python - mongodb 去重
問題描述
爬取了一個用戶的論壇數據,但是這個數據庫中有重復的數據,于是我想把重復的數據項給去掉。數據庫的結構如下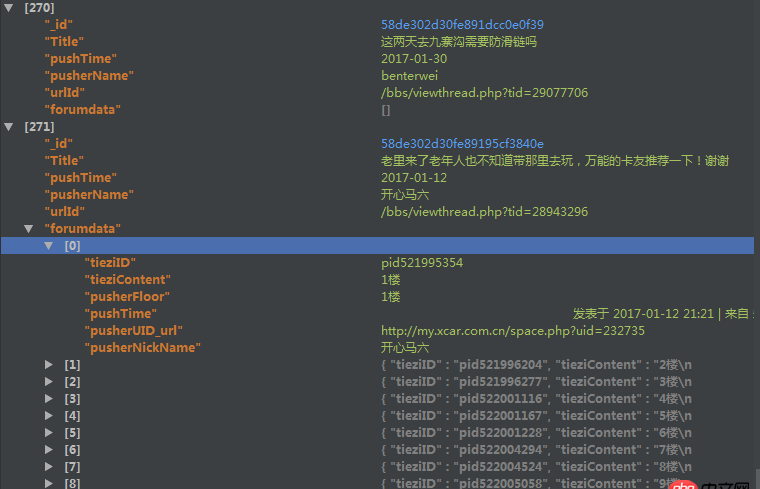
里邊的forundata是這個帖子的每個樓層的發(fā)言情況。但是因為帖子爬取的時候有可能重復爬取了,我現在想根據里邊的urlId來去掉重復的帖子,但是在去除的時候我想保留帖子的forumdata(是list類型)字段中列表長度最長的那個。用mongodb的distinct方法只能返回重復了的帖子urlId,都不返回重復帖子的其他信息,我沒法定位。。。假如重復50000個,那么我還要根據這些返回的urlId去數據庫中find之后再在mongodb外邊代碼修改嗎?可是即使這樣,我發(fā)現運行的時候速度特別慢。之后我用了group函數,但是在reduce函數中,因為我要比較forumdata函數的大小,然后決定保留哪一個forumdata,所以我要傳入forumdata,但是有些forumdata大小超過了16M,導致報錯,然后這樣有什么解決辦法嗎?或者用第三種方法,用Map_reduce,但是我在map-reduce中的reduce傳入的forumdata大小限制竟然是8M,還是報錯。。。
代碼如下group的代碼:
reducefunc=Code( ’function(doc,prev){’ ’if (prev==null){’ ’prev=doc’ ’}’ ’if(prev!=null){’ ’if (doc.forumdata.lenth>prev.forumdata.lenth){’ ’prev=doc’ ’}’ ’}’ ’}’)
map_reduce的代碼:
reducefunc=Code( ’function(urlId,forumdata){’ ’if(forumdata.lenth=1){’ ’return forumdata[0];’ ’}’ ’else if(forumdata[0].lenth>forumdata[1].lenth){’ ’return forumdata[0];’ ’}’ ’else{’ ’return forumdata[1]}’ ’}’)mapfunc=Code( ’function(){’ ’emit(this.urlId,this.forumdata)’ ’}’)
望各位高手幫我看看這個問題該怎么解決,三個方案中隨便各一個就好,或者重新幫我分析一個思路,感激不盡。鄙人新人,問題有描述不到位的地方請?zhí)岢鰜恚視⒓囱a充完善。
問題解答
回答1:如果這個問題還沒有解決,不妨參考下面的想法:
1、MongoDB中推薦使用aggregation,而不推薦使用map-reduce;
2、您的需求中,很重要的一點是獲取Forumdata的長度:數組的長度,從而找到數組長度最長的document。您原文說Forumdata是列表(在MongoDB中應該是數組);MongoDB提供了$size運算符號取得數組的大小。
請參考下面的栗子:
> db.data.aggregate([ {$project : { '_id' : 1, 'name' : 1, 'num' : 1, 'length' : { $size : '$num'}}}]){ '_id' : ObjectId('58e631a5f21e5d618900ec20'), 'name' : 'a', 'num' : [ 12, 123, 22, 34, 1 ], 'length' : 5 }{ '_id' : ObjectId('58e631a5f21e5d618900ec21'), 'name' : 'b', 'num' : [ 42, 22 ], 'length' : 2 }{ '_id' : ObjectId('58e631a7f21e5d618900ec22'), 'name' : 'c', 'num' : [ 49 ], 'length' : 1 }
3、有了上面的數據后,然后可以利用aggregation中的$sort,$group等找到滿足您的需求的Document的objectId,具體做法可以參考下面的帖子:
https://segmentfault.com/q/10...
4、最后批量刪除相關的ObjectId
類似于:var dupls = [] 保存要刪除的objectIddb.collectionName.remove({_id:{$in:dupls}})
供參考。
Love MongoDB! Have Fun!
戳我<--請戳左邊,就在四月!MongoDB中文社區(qū)深圳用戶大會開始報名啦!大神云集!
回答2:數據量的規(guī)模不是很大的話可以考慮重新爬取一次,每次存的時候查詢一下,只存數據最多的一組數據。優(yōu)秀的爬蟲策略>>優(yōu)秀的數據清洗策略
回答3:感謝各位網友,在qq群中,有人給出了思路,是在map的是先以urlId對forumdata進行處理,返回urlId和forumdatad.length,之后再在reduce中處理,保留forumdata.length最大的那個和對應的urlId,最后保存成一個數據庫,之后通過這個數據庫中的urlId來從原數據庫中將所有數據讀取出來。我試過了,雖然效率不是我期望的那種,不過速度還是比以前用python處理快了不少。附上map和reduce的代碼:’’’javaScriptmapfunc=Code(
’function(){’’data=new Array();’’data={lenth:this.forumdata.length,’’id:this._id};’# ’data=this._id;’’emit({'id':this.urlId},data);’’}’)
reducefunc=Code(
’function(tieziID,dataset){’’reduceid=null;’’reducelenth=0;’’’’’’redecenum1=0;’’redecenum2=0;’’’’dataset.forEach(function(val){’’if(reducelenth<=val['lenth']){’’reducelenth=val['lenth'];’’reduceid=val['id'];’’redecenum1+=1;’’}’’redecenum2+=1;’’});’’return {'lenth':reducelenth,'id':reduceid};’’}’ )
上邊是先導出一個新的數據庫的代碼,下邊是處理這個數據庫的代碼:
mapfunc=Code(
’function(){’# ’data=new Array();’’lenth=this.forumdata.length;’’’’emit(this.urlId,lenth);’’}’
)
reducefunc=Code(
’function(key,value){’’return value;’’}’
)
之后添加到相應的map_reduce中就行了。感覺Bgou回答的不錯,所以就選他的答案了,還沒有去實踐。上邊是我的做法,就當以后給遇到同樣問題的人有一個參考。
相關文章:
1. php - mysql 模糊搜索問題2. javascript - 我的站點貌似被別人克隆了, google 搜索特定文章,除了域名不一樣,其他的都一樣,如何解決?3. javascript - 在 vue里面用import引入js文件,結果為undefined4. 求救一下,用新版的phpstudy,數據庫過段時間會消失是什么情況?5. python沒入門,請教一個問題6. html - 爬蟲時出現“DNS lookup failed”,打開網頁卻沒問題,這是什么情況?7. php如何獲取訪問者路由器的mac地址8. php - 微信開發(fā)驗證服務器有效性9. javascript - js setTimeout在雙重for循環(huán)中如何使用?10. 小程序怎么加外鏈,語句怎么寫!求救新手,開文檔沒發(fā)現

 網公網安備
網公網安備