python爬蟲使用正則爬取網(wǎng)站的實現(xiàn)
本文章的所有代碼和相關(guān)文章, 僅用于經(jīng)驗技術(shù)交流分享,禁止將相關(guān)技術(shù)應(yīng)用到不正當(dāng)途徑,濫用技術(shù)產(chǎn)生的風(fēng)險與本人無關(guān)。
本文章是自己學(xué)習(xí)的一些記錄。歡迎各位大佬點評!
首先
今天是第一天寫博客,感受到了博客的魅力,博客不僅能夠記錄每天的代碼學(xué)習(xí)情況,并且可以當(dāng)作是自己的學(xué)習(xí)筆記,以便在后面知識點不清楚的時候前來復(fù)習(xí)。這是第一次使用爬蟲爬取網(wǎng)頁,這里展示的是爬取豆瓣電影top250的整個過程,歡迎大家指點。
這里我只爬取了電影鏈接和電影名稱,如果想要更加完整的爬取代碼,請聯(lián)系我。qq 1540741344 歡迎交流
開發(fā)工具: pycharm、chrome
分析網(wǎng)頁
在開發(fā)之前你首先要去你所要爬取的網(wǎng)頁提取出你要爬取的網(wǎng)頁鏈接,并且將網(wǎng)頁分析出你想要的內(nèi)容。
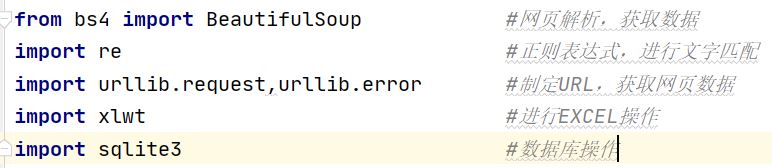
在開發(fā)之前首先要導(dǎo)入幾個模塊,模塊描述如下,具體不知道怎么導(dǎo)入包的可以看我下一篇內(nèi)容
首先定義幾個函數(shù),便于將各個步驟的工作分開便于代碼管理,我這里是分成了7個函數(shù),分別如下:
@主函數(shù)入口
if __name__=='__main__': #程序執(zhí)行入口 main()
@捕獲網(wǎng)頁html內(nèi)容 askURL(url)
這里的head的提取是在chrome中分析網(wǎng)頁源碼獲得的,具體我也不做過多解釋,大家可以百度
def askURL(url): #得到指定網(wǎng)頁信息的內(nèi)容 #爬取一個網(wǎng)頁的數(shù)據(jù) # 用戶代理,本質(zhì)上是告訴服務(wù)器,我們是以什么樣的機器來訪問網(wǎng)站,以便接受什么樣的水平數(shù)據(jù) head={'User-Agent':'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 84.0.4147.89 Safari / 537.36'} request=urllib.request.Request(url,headers=head) #request對象接受封裝的信息,通過urllib攜帶headers訪問信息訪問url response=urllib.request.urlopen(request) #用于接收返回的網(wǎng)頁信息 html=response.read().decode('utf-8') #通過read方法讀取response對象里的網(wǎng)頁信息,使用“utf-8” return html
@將baseurl里的內(nèi)容進行逐一解析 getData(baseURL)這里面的findlink和findname是正則表達(dá)式,可以首先定義全局變量
findlink=r’<a class='' href='http://www.aoyou183.cn/bcjs/(.*?)'’findname=r’<span class='title'>(.*?)</span>’
def getData(baseURL): dataList=[] #初始化datalist用于存儲獲取到的數(shù)據(jù) for i in range(0,10): url=baseURL+str(i*25) html=askURL(url) #保存獲取到的源碼 soup=BeautifulSoup(html,'html.parser') #對html進行逐一解析,使用html.parser解析器進行解析 for item in soup.find_all('div',class_='item'): #查找符合要求的字符串 ,形成列表,find_all是查找所有的class是item的div data=[] #初始化data,用于捕獲一次爬取一個div里面的內(nèi)容 item=str(item) #將item數(shù)據(jù)類型轉(zhuǎn)化為字符串類型 # print(item) link=re.findall(findlink,item)[0]#使用re里的findall方法根據(jù)正則提取item里面的電影鏈接 data.append(link)#將網(wǎng)頁鏈接追加到data里 name=re.findall(findname,item)[0]#使用re里的findall方法根據(jù)正則提取item里面的電影名字 data.append(name)#將電影名字鏈接追加到data里 # print(link) # print(name) dataList.append(data) #將捕獲的電影鏈接和電影名存到datalist里面 return dataList #返回一個列表,里面存放的是每個電影的信息 print(dataList)
@保存捕獲的數(shù)據(jù)到excel saveData(dataList,savepath)
def saveData(dataList,savepath): #保存捕獲的內(nèi)容到excel里,datalist是捕獲的數(shù)據(jù)列表,savepath是保存路徑 book=xlwt.Workbook(encoding='utf-8',style_compression=0)#初始化book對象,這里首先要導(dǎo)入xlwt的包 sheet=book.add_sheet('test',cell_overwrite_ok=True) #創(chuàng)建工作表 col=['電影詳情鏈接','電影名稱'] #列名 for i in range(0,2): sheet.write(0,i,col[i]) #將列名逐一寫入到excel for i in range(0,250): data=dataList[i] #依次將datalist里的數(shù)據(jù)獲取 for j in range(0,2): sheet.write(i+1,j,data[j]) #將data里面的數(shù)據(jù)逐一寫入 book.save(savepath)
@保存捕獲的數(shù)據(jù)到數(shù)據(jù)庫
def saveDataDb(dataList,dbpath): initDb(dbpath) #用一個函數(shù)初始化數(shù)據(jù)庫 conn=sqlite3.connect(dbpath) #初始化數(shù)據(jù)庫 cur=conn.cursor() #獲取游標(biāo) for data in dataList: for index in range(len(data)): data[index]=’'’+data[index]+’' ’#將每條數(shù)據(jù)都加上'' #每條數(shù)據(jù)之間用,隔開,定義sql語句的格式 sql=’’’ insert into test(link,name) values (%s) ’’’%’,’.join (data) cur.execute(sql) #執(zhí)行sql語句 conn.commit() #提交數(shù)據(jù)庫操作 conn.close() print('爬取存入數(shù)據(jù)庫成功!')
@初始化數(shù)據(jù)庫 initDb(dbpath)
def initDb(dbpath): conn=sqlite3.connect(dbpath) cur=conn.cursor() sql=’’’ create table test( id integer primary key autoincrement, link text, name varchar ) ’’’ cur.execute(sql) conn.commit() cur.close() conn.close()
@main函數(shù),用于調(diào)用其他函數(shù) main()
def main(): dbpath='testSpider.db' #用于指定數(shù)據(jù)庫存儲路徑 savepath='testSpider.xls' #用于指定excel存儲路徑 baseURL='https://movie.douban.com/top250?start=' #爬取的網(wǎng)頁初始鏈接 dataList=getData(baseURL) saveData(dataList,savepath) saveDataDb(dataList,dbpath)
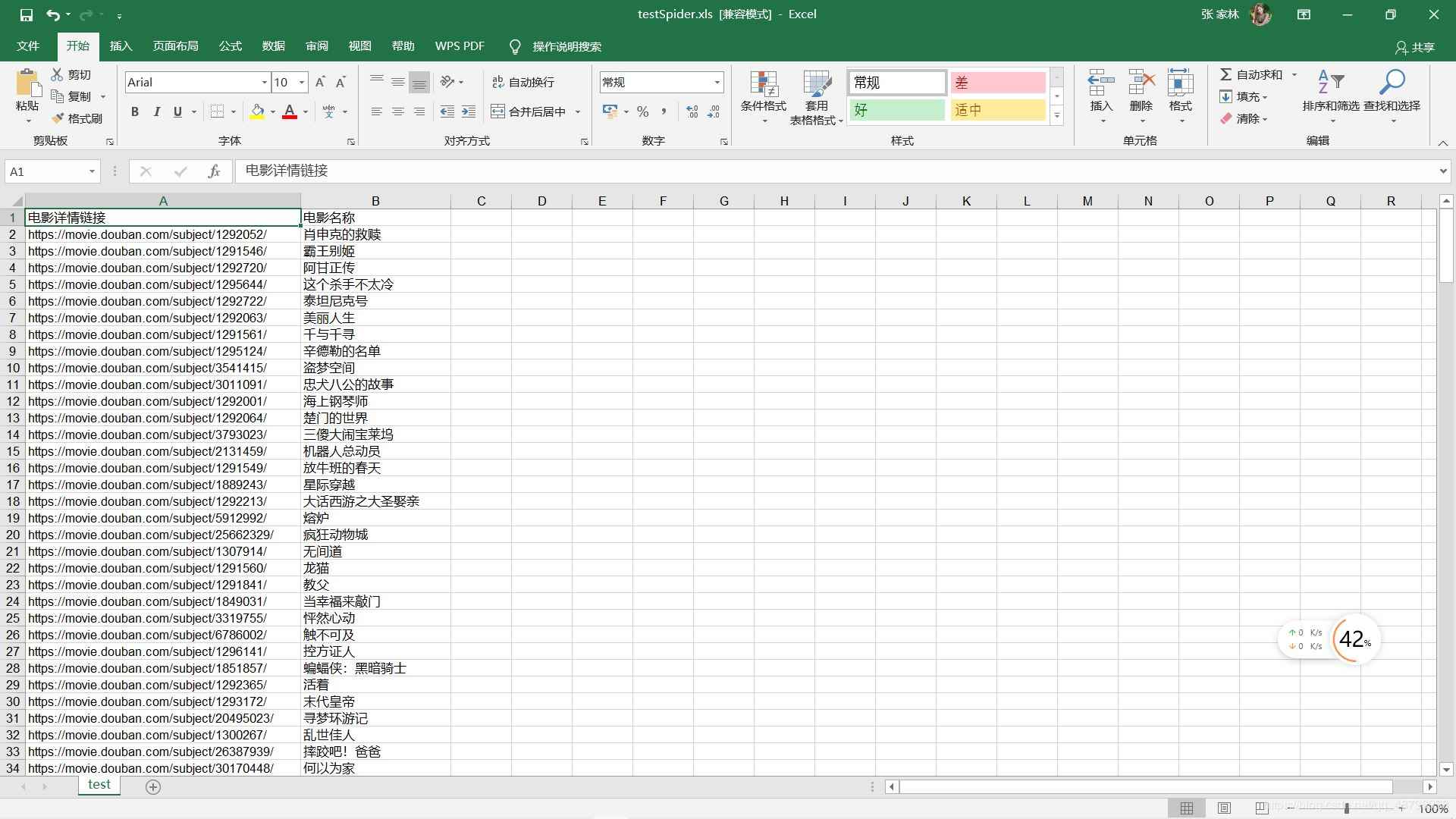
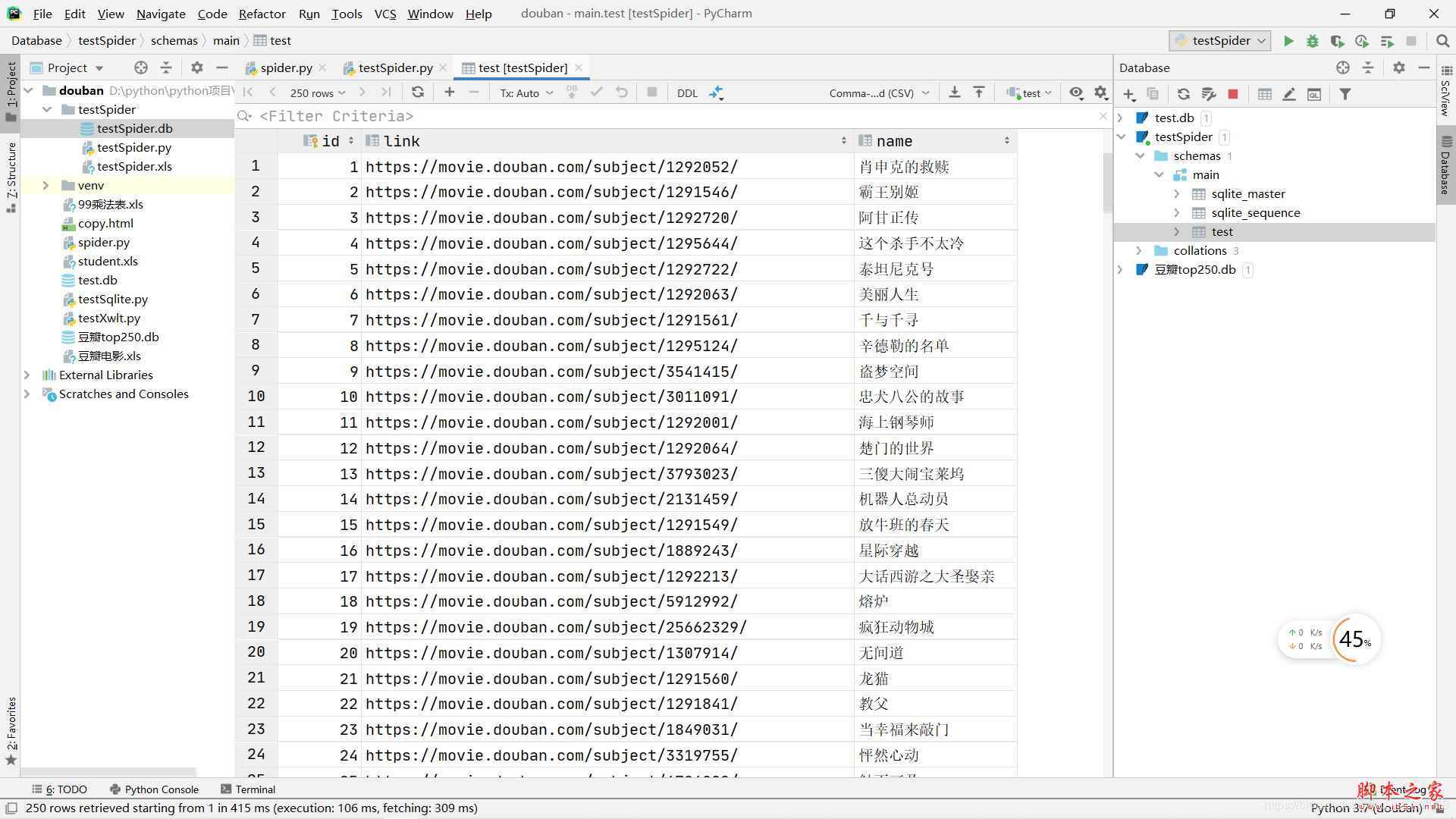
點擊運行就可以看到在左側(cè)已經(jīng)生成了excel和DB文件

excel可以直接打開
DB文件雙擊之后會在右邊打開
到這里爬蟲的基本內(nèi)容就已經(jīng)結(jié)束了,如果有什么不懂或者想交流的地方可以加我qq 1540741344
以下附上整個代碼
import re #網(wǎng)頁解析,獲取數(shù)據(jù)from bs4 import BeautifulSoup#正則表達(dá)式,進行文字匹配import urllib.request,urllib.error #制定URL,獲取網(wǎng)頁數(shù)據(jù)import xlwtimport sqlite3findlink=r’<a class='' href='http://www.aoyou183.cn/bcjs/(.*?)'’findname=r’<span class='title'>(.*?)</span>’def main(): dbpath='testSpider.db' #用于指定數(shù)據(jù)庫存儲路徑 savepath='testSpider.xls' #用于指定excel存儲路徑 baseURL='https://movie.douban.com/top250?start=' #爬取的網(wǎng)頁初始鏈接 dataList=getData(baseURL) saveData(dataList,savepath) saveDataDb(dataList,dbpath)def askURL(url): #得到指定網(wǎng)頁信息的內(nèi)容 #爬取一個網(wǎng)頁的數(shù)據(jù) # 用戶代理,本質(zhì)上是告訴服務(wù)器,我們是以什么樣的機器來訪問網(wǎng)站,以便接受什么樣的水平數(shù)據(jù) head={'User-Agent':'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 84.0.4147.89 Safari / 537.36'} request=urllib.request.Request(url,headers=head) #request對象接受封裝的信息,通過urllib攜帶headers訪問信息訪問url response=urllib.request.urlopen(request) #用于接收返回的網(wǎng)頁信息 html=response.read().decode('utf-8') #通過read方法讀取response對象里的網(wǎng)頁信息,使用“utf-8” return html #返回捕獲的網(wǎng)頁內(nèi)容,此時還是未處理過的def getData(baseURL): dataList=[] #初始化datalist用于存儲獲取到的數(shù)據(jù) for i in range(0,10): url=baseURL+str(i*25) html=askURL(url) #保存獲取到的源碼 soup=BeautifulSoup(html,'html.parser') #對html進行逐一解析,使用html.parser解析器進行解析 for item in soup.find_all('div',class_='item'): #查找符合要求的字符串 ,形成列表,find_all是查找所有的class是item的div data=[] #初始化data,用于捕獲一次爬取一個div里面的內(nèi)容 item=str(item) #將item數(shù)據(jù)類型轉(zhuǎn)化為字符串類型 # print(item) link=re.findall(findlink,item)[0]#使用re里的findall方法根據(jù)正則提取item里面的電影鏈接 data.append(link)#將網(wǎng)頁鏈接追加到data里 name=re.findall(findname,item)[0]#使用re里的findall方法根據(jù)正則提取item里面的電影名字 data.append(name)#將電影名字鏈接追加到data里 # print(link) # print(name) dataList.append(data) #將捕獲的電影鏈接和電影名存到datalist里面 return dataList #返回一個列表,里面存放的是每個電影的信息 print(dataList)def saveData(dataList,savepath): #保存捕獲的內(nèi)容到excel里,datalist是捕獲的數(shù)據(jù)列表,savepath是保存路徑 book=xlwt.Workbook(encoding='utf-8',style_compression=0)#初始化book對象,這里首先要導(dǎo)入xlwt的包 sheet=book.add_sheet('test',cell_overwrite_ok=True) #創(chuàng)建工作表 col=['電影詳情鏈接','電影名稱'] #列名 for i in range(0,2): sheet.write(0,i,col[i]) #將列名逐一寫入到excel for i in range(0,250): data=dataList[i] #依次將datalist里的數(shù)據(jù)獲取 for j in range(0,2): sheet.write(i+1,j,data[j]) #將data里面的數(shù)據(jù)逐一寫入 book.save(savepath) #保存excel文件def saveDataDb(dataList,dbpath): initDb(dbpath) #用一個函數(shù)初始化數(shù)據(jù)庫 conn=sqlite3.connect(dbpath) #初始化數(shù)據(jù)庫 cur=conn.cursor() #獲取游標(biāo) for data in dataList: for index in range(len(data)): data[index]=’'’+data[index]+’' ’#將每條數(shù)據(jù)都加上'' #每條數(shù)據(jù)之間用,隔開,定義sql語句的格式 sql=’’’ insert into test(link,name) values (%s) ’’’%’,’.join (data) cur.execute(sql) #執(zhí)行sql語句 conn.commit() #提交數(shù)據(jù)庫操作 conn.close() print('爬取存入數(shù)據(jù)庫成功!')def initDb(dbpath): conn=sqlite3.connect(dbpath) cur=conn.cursor() sql=’’’ create table test( id integer primary key autoincrement, link text, name varchar ) ’’’ cur.execute(sql) conn.commit() cur.close() conn.close()if __name__=='__main__': #程序執(zhí)行入口 main()
到此這篇關(guān)于python爬蟲使用正則爬取網(wǎng)站的實現(xiàn)的文章就介紹到這了,更多相關(guān)python正則爬取內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 利用CSS3新特性創(chuàng)建透明邊框三角2. AJAX實現(xiàn)數(shù)據(jù)的增刪改查操作詳解【java后臺】3. PHP 使用 Trait 解決 PHP 單繼承問題詳解4. el-table表格動態(tài)合并相同數(shù)據(jù)單元格(可指定列+自定義合并)5. ajax post下載flask文件流以及中文文件名問題6. Python腳本文件外部傳遞參數(shù)的處理方法7. 使用css實現(xiàn)全兼容tooltip提示框8. 如何通過vscode運行調(diào)試javascript代碼9. JSP+Servlet實現(xiàn)文件上傳到服務(wù)器功能10. WML語言的基本情況
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備