Python 爬蟲批量爬取網頁圖片保存到本地的實現代碼
其實和爬取普通數據本質一樣,不過我們直接爬取數據會直接返回,爬取圖片需要處理成二進制數據保存成圖片格式(.jpg,.png等)的數據文本。
現在貼一個url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg請復制上面的url直接在某個瀏覽器打開,你會看到如下內容:
這就是通過網頁訪問到的該網站的該圖片,于是我們可以直接利用requests模塊,進行這個圖片的請求,于是這個網站便會返回給我們該圖片的數據,我們再把數據寫入本地文件就行,比較簡單。
import requestsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg’re=requests.get(url,headers=headers)print(re.status_code)#查看請求狀態,返回200說明正常path=’test.jpg’#文件儲存地址with open(path, ’wb’) as f:#把圖片數據寫入本地,wb表示二進制儲存 for chunk in re.iter_content(chunk_size=128):f.write(chunk)
然后得到test.jpg圖片,如下

點擊打開查看如下:
便是下載成功辣,很簡單吧。
現在分析下批量下載,我們將上面的代碼打包成一個函數,于是針對每張圖片,單獨一個名字,單獨一個圖片文件請求,于是有如下代碼:
import requestsdef get_pictures(url,path): headers={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’} re=requests.get(url,headers=headers) print(re.status_code)#查看請求狀態,返回200說明正常 with open(path, ’wb’) as f:#把圖片數據寫入本地,wb表示二進制儲存for chunk in re.iter_content(chunk_size=128): f.write(chunk)url=’https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg’path=’test.jpg’#文件儲存地址get_pictures(url,path)
現在要實現批量下載圖片,也就是批量獲得圖片的url,那么我們就得分析網頁的代碼結構,打開原始網站https://www.ivsky.com/tupian/bianxingjingang_v622/,會看到如下的圖片:
于是我們需要分別得到該頁面中顯示的所有圖片的url,于是我們再次用requests模塊返回當前該頁面的內容,如下:
import requestsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://www.ivsky.com/tupian/bianxingjingang_v622/’re=requests.get(url,headers=headers)print(re.text)
運行會返回當前該頁面的網頁結構內容,于是我們找到和圖片相關的也就是.jpg或者.png等圖片格式的字條,如下:

上面圈出來的**//img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-017.jpg**便是我們的圖片url,不過還需要前面加上https:,于是完成的url就是https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-017.jpg。
我們知道了這個結構,現在就是把這個提取出來,寫個簡單的解析式:
import requestsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://www.ivsky.com/tupian/bianxingjingang_v622/’re=requests.get(url,headers=headers)def get_pictures_urls(text): st=’img src='http://www.aoyou183.cn/bcjs/’ m=len(st) i=0 n=len(text) urls=[]#儲存url while i<n: if text[i:i+m]==st: url=’’ for j in range(i+m,n):if text[j]==’'’: i=j urls.append(url) breakurl+=text[j] i+=1 return urlsurls=get_pictures_urls(re.text)for url in urls: print(url)
打印結果如下: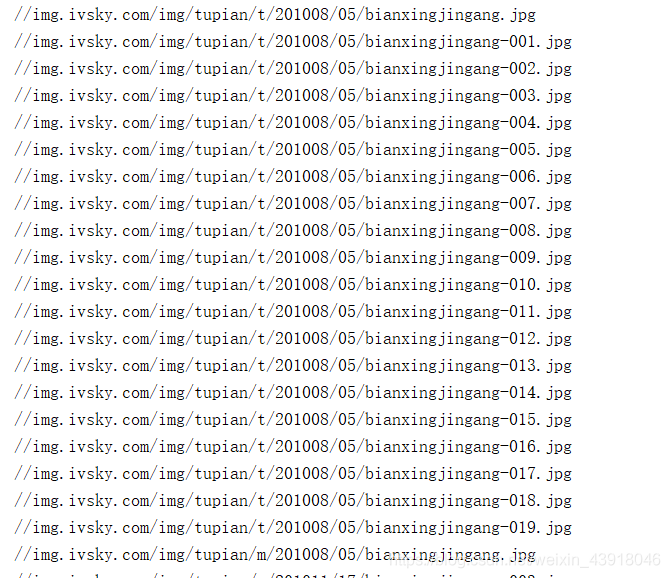
得到了url,現在就直接放入一開始的get_pictures函數中,爬取圖片辣。
import requestsdef get_pictures(url,path): headers={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’} re=requests.get(url,headers=headers) print(re.status_code)#查看請求狀態,返回200說明正常 with open(path, ’wb’) as f:#把圖片數據寫入本地,wb表示二進制儲存for chunk in re.iter_content(chunk_size=128): f.write(chunk)def get_pictures_urls(text): st=’img src='http://www.aoyou183.cn/bcjs/’ m=len(st) i=0 n=len(text) urls=[]#儲存url while i<n: if text[i:i+m]==st: url=’’ for j in range(i+m,n):if text[j]==’'’: i=j urls.append(url) breakurl+=text[j] i+=1 return urlsheaders={ ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400’}url=’https://www.ivsky.com/tupian/bianxingjingang_v622/’re=requests.get(url,headers=headers)urls=get_pictures_urls(re.text)#獲取當前頁面所有圖片的urlfor i in range(len(urls)):#批量爬取圖片 url=’https:’+urls[i] path=’變形金剛’+str(i)+’.jpg’ get_pictures(url,path)
結果如下:
然后就完成辣,這里只是簡單介紹下批量爬取圖片的過程,具體的網站需要具體分析,所以本文盡可能詳細的展示了批量爬取圖片的過程分析,希望對你的學習有所幫助,如有問題請及時指出,謝謝~
到此這篇關于Python 爬蟲批量爬取網頁圖片保存到本地的文章就介紹到這了,更多相關Python 爬蟲爬取圖片保存到本地內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備