基于Python爬取搜狐證券股票過程解析
數(shù)據(jù)的爬取
我們以上證50的股票為例,首先需要找到一個網(wǎng)站包含這五十只股票的股票代碼,例如這里我們使用搜狐證券提供的列表。
https://q.stock.sohu.com/cn/bk_4272.shtml

可以看到,在這個網(wǎng)站中有上證50的所有股票代碼,我們希望爬取的就是這個包含股票代碼的表,并獲取這個表的第一列。
爬取網(wǎng)站的數(shù)據(jù)我們使用Beautiful Soup這個工具包,需要注意的是,一般只能爬取到靜態(tài)網(wǎng)頁中的信息。
簡單來說,Beautiful Soup是Python的一個庫,最主要的功能是從網(wǎng)頁抓取數(shù)據(jù)。
像往常一樣,使用這個庫之前,我們需要先導入該庫bs4。除此之外,我們還需要使用requests這個工具獲取網(wǎng)站信息,因此導入這兩個庫:
import bs4 as bs
import requests
我們定義一個函數(shù)saveSS50Tickers() 來實現(xiàn)上證50股票代碼的獲取,獲取的數(shù)據(jù)來自于搜狐證券的網(wǎng)頁,使用 get() 方法獲取給定靜態(tài)網(wǎng)頁的數(shù)據(jù)。
def saveSS50Tickers():resp = requests.get(’https://q.stock.sohu.com/cn/bk_4272.shtml’)
接下來我們打開搜狐證券的這個網(wǎng)址,在頁面任意位置右鍵選擇查看元素,或者Inspect Element,或者類似的選項來查看當前網(wǎng)站的源代碼信息。
我們需要先在這里找出網(wǎng)頁的一些基本信息和我們需要爬取的數(shù)據(jù)的特征。
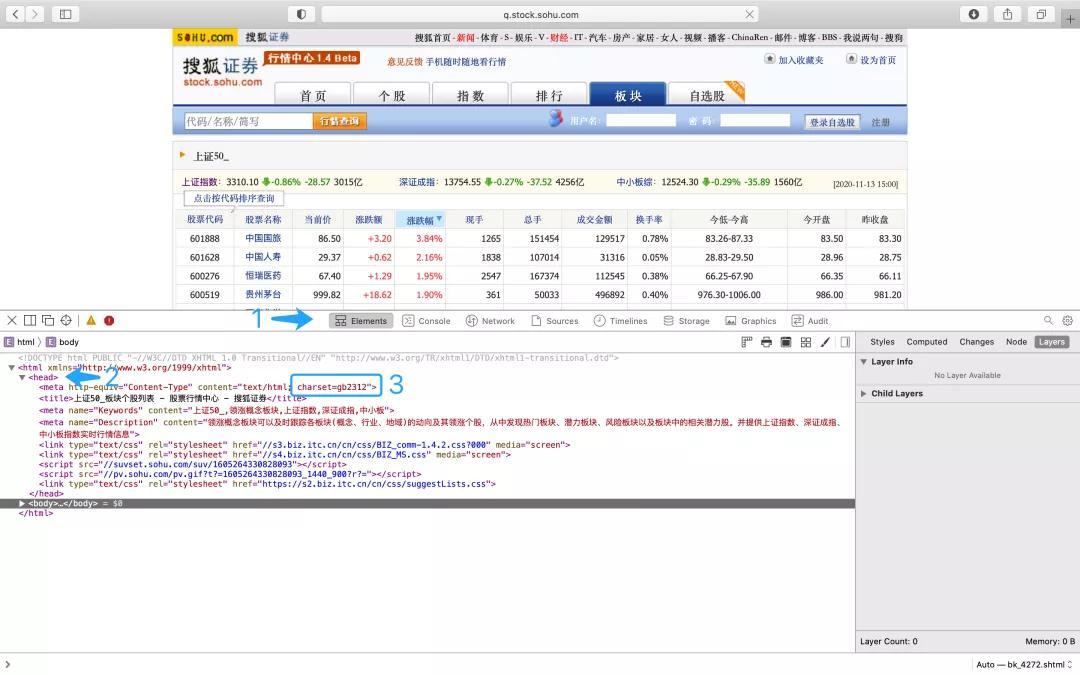
首先,找到Element,在下面的內(nèi)容中找到網(wǎng)頁的頭文件 (head)。然后找到網(wǎng)頁的文字的編碼方式。這里這個網(wǎng)頁文字的編碼方式是gb2312。
如果我們想爬取并正確顯示這個網(wǎng)頁上,就需要先對獲取到的網(wǎng)頁內(nèi)容解碼。
解碼可以使用 encoding 這個方法:
resp.encoding = ’gb2312’
接下來使用 BeautifulSoup 和lxml解析網(wǎng)頁信息:
soup = bs.BeautifulSoup(resp.text, ’lxml’)
這里為了方便后期的處理,首先使用 resp.text 將網(wǎng)頁信息轉(zhuǎn)成了文本格式,然后再解析網(wǎng)頁的數(shù)據(jù)。
接下來我們需要在網(wǎng)頁的源碼中找到需要爬取信息的標簽,這里我們需要爬取這個表格中的信息,首先,可以通過網(wǎng)站源碼的搜索功能搜索表格里的相關(guān)數(shù)據(jù)定位到表格的源碼。
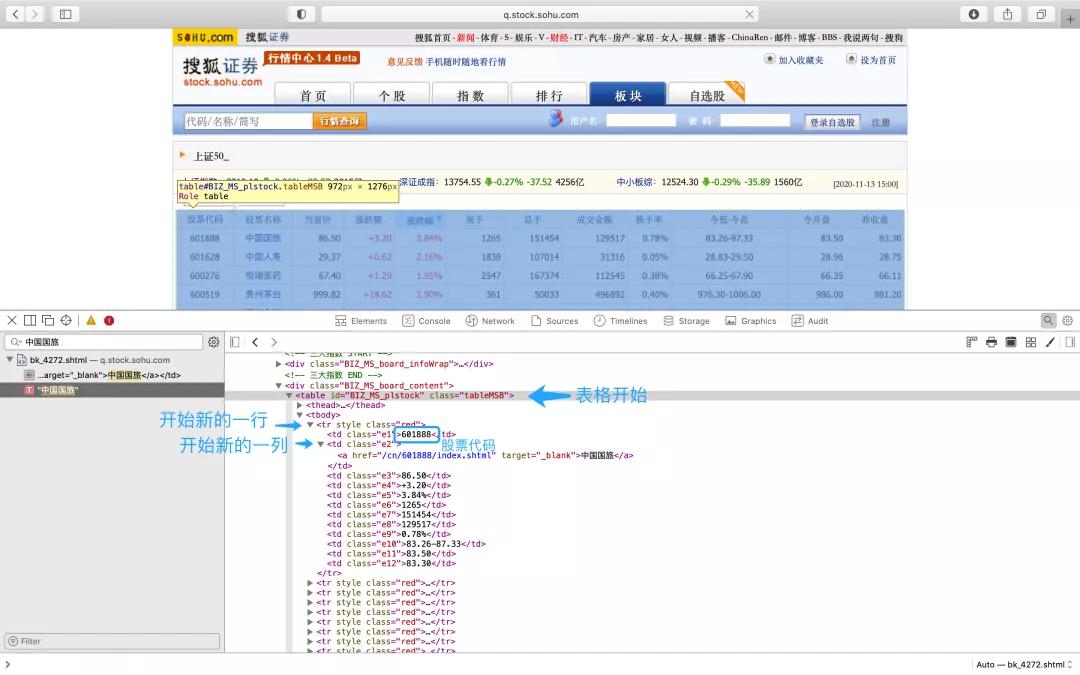
同樣以這個頁面為例,一般網(wǎng)頁使用HTML語言編譯的,因為要準確定位,我們需要了解一些 HTML 語言的基礎(chǔ)內(nèi)容。在這個頁面的源碼中,

<table表示表格開始,后面是這個表格的一些屬性。</table>表示表格結(jié)束。
首先,我們使用 soup.find 在網(wǎng)頁信息中找到這個表格標簽的入口:
table = soup.find(’table’, {’id’: ’BIZ_MS_plstock’})
其中’table’表示這里需要找到一個表格,{’id’:’BIZ_MS_plstock’} 則是通過內(nèi)容或者屬性實現(xiàn)表格的進一步定位。
找到表格的位置之后,我們需要繼續(xù)查找需要的數(shù)據(jù),同樣以這個頁面為例:
在網(wǎng)頁開發(fā)語言中,
<tr表示表格中開始新的一行,<td表示在這一行中又新建了一列,而</td>則表示這一列結(jié)束了,對應(yīng)的</tr>則表示這一行結(jié)束了。
通過該網(wǎng)頁的源碼,我們可以發(fā)現(xiàn),
表格的第一行和第二行都是表頭的信息,第三行開始是五十家公司的股票信息。另外每家公司的股票代碼在表格的第一列位置。
因為,在Python中,我們需要從表格的第三行開始抓取,每行抓取表格的第一列的數(shù)據(jù),將抓取到的數(shù)據(jù)轉(zhuǎn)換成文本格式,我們用一個列表 tickers 來存儲抓取到的數(shù)據(jù):
tickers = []for row in table.findAll(’tr’)[2:]:ticker = row.findAll(’td’)[0].texttickers.append(ticker + ’.SS’)
因此為了方便后續(xù)進行數(shù)據(jù)處理,這里我們存儲上證50的每家公司的股票代碼時,都在代碼后面再添加’.SS’的字符。這時我們運行目前的代碼,并將列表tickers輸出:
# 導入 beautiful soup4 包,用于抓取網(wǎng)頁信息import bs4 as bs# 導入 pickle 用于序列化對象import pickle# 導入 request 用于獲取網(wǎng)站上的源碼import requestsdef saveSS50Tickers(): resp = requests.get(’https://q.stock.sohu.com/cn/bk_4272.shtml’) resp.encoding = ’gb2312’ soup = bs.BeautifulSoup(resp.text, ’lxml’) # print(soup) table = soup.find(’table’, {’id’: ’BIZ_MS_plstock’}) # print(table) tickers = [] # print(table.find_all(’tr’)) for row in table.findAll(’tr’)[2:]: # print(row) ticker = row.findAll(’td’)[0].text tickers.append(ticker + ’.SS’) return tickerstickers = saveSS50Tickers()print(tickers)
觀察到輸出信息如下:
[’600036.SS’, ’601229.SS’, ’600031.SS’, ’601166.SS’, ’600104.SS’, ’600030.SS’, ’603259.SS’, ’601668.SS’, ’601628.SS’, ’601766.SS’, ’601857.SS’, ’601398.SS’, ’601390.SS’, ’600029.SS’, ’600028.SS’, ’601818.SS’, ’601211.SS’, ’601066.SS’, ’601111.SS’, ’600837.SS’, ’600887.SS’, ’601888.SS’, ’600690.SS’, ’600519.SS’, ’600016.SS’, ’601989.SS’, ’601988.SS’, ’601601.SS’, ’600019.SS’, ’601186.SS’, ’600703.SS’, ’600196.SS’, ’601318.SS’, ’601800.SS’, ’600050.SS’, ’601319.SS’, ’601288.SS’, ’601688.SS’, ’603993.SS’, ’600309.SS’, ’600048.SS’, ’600276.SS’, ’601138.SS’, ’601336.SS’, ’601088.SS’, ’600585.SS’, ’600000.SS’, ’601328.SS’, ’601939.SS’, ’600340.SS’]
這樣我們就從搜狐證券這個網(wǎng)站上爬取到了上證50的公司股票代碼,并將其以字符串的格式存放在了一個列表變量中。
將股票代碼保存到本地
一般像股票代碼這種內(nèi)容,短時間內(nèi)不會有很大的變動,所以我們也不需要每次使用時重新爬取,一種方便的做法是可以將股票代碼信息以文件的格式保存到本地,需要使用時直接從本地讀取就可以了。
這里我們將股票代碼數(shù)據(jù)保存為pickle格式。pickle 格式的數(shù)據(jù)可以在 Python 中高效的存取,當然,將文件導出成該格式前需要先導入相應(yīng)的pickle 庫:
import pickle
pickle可以保存任何數(shù)據(jù)格式的數(shù)據(jù),在經(jīng)常存取的場景(保存和恢復狀態(tài))下讀取更加高效。
把文件導出成pickle格式的方法是 pickle.dump,同時需要結(jié)合文件讀寫操作:
with open(’SS50tickers.pickle’, ’wb’) as f: pickle.dump(tickers, f)
這里的’SS50tickers.pickle’就是保存的文件的名稱,’wb’則表示向文件中寫入數(shù)據(jù)。pickle.dump(tickers, f) 表示將列表tickers寫入到文件中。
以上就是本文的全部內(nèi)容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. ASP基礎(chǔ)知識VBScript基本元素講解2. Python requests庫參數(shù)提交的注意事項總結(jié)3. IntelliJ IDEA導入jar包的方法4. ajax請求添加自定義header參數(shù)代碼5. Kotlin + Flow 實現(xiàn)Android 應(yīng)用初始化任務(wù)啟動庫6. vue-electron中修改表格內(nèi)容并修改樣式7. 詳談ajax返回數(shù)據(jù)成功 卻進入error的方法8. 使用Python和百度語音識別生成視頻字幕的實現(xiàn)9. 使用python 計算百分位數(shù)實現(xiàn)數(shù)據(jù)分箱代碼10. python操作mysql、excel、pdf的示例

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備