文章詳情頁
python - 標簽樹的下行遍歷如何跳過第一個標簽
瀏覽:101日期:2022-08-08 11:07:17
問題描述
爬取網頁用下行遍歷的找出了我要的標簽,但第一個的內容我是不要的用.children好像無法跳出第一個標簽
for tr in soup.find(id='endText').children: if tr.string is not None:a = tr.string
網頁的內容:
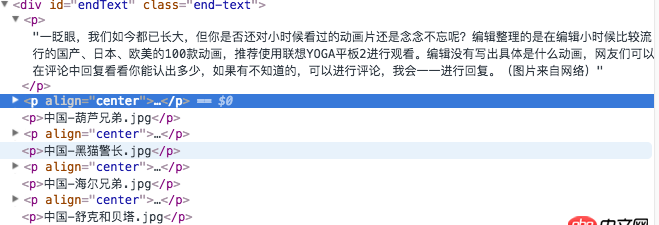 原鏈接:http://digi.163.com/14/1115/0...
原鏈接:http://digi.163.com/14/1115/0...
問題解答
回答1:p_list = list(soup.find(id='endText').find_all(’p’))for p in p_list[1:]: text = p.get_text() img = p.find('img') if img:print img.get(’src’) if text:print text
相關文章:
排行榜

 網公網安備
網公網安備