詳解用Python把PDF轉(zhuǎn)為Word方法總結(jié)
先講一下為啥要寫這個(gè)文章,網(wǎng)上其實(shí)很多這種PDF轉(zhuǎn)化的代碼和軟件。我一直想用Python做,但是網(wǎng)上搜到的代碼很多都不能用,很多是2.7版本的代碼,再就是PDF需要用到的庫(kù)在導(dǎo)入的時(shí)候,很多的報(bào)錯(cuò),解決起來(lái)特別費(fèi)勁,而且自從2021年初以來(lái),似乎網(wǎng)上很少有關(guān)PDF轉(zhuǎn)化的代碼出現(xiàn)了。我在研究了很多代碼和pdfminer的用法后,總結(jié)了幾個(gè)方法,目前這幾種方法可以解決大多數(shù)格式的轉(zhuǎn)化,后面我也專門放了提取PDF表格的代碼,文末有高效的免費(fèi)在線工具推薦。
下面這個(gè)是我最最推薦的方法 ,簡(jiǎn)單高效 ,只要是標(biāo)準(zhǔn)PDF文檔,里面的圖片和表格都可以保留格式
# pip install pdf2docx #安裝依賴庫(kù)from pdf2docx import Converterpdf_file = r’C:UsersAdministratorDesktop新建文件夾mednine.pdf’docx_file = r’C:UsersAdministratorDesktopPython教程02.docx’# convert pdf to docxcv = Converter(pdf_file)cv.convert(docx_file, start=0, end=None)cv.close()下面是另外三種常用方法
1 把標(biāo)準(zhǔn)格式的PDF轉(zhuǎn)為Word,測(cè)試環(huán)境Python3.6.5和3.6.6(注意PDF內(nèi)容僅僅是文字為主的里面沒(méi)有圖片圖表的適用,不適合掃描版PDF,因?yàn)槟侵荒苡脠D片識(shí)別的方式進(jìn)行)
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreterfrom pdfminer.converter import TextConverterfrom pdfminer.layout import LAParamsfrom pdfminer.pdfpage import PDFPagefrom io import StringIOimport sysimport stringfrom docx import Documentdef convert_pdf_2_text(path): rsrcmgr = PDFResourceManager() retstr = StringIO()device = TextConverter(rsrcmgr, retstr, codec=’utf-8’, laparams=LAParams()) interpreter = PDFPageInterpreter(rsrcmgr, device)with open(path, ’rb’) as fp:for page in PDFPage.get_pages(fp, set()): interpreter.process_page(page) #print(retstr.getvalue()) text = retstr.getvalue() device.close() retstr.close() return textdef pdf2txt(): text=convert_pdf_2_text(path) with open(’real.txt’,’a’,encoding=’utf-8’) as f:for line in text.split(’n’): f.write(line+’n’)def remove_control_characters(content): mpa = dict.fromkeys(range(32)) return content.translate(mpa) def save_text_to_word(content, file_path): doc = Document() for line in content.split(’’):print(line) paragraph = doc.add_paragraph()paragraph.add_run(remove_control_characters(line)) doc.save(file_path)if __name__ == ’__main__’: path = r’C:UsersmaynDesktop程序臨時(shí)培訓(xùn)教材.pdf’ # 你自己的pdf文件路徑及文件名 不適合掃描版 只適合標(biāo)準(zhǔn)PDF文件 text = convert_pdf_2_text(path) save_text_to_word(text, ’output.doc’) #PDF轉(zhuǎn)為word方法 #pdf2txt() #PDF轉(zhuǎn)為txt方法
2專門提取PDF里面的表格,使用pdfplumber適合標(biāo)準(zhǔn)格式的PDF
import pdfplumberimport pandas as pdimport timefrom time import ctimeimport psutil as ps #import threadingimport gcpdf = pdfplumber.open(r'C:UsersAdministratorDesktop新建文件夾mednine.pdf')N=len(pdf.pages)print(’總共有’,N,’頁(yè)’)def pdf2exl(i): # 讀取了第i頁(yè),第i頁(yè)是有表格的, print(’********************************************************************************************************************************************************’) print(’正在輸出第’,str(i+1),’頁(yè)表格’) print(’********************************************************************************************************************************************************’) p0 = pdf.pages[i] try:table = p0.extract_table()print(table) df = pd.DataFrame(table[1:], columns=table[0]) #print(df)df.to_excel(r'C:UsersAdministratorDesktop新建文件夾Model'+str(i+1)+'.xlsx') #df.info(memory_usage=’deep’) except Exception as e:print(’第’+str(i+1)+’頁(yè)無(wú)表格,或者檢查是否存在表格’) pass #print(’目前內(nèi)存占用率是百分之’,str(ps.virtual_memory().percent),’ 第’,str(i+1),’頁(yè)輸出完畢’) print(’**********************************************************************************************************************************************************’) print(’nnn’) time.sleep(5)def dojob1(): #此函數(shù) 直接循環(huán)提取PDF里面各個(gè)頁(yè)面的表格 print(’*********************’) for i in range(0,N):pdf2exl(i)
3也可以提取PDF里面的表格,使用camelot(camelot的安裝可能需要點(diǎn)耐心,反正用的人不多)
import camelotimport wand# 從PDF文件中提取表格def output(i): #print(tables) #for i in range(5): tables = camelot.read_pdf(r’C:UsersAdministratorDesktop新建文件夾mednine.pdf’, pages=str(i), flavor=’stream’) print(tables[i]) # 表格數(shù)據(jù) print(tables[i].data)tables[i].to_csv(r’C:UsersAdministratorDesktop新建文件夾002’+str(i)+r’.csv’)def plotpdf():# 這個(gè)是畫pdf 結(jié)構(gòu)的函數(shù) 現(xiàn)在不能用 不要打開#print(tables[0]) tables = camelot.read_pdf(r’C:UsersmaynDesktopvcode工作區(qū)11路基.pdf’, pages=’200’, flavor=’stream’) camelot.plot(tables[0], kind=’text’) print(tables[0]) plt.show() # 繪制PDF文檔的坐標(biāo),定位表格所在的位置 #plt = camelot.plot(tables[0],kind=’text’) #plt.show() #table_df = tables[0].df#plotpdf() #i=3#output(i)for i in range(0,2): try: output(i) except Exception as e:print(’第’+str(i)+’頁(yè)沒(méi)找到表格啊啊啊’)pass continue
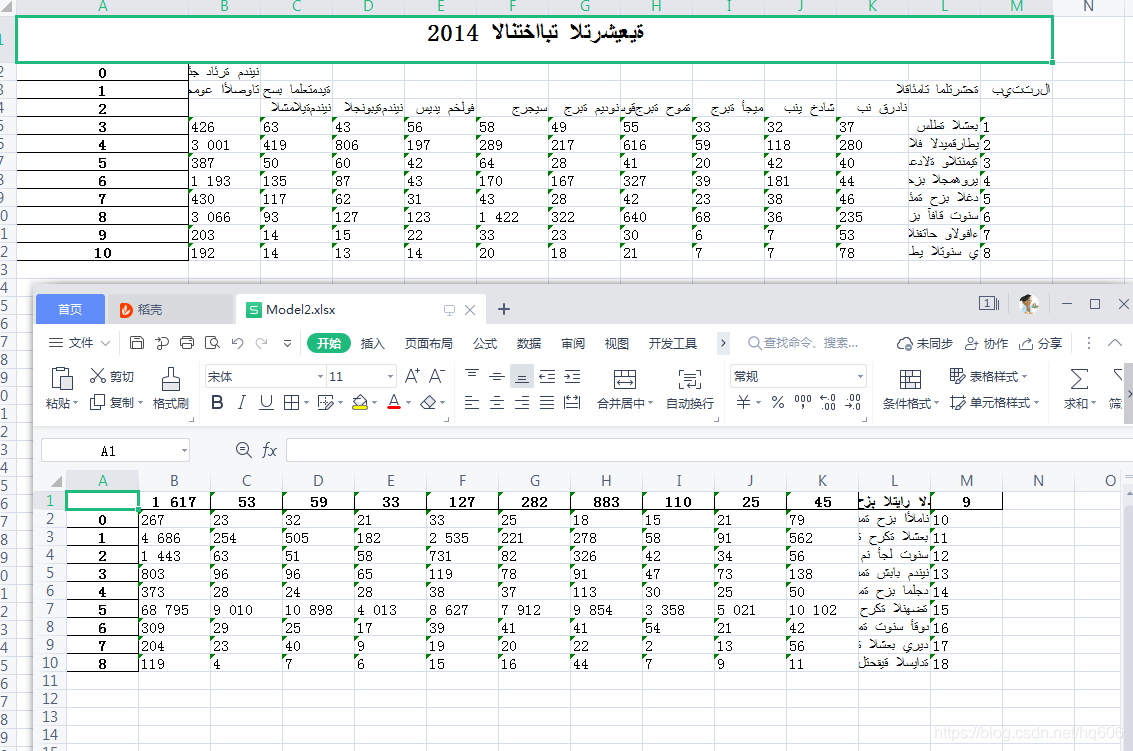
以下是pdfplumber測(cè)試效果
源文件如下

提取結(jié)果
最后補(bǔ)充2個(gè)免費(fèi)轉(zhuǎn)換的網(wǎng)站感覺(jué)還比較好用,關(guān)鍵是免費(fèi)
http://pdfdo.com/pdf-to-word.aspx
http://app.xunjiepdf.com/pdf2word/
到此這篇關(guān)于詳解用Python把PDF轉(zhuǎn)為Word方法總結(jié)的文章就介紹到這了,更多相關(guān)Python把PDF轉(zhuǎn)為Word內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. JavaWeb Servlet中url-pattern的使用2. jsp+servlet簡(jiǎn)單實(shí)現(xiàn)上傳文件功能(保存目錄改進(jìn))3. 淺談SpringMVC jsp前臺(tái)獲取參數(shù)的方式 EL表達(dá)式4. XML入門的常見問(wèn)題(四)5. HTML5 Canvas繪制圖形從入門到精通6. XML入門的常見問(wèn)題(一)7. XML解析錯(cuò)誤:未組織好 的解決辦法8. 微信開發(fā) 網(wǎng)頁(yè)授權(quán)獲取用戶基本信息9. javascript xml xsl取值及數(shù)據(jù)修改第1/2頁(yè)10. asp批量添加修改刪除操作示例代碼
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備