Python爬蟲基礎(chǔ)之requestes模塊
開始學(xué)習(xí)爬蟲,我們必須了解爬蟲的流程框架。在我看來爬蟲的流程大概就是三步,即不論我們爬取的是什么數(shù)據(jù),總是可以把爬蟲的流程歸納總結(jié)為這三步:
1.指定 url,可以簡單的理解為指定要爬取的網(wǎng)址
2.發(fā)送請求。requests 模塊的請求一般為 get 和 post
3.將爬取的數(shù)據(jù)存儲
二、requests模塊的導(dǎo)入因為 requests 模塊屬于外部庫,所以需要我們自己導(dǎo)入庫
導(dǎo)入的步驟:
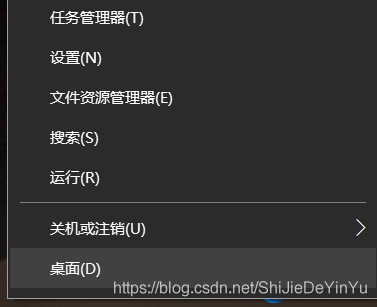
1.右鍵Windows圖標(biāo)
2.點擊“運行”
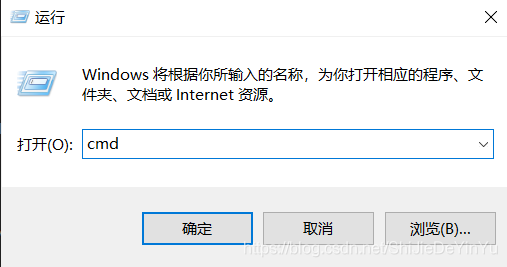
3.輸入“cmd”打開命令面板
4.輸入“pip install requests”,等待下載完成
如圖:

如果還是下載失敗,我的建議是百度一下,你就知道(我也是邊學(xué)邊寫,是在是水平有限)
歐克,既然導(dǎo)入成功后我們就簡單的來爬取一下搜狗的首頁吧!
三、完整代碼import requestsif __name__ == '__main__': # 指定url url = 'https://www.sougou.com/' # 發(fā)起請求 # get方法會返回一個響應(yīng)數(shù)據(jù) response = requests.get(url) # 獲取響應(yīng)數(shù)據(jù) page_txt = response.text # text返回一個字符串的響應(yīng)數(shù)據(jù) # print(page_txt) # 存儲 with open('./sougou.html', 'w', encoding = 'utf-8') as fp:fp.write(page_txt) print('爬取數(shù)據(jù)結(jié)束!!!')
我們打開保存的文件,如圖
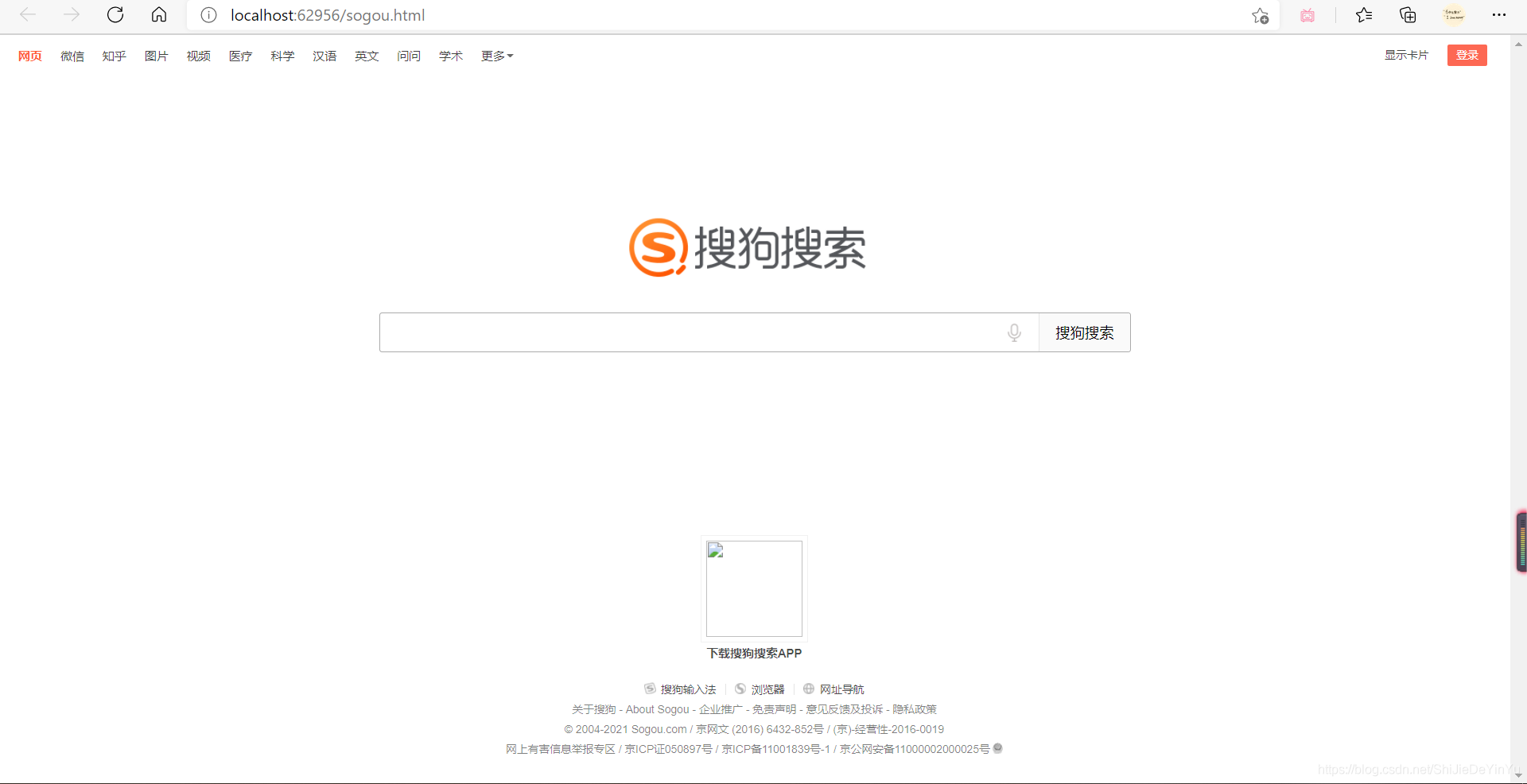
歐克,這就是最基本的爬取,如果學(xué)會了,那就試一試爬取 B站 的首頁吧。
到此這篇關(guān)于Python爬蟲基礎(chǔ)之requestes模塊的文章就介紹到這了,更多相關(guān)Python requestes模塊內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. CSS3實例分享之多重背景的實現(xiàn)(Multiple backgrounds)2. 使用Spry輕松將XML數(shù)據(jù)顯示到HTML頁的方法3. php網(wǎng)絡(luò)安全中命令執(zhí)行漏洞的產(chǎn)生及本質(zhì)探究4. XHTML 1.0:標(biāo)記新的開端5. ASP基礎(chǔ)知識VBScript基本元素講解6. 利用CSS3新特性創(chuàng)建透明邊框三角7. XML入門的常見問題(四)8. asp(vbscript)中自定義函數(shù)的默認(rèn)參數(shù)實現(xiàn)代碼9. 詳解CSS偽元素的妙用單標(biāo)簽之美10. HTML5 Canvas繪制圖形從入門到精通
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備