?
問題描述
現(xiàn)在可以從網(wǎng)上下載這些代碼,怎么進(jìn)行部署和運(yùn)行代碼從github上下載了關(guān)于分布式的代碼,不知道怎么用,求各位大神指點(diǎn)下。。。下面是網(wǎng)址https://github.com/rolando/scrapy-redis環(huán)境已經(jīng)按照上面的配置好了,但不知道如何實(shí)現(xiàn)分布式。分布式我是這樣理解的,有一個(gè)redis服務(wù)器,從一個(gè)網(wǎng)頁上獲取url種子,并將url種子放到redis服務(wù)器了,然后將這些url種子分配給其他機(jī)器。中間存在調(diào)度方面的問題,以及服務(wù)器和機(jī)器間的通信。
謝謝。。。
問題解答
回答1:感覺這個(gè)不是一兩句話可以描述清楚 的。
我之前參考的這篇博文,希望對(duì)你有幫助。
說說我個(gè)人的理解吧。
scrapy使用改良之后的python自帶的collection.deque來存放待爬取的request,該怎么讓兩個(gè)以上的Spider共用這個(gè)deque呢?
待爬隊(duì)列都不能共享,分布式就是無稽之談。scrapy-redis提供了一個(gè)解決方法,把collection.deque換成redis數(shù)據(jù)庫,多個(gè)爬蟲從同一個(gè)redis服務(wù)器存放要爬取的request,這樣就能讓多個(gè)spider去同一個(gè)數(shù)據(jù)庫里讀取,這樣分布式的主要問題就解決了.
注意:并不是換了redis來存放request,scrapy就能直接分布式了!
scrapy中跟待爬隊(duì)列直接相關(guān)的就是調(diào)度器Scheduler。
參考scrapy的結(jié)構(gòu)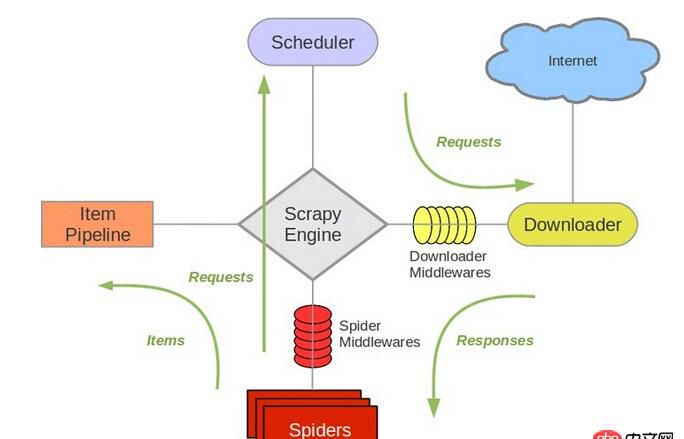
它負(fù)責(zé)對(duì)新的request進(jìn)行入列操作,取出下一個(gè)要爬取的request等操作。所以,換了redis之后,其他組件都要改動(dòng)。
所以,我個(gè)人的理解就是,在多個(gè)機(jī)器上部署相同的爬蟲,分布式部署redis,參考地址我的博客,比較簡單。而這些工作,包括url去重,就是已經(jīng)寫好的scrapy-redis框架的功能。
參考地址在這里,你可以去下載example看看具體的實(shí)現(xiàn)。我最近也在搞這個(gè)scrapy-redis,等我部署好了在更新的這個(gè)答案。
你有新的進(jìn)展可以分享出來交流。
回答2:@韋軒 您好,我看這段評(píng)論在15.10.11,請(qǐng)問您現(xiàn)在是否有結(jié)果了?能否推薦一些您的博客,謝謝您~可以聯(lián)系我chenjian158978@gmail.com
相關(guān)文章:
1. docker-machine添加一個(gè)已有的docker主機(jī)問題2. node.js - node express 中ajax post請(qǐng)求參數(shù)接收不到?3. html - 用ajax提交表單后,返回驗(yàn)證數(shù)據(jù)在頁面location.href跳轉(zhuǎn)到主頁,怎么傳遞session給主頁4. angular.js - grunt server 報(bào)錯(cuò)5. apache - nginx 日志刪除后 重新建一個(gè)文件 就打不了日志了6. java - tomcat服務(wù)經(jīng)常晚上會(huì)掛,求解?7. java - 原生CGLib內(nèi)部方法互相調(diào)用時(shí)可以代理,但基于CGLib的Spring AOP卻代理失效,為什么?8. 網(wǎng)站被黑,請(qǐng)教下大神,怎么對(duì)datebase.php內(nèi)容加密。9. mysql - sql查詢語句問題10. mysql的主從復(fù)制、讀寫分離,關(guān)于從的問題

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備