Python爬蟲使用bs4方法實現數據解析
聚焦爬蟲:
爬取頁面中指定的頁面內容。
編碼流程:
1.指定url 2.發起請求 3.獲取響應數據 4.數據解析 5.持久化存儲數據解析分類:
1.bs4 2.正則 3.xpath (***)數據解析原理概述:
解析的局部的文本內容都會在標簽之間或者標簽對應的屬性中進行存儲
1.進行指定標簽的定位
2.標簽或者標簽對應的屬性中存儲的數據值進行提取(解析)
bs4進行數據解析數據解析的原理:
1.標簽定位
2.提取標簽、標簽屬性中存儲的數據值
bs4數據解析的原理:
1.實例化一個BeautifulSoup對象,并且將頁面源碼數據加載到該對象中
2.通過調用BeautifulSoup對象中相關的屬性或者方法進行標簽定位和數據提取
環境安裝:
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
實例化BeautifulSoup對象步驟:
from bs4 import BeautifulSoup
對象的實例化:
1.將本地的html文檔中的數據加載到該對象中
fp = open(’./test.html’,’r’,encoding=’utf-8’)soup = BeautifulSoup(fp,’lxml’)
2.將互聯網上獲取的頁面源碼加載到該對象中(常用方法,推薦)
page_text = response.textsoup = BeatifulSoup(page_text,’lxml’)
提供的用于數據解析的方法和屬性:
soup.tagName:返回的是文檔中第一次出現的tagName對應的標簽soup.find():find(’tagName’):等同于soup.div
1.屬性定位:
soup.find(’div’,class_/id/attr=’song’)soup.find_all(’tagName’):返回符合要求的所有標簽(列表)select:select(’某種選擇器(id,class,標簽...選擇器)’),返回的是一個列表。
2.層級選擇器:
soup.select(’.tang > ul > li > a’):>表示的是一個層級soup.select(’.tang > ul a’):空格表示的多個層級
3.獲取標簽之間的文本數據:
soup.a.text/string/get_text()text/get_text():可以獲取某一個標簽中所有的文本內容string:只可以獲取該標簽下面直系的文本內容
4.獲取標簽中屬性值:
soup.a[’href’]
案例:爬取三國演義小說所有的章節標題和章節內容代碼如下:
import requestsfrom bs4 import BeautifulSoupif __name__ == '__main__': #對首頁的頁面數據進行爬取 headers = { ’User-Agent’: ’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’ } url = ’http://www.shicimingju.com/book/sanguoyanyi.html’ page_text = requests.get(url=url,headers=headers).text #在首頁中解析出章節的標題和詳情頁的url #實例化BeautifulSoup對象,需要將頁面源碼數據加載到該對象中 soup = BeautifulSoup(page_text,’lxml’) #解析章節標題和詳情頁的url li_list = soup.select(’.book-mulu > ul > li’) fp = open(’./sanguo.txt’,’w’,encoding=’utf-8’) for li in li_list: title = li.a.string detail_url = ’http://www.shicimingju.com’+li.a[’href’] #對詳情頁發起請求,解析出章節內容 detail_page_text = requests.get(url=detail_url,headers=headers).text #解析出詳情頁中相關的章節內容 detail_soup = BeautifulSoup(detail_page_text,’lxml’) div_tag = detail_soup.find(’div’,class_=’chapter_content’) #解析到了章節的內容 content = div_tag.text fp.write(title+’:’+content+’n’) print(title,’爬取成功!!!’)
運行結果:
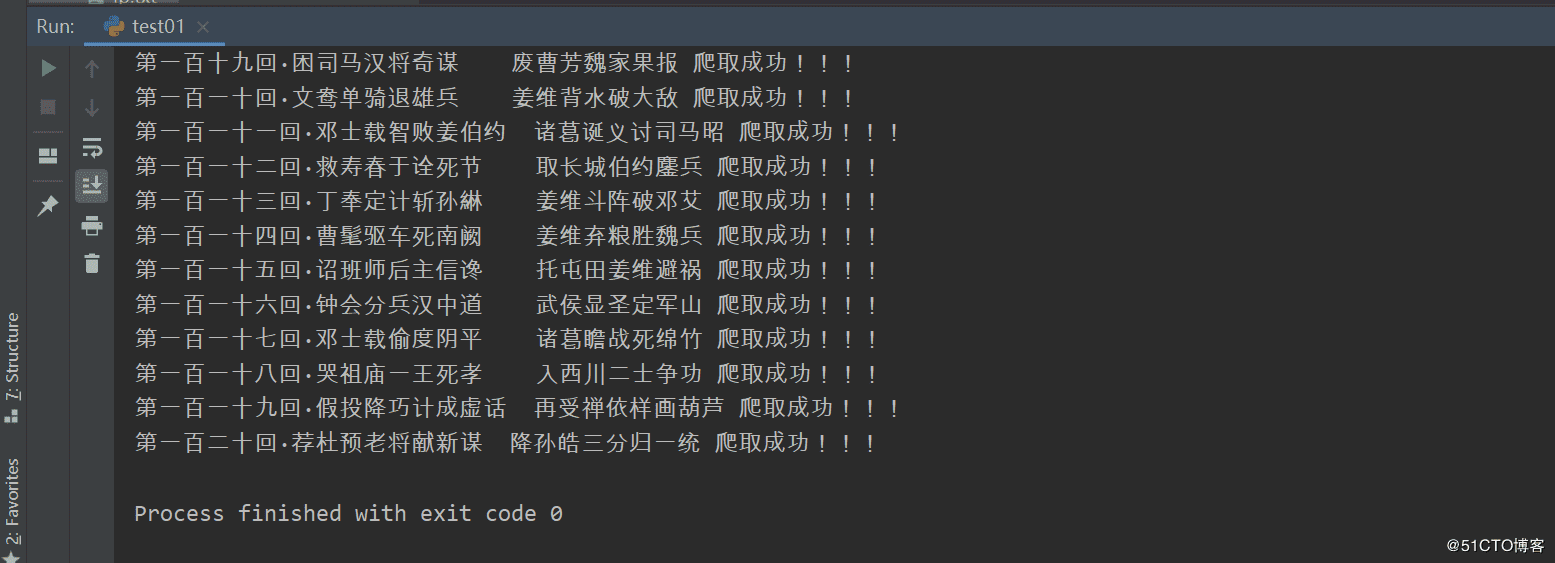
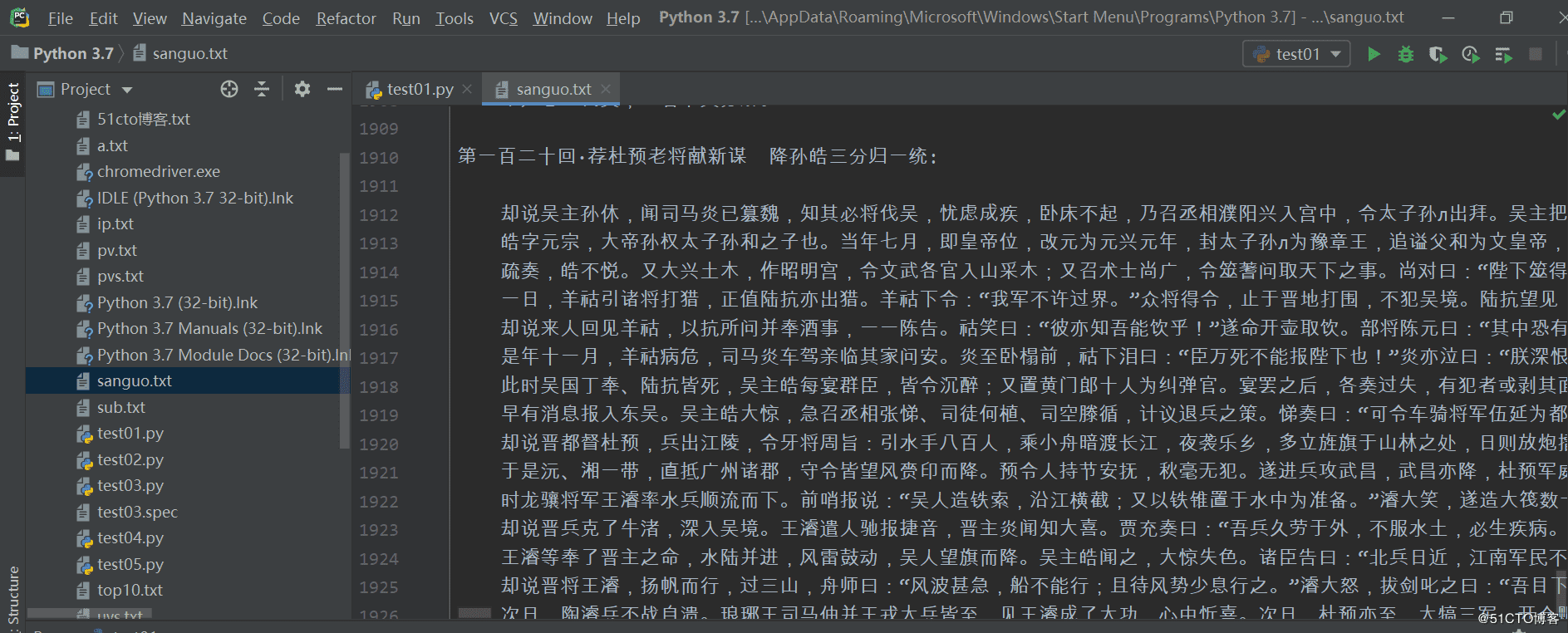
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:

 網公網安備
網公網安備