文章詳情頁
python - 基于scrapy-redis的分布式爬蟲運行的時候不能正常運行 遇到的問題如下截圖所示
瀏覽:115日期:2022-08-03 11:20:00
問題描述
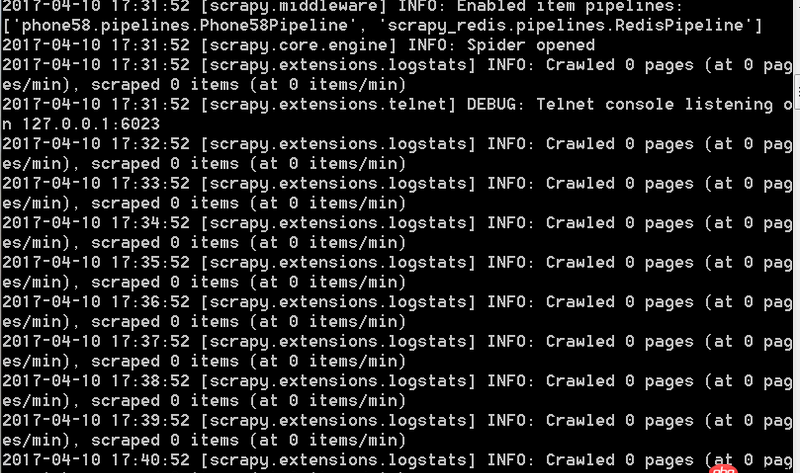
爬蟲運行時一直是這樣的每一分鐘出現一條這樣的信息,無限循環。不能爬取下來數據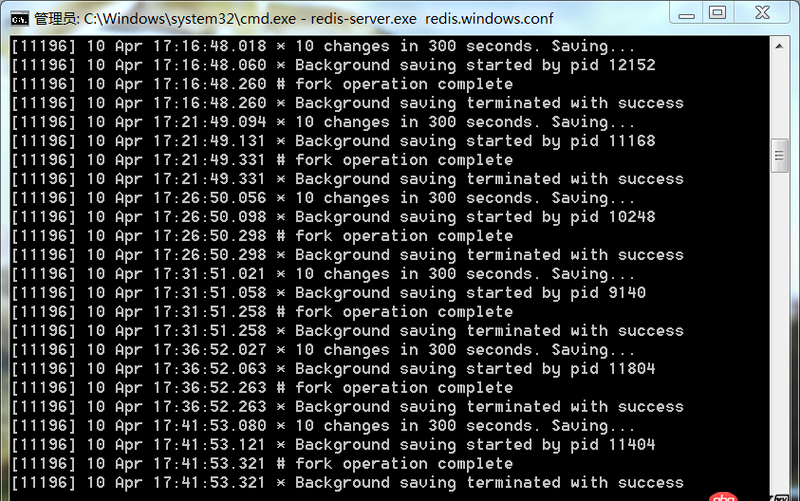
這是redis服務端的顯示
這樣是什么問題,望有高手可以為我解惑,謝謝。
問題解答
回答1:使用scrapy_redis,你要去投放url讓spider去爬取,你投放了嗎?比如
redis-cli lpush myspider:start_urls http://google.com
相關文章:
1. javascript - 微信網頁開發從菜單進入頁面后,按返回鍵沒有關閉瀏覽器而是刷新當前頁面,求解決?2. 求救一下,用新版的phpstudy,數據庫過段時間會消失是什么情況?3. mysql replace 死鎖4. mysql - C#連接數據庫時一直這一句出問題int i = cmd.ExecuteNonQuery();5. python - 數據與循環次數對應不上6. extra沒有加載出來7. android - 安卓做前端,PHP做后臺服務器 有什么需要注意的?8. 環境搭建 - anaconda 創建python2.7環境中打開編譯器確是3.6版本9. php傳對應的id值為什么傳不了啊有木有大神會的看我下方截圖10. mysql - ubuntu開啟3306端口失敗,有什么辦法可以解決?
排行榜
 網公網安備
網公網安備