python 利用panda 實現(xiàn)列聯(lián)表(交叉表)
交叉表(cross-tabulation,簡稱crosstab)是⼀種⽤于計算分組頻率的特殊透視表。
語法詳解:
pd.crosstab(index, # 分組依據(jù) columns, # 列 values=None, # 聚合計算的值 rownames=None, # 列名稱 colnames=None, # 行名稱 aggfunc=None, # 聚合函數(shù) margins=False, # 總計行/列 dropna=True, # 是否刪除缺失值 normalize=False # )1 crosstab() 實例11.1 讀取數(shù)據(jù)
import osimport numpy as npimport pandas as pdfile_name = os.path.join(path, ’Excel_test.xls’)df = pd.read_excel(io=file_name, # 工作簿路徑 sheetname=’透視表’, # 工作表名稱 skiprows=1, # 要忽略的行數(shù) parse_cols=’A:D’ # 讀入的列 )df
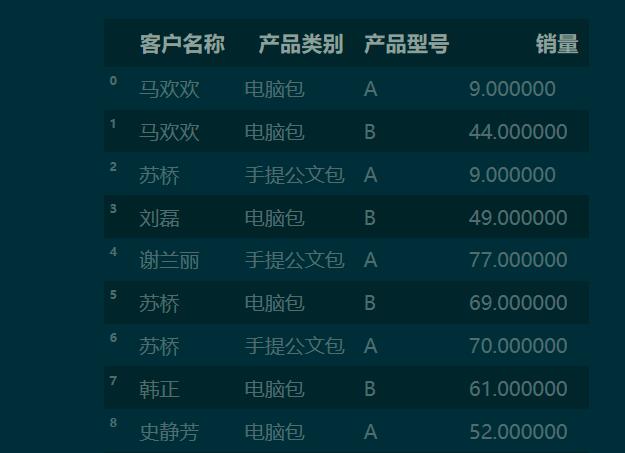
pd.crosstab(df[’客戶名稱’], df[’產(chǎn)品類別’])

pd.crosstab(index=df[’客戶名稱’], columns=df[’產(chǎn)品類別’], values=df[’銷量’], aggfunc=’sum’, margins=True ).round(0).fillna(0).astype(’int’)
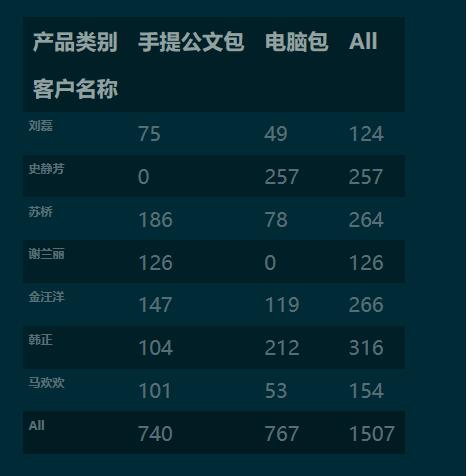
注:因為交叉表示透視表的特例,所以交叉表可以用透視表的函數(shù)實現(xiàn)。又因為透視表可以用更 python 的方式 groupby-apply 實現(xiàn),所以,交叉表完全可以用 groupby-apply 的方式實現(xiàn)。
2 用分類匯總的方法實現(xiàn) 交叉表df.groupby([’客戶名稱’, ’產(chǎn)品類別’]).apply(sum)
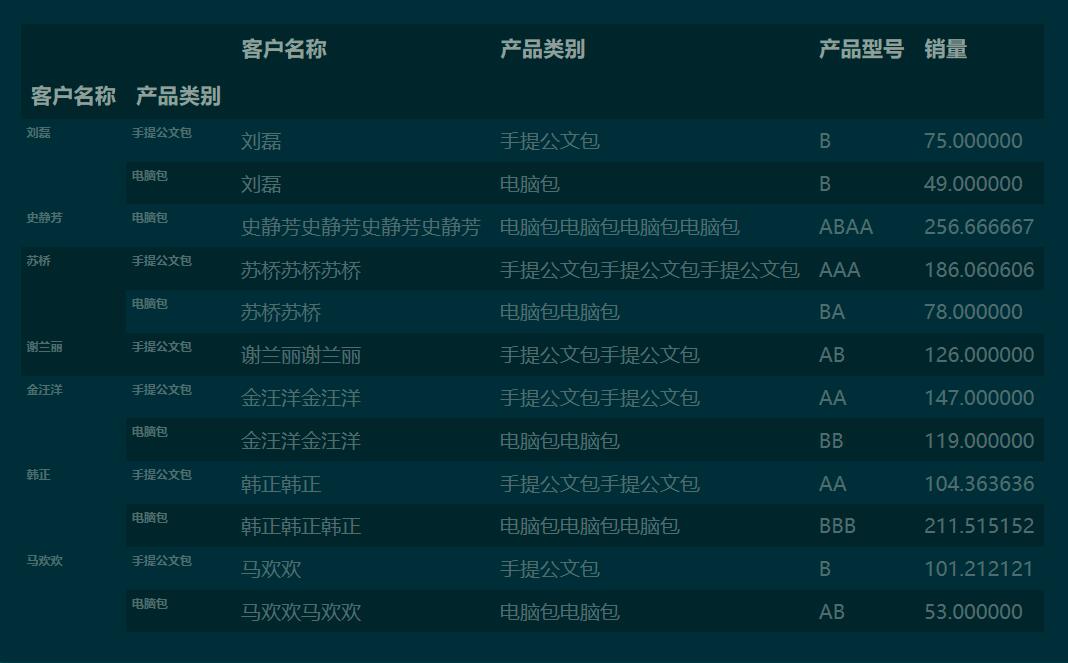
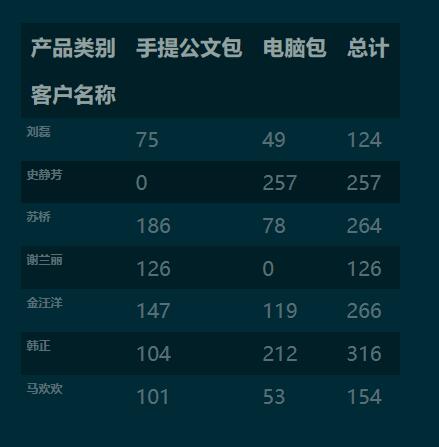
c_tbl = df.groupby([’客戶名稱’, ’產(chǎn)品類別’]).apply(sum)[’銷量’].unstack()c_tbl[’總計’] = c_tbl.sum(axis=1) # 添加總計列c_tbl.fillna(0).round(0).astype(’int’)
軟件信息:

補充:使用python(pandas)將數(shù)據(jù)處理成交叉分組表
交叉分組表是匯總兩種變量數(shù)據(jù)的方法, 在很多場景可以用到, 本文會介紹如何使用pandas將包含兩個變量的數(shù)據(jù)集處理成交叉分組表.
環(huán)境pandas
python 2.7
原理用坐標軸來進行比喻, 其中一個變量作為x軸, 另一個作為y軸, 如果定位到數(shù)據(jù)則累加一, 將所有數(shù)據(jù)遍歷一遍, 最后的坐標軸就是一張交叉分組表(使用坐標軸展示的數(shù)據(jù)一般是連續(xù)的, 交叉分組表的數(shù)據(jù)是離散的).
具體實現(xiàn)示例數(shù)據(jù):
quality price0 bad 181 bad 172 great 523 good 284 excellent 885 great 636 bad 87 good 228 good 689 excellent 9810 great 5311 bad 1312 great 6213 good 4814 excellent 7815 great 6316 good 3717 great 6918 good 2819 excellent 8120 great 4321 good 3222 great 6223 good 2824 excellent 8225 great 53
代碼:
import pandas as pd from pandas import DataFrame, Series #生成數(shù)據(jù) df = DataFrame([[’bad’, 18], [’bad’, 17], [’great’, 52], [’good’, 28], [’excellent’, 88], [’great’, 63], [’bad’, 8], [’good’, 22], [’good’, 68], [’excellent’, 98], [’great’, 53], [’bad’, 13], [’great’, 62], [’good’, 48], [’excellent’, 78], [’great’, 63], [’good’, 37], [’great’, 69], [’good’, 28], [’excellent’, 81], [’great’, 43], [’good’, 32], [’great’, 62], [’good’, 28], [’excellent’, 82], [’great’, 53]], columns = [’quality’, ’price’])#廣播使用的函數(shù)def quality_cut(data): s = Series(pd.cut(data[’price’], np.arange(0, 100, 10))) return pd.groupby(s, s).count()#進行分組處理df.groupby(df[’quality’]).apply(quality_cut)
結(jié)果:
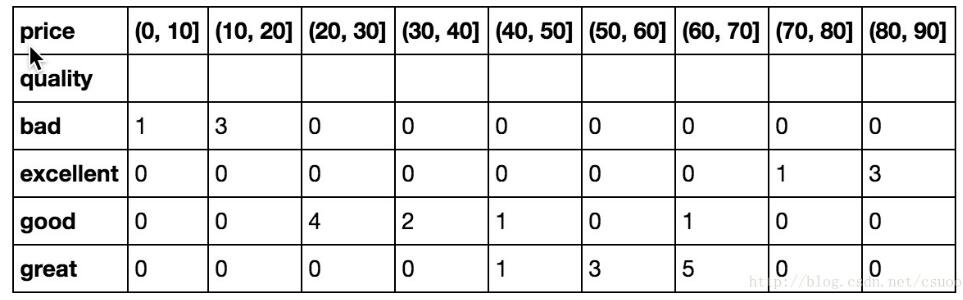
交叉分組
詳細分析從邏輯上來看, 為了達到對示例數(shù)據(jù)的交叉分組, 需要完成以下工作:
將數(shù)據(jù)以quality列進行分組.
將每個分組的數(shù)據(jù)分別進行cut, 以10為間隔.
將cut過的數(shù)據(jù), 以cut的范圍為列進行分組
將所有數(shù)據(jù)組合到一起, row為quality, columns為cut的范圍
步驟1, pandasgroupby(...)接口, 會按照指定的列進行分組處理, 每一個分組, 存儲相同類別的數(shù)據(jù)
<class ’pandas.core.frame.DataFrame’> quality price0 bad 181 bad 176 bad 811 bad 13
而我們需要的, 只是price這列的數(shù)據(jù), 所以單獨將這列拿出來, 進行cut, 最后得到我們要的series(步驟2, 步驟3)
price(0, 10] 1(10, 20] 3(20, 30] 0(30, 40] 0(40, 50] 0(50, 60] 0(60, 70] 0(70, 80] 0(80, 90] 0
使用pandas
apply()的廣播特性, 每一個分組的數(shù)據(jù)都會經(jīng)過上述幾個步驟的處理, 最后與第一次分組row進行組合.
后記估計能力有限, 這個問題想了很長時間, 沒想到pandas這么可以這么方便達成交叉分組的效果. 思考的時候主要是卡在數(shù)據(jù)組合上, 當數(shù)據(jù)量很大時通過多個步驟進行數(shù)據(jù)組合, 肯定是低效而且錯誤的. 最后仔細研究了groupby, dataframe, series, dataframeIndex等數(shù)據(jù)模型, 使用廣播特性用幾句代碼就完成了. 證明了pandas的高性能, 也提醒自己遇見問題一定要耐心分析。
以上為個人經(jīng)驗,希望能給大家一個參考,也希望大家多多支持好吧啦網(wǎng)。如有錯誤或未考慮完全的地方,望不吝賜教。
相關(guān)文章:
1. 用xslt+css讓RSS顯示的跟網(wǎng)頁一樣漂亮2. 利用CSS制作3D動畫3. CSS3實現(xiàn)動態(tài)翻牌效果 仿百度貼吧3D翻牌一次動畫特效4. 使用Spry輕松將XML數(shù)據(jù)顯示到HTML頁的方法5. 存儲于xml中需要的HTML轉(zhuǎn)義代碼6. HTML5 Canvas繪制圖形從入門到精通7. 讀大數(shù)據(jù)量的XML文件的讀取問題8. html5手機觸屏touch事件介紹9. 讓chatgpt將html中的圖片轉(zhuǎn)為base64方法示例10. 《CSS3實戰(zhàn)》筆記--漸變設(shè)計(一)

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備