文章詳情頁(yè)
網(wǎng)頁(yè)爬蟲(chóng) - Python爬蟲(chóng)返回狀態(tài)碼與實(shí)際情況不符?
瀏覽:194日期:2022-09-03 18:57:11
問(wèn)題描述
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個(gè)爬蟲(chóng),輸出狀態(tài)碼是200。
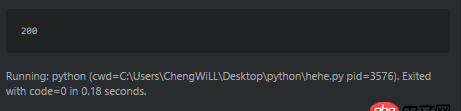
可是直接訪問(wèn)http://www.sxxrcs.com/was5/web/是404,抓包響應(yīng)的也是404,請(qǐng)問(wèn)這是為什么?
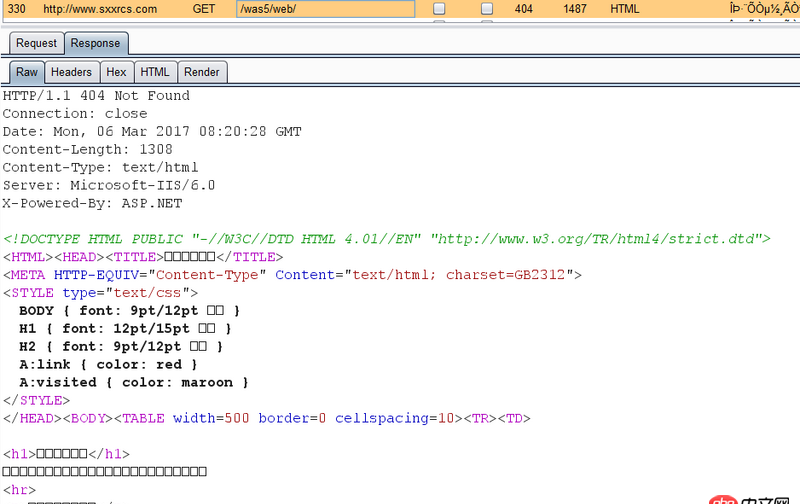
問(wèn)題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關(guān)文章:
1. java - public <T> T findOne(T record) 這是什么意思2. css - 關(guān)于ul的布局3. python - linux怎么在每天的凌晨2點(diǎn)執(zhí)行一次這個(gè)log.py文件4. android - 優(yōu)酷的安卓及蘋(píng)果app還在使用flash技術(shù)嗎?5. mysql數(shù)據(jù)庫(kù)每次查詢是一條線程嗎?6. javascript - 前端開(kāi)發(fā) 本地靜態(tài)文件頻繁修改,預(yù)覽時(shí)的緩存怎么解決?7. docker不顯示端口映射呢?8. 如何分別在Windows下用Winform項(xiàng)模板+C#,在MacOSX下用Cocos Application項(xiàng)目模板+Objective-C實(shí)現(xiàn)一個(gè)制作游戲的空的黑窗口?9. javascript - js中遞歸與for循環(huán)同時(shí)發(fā)生的時(shí)候,代碼的執(zhí)行順序是怎樣的?10. html5和Flash對(duì)抗是什么情況?
排行榜
熱門(mén)標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備