利于python腳本編寫可視化nmap和masscan的方法
我編寫了一個快速且?guī)в邪唿c的python腳本,以可視化nmap和masscan的結(jié)果。它通過解析來自掃描的XML日志并生成所掃描IP范圍的直觀表示來工作。以下屏幕截圖是輸出示例:
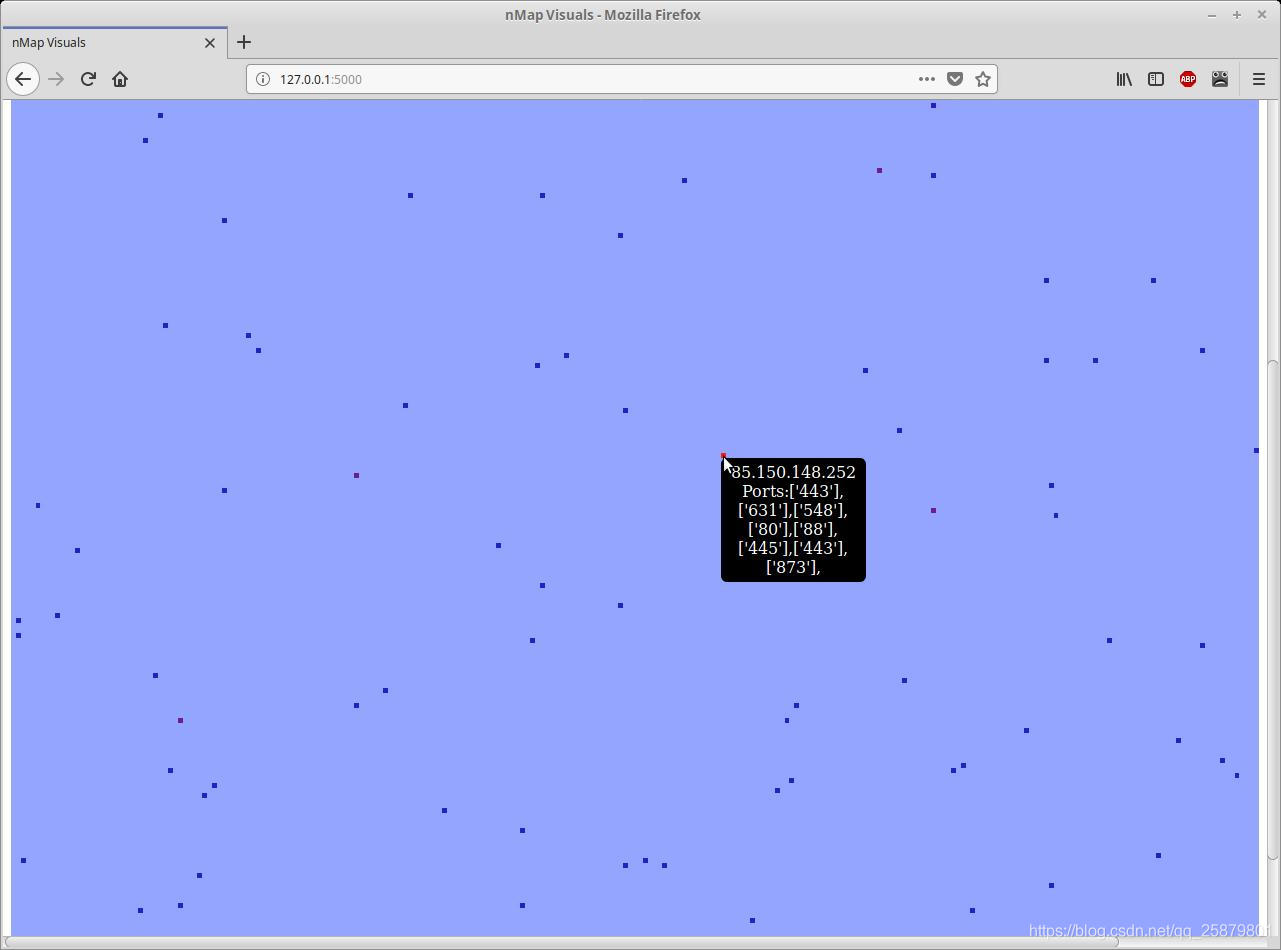
由于缺少更好的詞,我將從現(xiàn)在開始將輸出稱為地圖。每個主機(jī)由一個彩色正方形表示。覆蓋地圖大部分內(nèi)容的淺藍(lán)色方塊表示主機(jī)處于脫機(jī)狀態(tài)(或僅未響應(yīng)masscan的SYN。)其他彩色方塊表示處于聯(lián)機(jī)狀態(tài)且具有開放端口的主機(jī)。正方形的顏色從藍(lán)色到紅色。正方形越紅,表示主機(jī)上打開的端口越多。將鼠標(biāo)懸停在每個方塊上,將在工具提示中顯示IP地址和打開的端口。
該工具非常有用,因為它使您可以大致了解IP范圍,而不必在日志文件中拖網(wǎng)。它使您可以輕松查看掃描中的主機(jī)塊。該工具可以從github下載,但是我將在下面描述代碼的工作方式。
如何使用首先,我要說這段代碼沒有經(jīng)過優(yōu)化。我已經(jīng)針對/ 21的日志運行了代碼,并花費了大約40秒鐘來生成輸出映射。
第一步是查找運行掃描的IP地址范圍。由于掃描命令未保存在日志文件中,因此這真是一個痛苦。因此,我們必須根據(jù)最低和最高IP結(jié)果來計算范圍。我們從掃描中解析XML文件,并將掃描到的每個IP地址附加到名為ipList的列表中
ipList = []for event, element in etree.iterparse(’output.xml’, tag='host'): for child in element: if child.tag == ’address’: ipList.append(child.attrib[’addr’])
然后,我們遍歷ipList并將每個八位位組分成單獨的列表,分別稱為firstOctetRange,secondOctetRange,thirdOctetRang和forwardOctetRange。
firstOctetRange = []secondOctetRange = []thirdOctetRange = []forthOctetRange = []bitDelimeter = 0startingIP = 0endingIP = 0for ip in ipList: binaryOctet = ’’ octets = ip.split(’.’) firstOctetRange.append(int(octets[0])) secondOctetRange.append(int(octets[1])) thirdOctetRange.append(int(octets[2])) forthOctetRange.append(int(octets[3]))
然后,我們將每個結(jié)果的每個八位位組與另一個結(jié)果的相同八位位組進(jìn)行比較,以確定值發(fā)生變化的八位位組。例如。如果前兩個八位位組始終相同。我們知道掃描的CIDR表示法將大于/ 16。我使用了變量bitDelimeter來存儲CIDR表示法截取的八位字節(jié)的值。
if min(firstOctetRange) != max(firstOctetRange): bitDelimeter = 0elif min(secondOctetRange) != max(secondOctetRange): bitDelimeter = 1elif min(thirdOctetRange) != max(thirdOctetRange): bitDelimeter = 2elif min(forthOctetRange) != max(forthOctetRange): bitDelimeter = 3
掃描的IP地址范圍被添加到稱為parsedServers的有序字典中。ip地址是使用一系列4個嵌套的FOR循環(huán)生成的,每個循環(huán)在0 ? 256范圍內(nèi)循環(huán)。此范圍開始的八位位組取決于bitDelimeter。例如。如果掃描了IP地址范圍192.168.10.0/24。位定界符將為3,指示最后一個八位位組是更改其值的八位位組。因此,用于生成要放入parsedServers的IP地址的循環(huán)將固定前三個八位字節(jié),并僅對最后一個八位字節(jié)循環(huán)范圍為0 ? 256。如果我們掃描/ 21,則位定界符將為2,因此生成IP地址的循環(huán)將固定前兩個八位位組。將根據(jù)掃描的最小第三八位字節(jié)值和掃描的最大第三八位字節(jié)值的范圍生成第三八位字節(jié)。第四個八位位組的范圍是0 ? 256。
if bitDelimeter == 0: for one in range(min(firstOctetRange), max(firstOctetRange) + 1): for two in range(0, 256): for three in range(0, 256): for four in range(0, 256): ip = '%d.%d.%d.%d' % (one, two, three, four) parsedServers[ip] = []if bitDelimeter == 1: one = min(firstOctetRange) for two in range(min(secondOctetRange), max(secondOctetRange) + 1): for three in range(0, 256): for four in range(0, 256): ip = '%d.%d.%d.%d' % (one, two, three, four) parsedServers[ip] = []if bitDelimeter == 2: one = min(firstOctetRange) two = min(secondOctetRange) for three in range(min(thirdOctetRange), max(thirdOctetRange) + 1): for four in range(0, 256): ip = '%d.%d.%d.%d' % (one, two, three, four) parsedServers[ip] = []if bitDelimeter == 3: one = min(firstOctetRange) two = min(secondOctetRange) three = min(thirdOctetRange) for four in range(min(forthOctetRange), max(forthOctetRange) + 1): ip = '%d.%d.%d.%d' % (one, two, three, four) parsedServers[ip] = []
現(xiàn)在,我們有一個parsedServer排序的dict,其中包含我們掃描范圍內(nèi)的所有IP地址。下一步是將掃描中找到的打開端口添加到parsedServer字典中。
for event, element in etree.iterparse(’output.xml’, tag='host'): for child in element: if child.tag == ’address’: ipAddress = child.attrib[’addr’] if child.tag == ’ports’: for subChild in child: port = [subChild.attrib[’portid’]] parsedServers[ipAddress].append(port)
現(xiàn)在,我們需要生成一個HTML頁面,可用于可視化結(jié)果。這是使用Flask完成的。我們遍歷包含所有數(shù)據(jù)的pasedServers字典。創(chuàng)建一個infoString,其中包含當(dāng)前迭代的IP地址和端口。當(dāng)光標(biāo)懸停在地圖上的正方形上時,將在工具提示中使用此功能。創(chuàng)建htmlBuffer并將其附加到parsedServers字典的每次迭代中。每次迭代都會添加HTML代碼,以使用從colourRange列表中提取的顏色添加新的表格數(shù)據(jù)單元。范圍中總地址的平方根表示何時需要在表中添加新行。這樣可以使結(jié)果在頁面上顯示為正方形。
count = 0htmlBuffer = Markup(’’)for key, value in parsedServers.items(): infoString = str(key) + ’<br>’ if value: infoString += ’Ports:’ for portValue in value: infoString += str(portValue) + ’,’ colourRange = [’94A5FF’, ’0024E5’, ’2422C5’, ’4821A6’, ’6D1F87’, ’911E67’, ’B61C48’, ’DA1B29’, ’FF1A0A’] htmlBuffer += Markup(’<td class='tooltip', bgcolor='’ + colourRange[len(value)] + ’'><span class='tooltiptext'>’ + infoString + ’</span></td>’)<br> count += 1<br> if count > math.sqrt(len(parsedServers)):<br> htmlBuffer += Markup(’</tr><tr>’) count = 0
例如。我們正在parsedServers中進(jìn)行迭代,地址為192.168.10.22,并且打開了3個端口。將使用工具提示中列出的IP地址和端口創(chuàng)建一個表格數(shù)據(jù)單元。單元格的背景顏色將從包含9個十六進(jìn)制顏色代碼的colourRange列表中提取。列表上的索引越高,顏色越紅色。在此示例中,IP地址有3個開放的端口。因此,第三個索引中的顏色將設(shè)置為背景色,從而使數(shù)據(jù)單元格變?yōu)樽仙?/p>
最后,我們將模板傳遞給htmlBuffer。然后運行Web服務(wù)器。通過瀏覽至127.0.0.1:5000,可以找到輸出。
@app.route(’/’)def index(): return render_template(’index.html’, name=htmlBuffer)if __name__ == ’__main__’: app.run()
到此這篇關(guān)于利于python腳本編寫可視化nmap和masscan的文章就介紹到這了,更多相關(guān)python編寫可視化nmap和masscan內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 使用Python和百度語音識別生成視頻字幕的實現(xiàn)2. css代碼優(yōu)化的12個技巧3. CSS可以做的幾個令你嘆為觀止的實例分享4. msxml3.dll 錯誤 800c0019 系統(tǒng)錯誤:-2146697191解決方法5. 利用ajax+php實現(xiàn)商品價格計算6. xml中的空格之完全解說7. Vue的Options用法說明8. axios和ajax的區(qū)別點總結(jié)9. 怎樣才能用js生成xmldom對象,并且在firefox中也實現(xiàn)xml數(shù)據(jù)島?10. ASP刪除img標(biāo)簽的style屬性只保留src的正則函數(shù)

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備