用Python 爬取貓眼電影數據分析《無名之輩》
前言
作者: 羅昭成
PS:如有需要Python學習資料的小伙伴可以加點擊下方鏈接自行獲取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
獲取貓眼接口數據
作為一個長期宅在家的程序員,對各種抓包簡直是信手拈來。在 Chrome 中查看原代碼的模式,可以很清晰地看到接口,接口地址即為:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&offset=15
在 Python 中,我們可以很方便地使用 request 來發送網絡請求,進而拿到返回結果:
def getMoveinfo(url): session = requests.Session() headers = { 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X)' } response = session.get(url, headers=headers) if response.status_code == 200: return response.text return None
根據上面的請求,我們能拿到此接口的返回數據,數據內容有很多信息,但有很多信息是我們并不需要的,先來總體看看返回的數據:
{ 'cmts':[ { 'approve':0, 'approved':false, 'assistAwardInfo':{ 'avatar':'', 'celebrityId':0, 'celebrityName':'', 'rank':0, 'title':'' }, 'authInfo':'', 'cityName':'貴陽', 'content':'必須十分,借錢都要看的一部電影。', 'filmView':false, 'id':1045570589, 'isMajor':false, 'juryLevel':0, 'majorType':0, 'movieId':1208282, 'nick':'nick', 'nickName':'nickName', 'oppose':0, 'pro':false, 'reply':0, 'score':5, 'spoiler':0, 'startTime':'2018-11-22 23:52:58', 'supportComment':true, 'supportLike':true, 'sureViewed':1, 'tagList':{ 'fixed':[ { 'id':1, 'name':'好評' }, { 'id':4, 'name':'購票' } ] }, 'time':'2018-11-22 23:52', 'userId':1871534544, 'userLevel':2, 'videoDuration':0, 'vipInfo':'', 'vipType':0 } ]}
如此多的數據,我們感興趣的只有以下這幾個字段:
nickName, cityName, content, startTime, score
接下來,進行我們比較重要的數據處理,從拿到的 JSON 數據中解析出需要的字段:
def parseInfo(data): data = json.loads(html)[’cmts’] for item in data: yield{ ’date’:item[’startTime’], ’nickname’:item[’nickName’], ’city’:item[’cityName’], ’rate’:item[’score’], ’conment’:item[’content’] }
拿到數據后,我們就可以開始數據分析了。但是為了避免頻繁地去貓眼請求數據,需要將數據存儲起來,在這里,筆者使用的是 SQLite3,放到數據庫中,更加方便后續的處理。存儲數據的代碼如下:
def saveCommentInfo(moveId, nikename, comment, rate, city, start_time) conn = sqlite3.connect(’unknow_name.db’) conn.text_factory=str cursor = conn.cursor() ins='insert into comments values (?,?,?,?,?,?)' v = (moveId, nikename, comment, rate, city, start_time) cursor.execute(ins,v) cursor.close() conn.commit() conn.close()
數據處理
因為前文我們是使用數據庫來進行數據存儲的,因此可以直接使用 SQL 來查詢自己想要的結果,比如評論前五的城市都有哪些:
SELECT city, count(*) rate_count FROM comments GROUP BY city ORDER BY rate_count DESC LIMIT 5
結果如下:
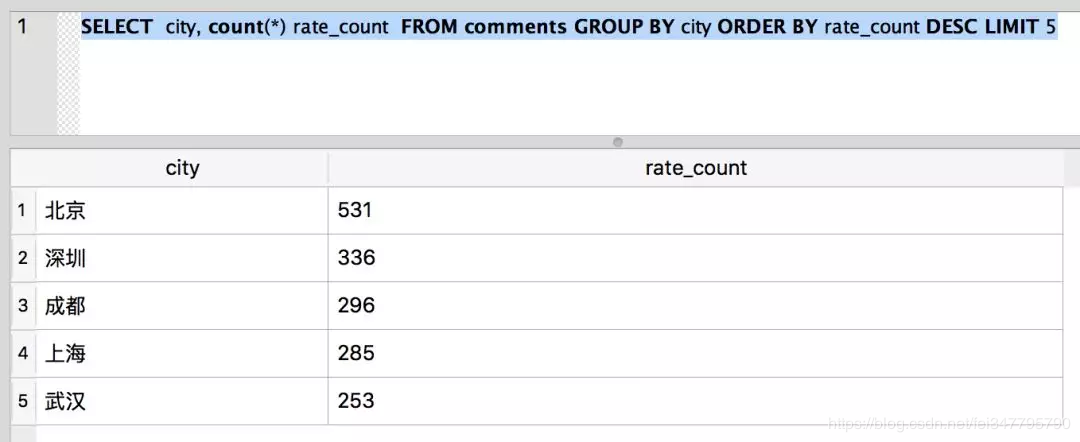
從上面的數據, 我們可以看出來,來自北京的評論數最多。
不僅如此,還可以使用更多的 SQL 語句來查詢想要的結果。比如每個評分的人數、所占的比例等。如筆者有興趣,可以嘗試著去查詢一下數據,就是如此地簡單。
而為了更好地展示數據,我們使用 Pyecharts 這個庫來進行數據可視化展示。
根據從貓眼拿到的數據,按照地理位置,直接使用 Pyecharts 來在中國地圖上展示數據:
data = pd.read_csv(f,sep=’{’,header=None,encoding=’utf-8’,names=[’date’,’nickname’,’city’,’rate’,’comment’])city = data.groupby([’city’])city_com = city[’rate’].agg([’mean’,’count’])city_com.reset_index(inplace=True)data_map = [(city_com[’city’][i],city_com[’count’][i]) for i in range(0,city_com.shape[0])]geo = Geo('GEO 地理位置分析',title_pos = 'center',width = 1200,height = 800)while True: try: attr,val = geo.cast(data_map) geo.add('',attr,val,visual_range=[0,300],visual_text_color='#fff', symbol_size=10, is_visualmap=True,maptype=’china’) except ValueError as e: e = e.message.split('No coordinate is specified for ')[1] data_map = filter(lambda item: item[0] != e, data_map) else : breakgeo.render(’geo_city_location.html’)
注:使用 Pyecharts 提供的數據地圖中,有一些貓眼數據中的城市找不到對應的從標,所以在代碼中,GEO 添加出錯的城市,我們將其直接刪除,過濾掉了不少的數據。
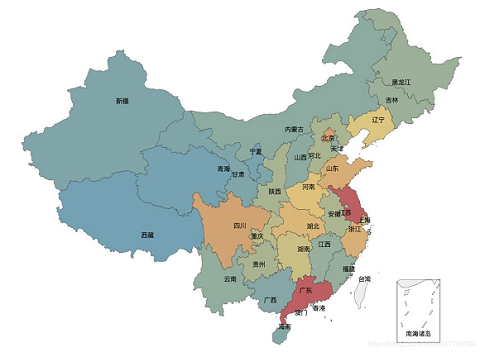
使用 Python,就是如此簡單地生成了如下地圖:

從可視化數據中可以看出,既看電影又評論的人群主要分布在中國東部,又以北京、上海、成都、深圳最多。雖然能從圖上看出來很多數據,但還是不夠直觀,如果想看到每個省/市的分布情況,我們還需要進一步處理數據。
而在從貓眼中拿到的數據中,城市包含數據中具備縣城的數據,所以需要將拿到的數據做一次轉換,將所有的縣城轉換到對應省市里去,然后再將同一個省市的評論數量相加,得到最后的結果。
data = pd.read_csv(f,sep=’{’,header=None,encoding=’utf-8’,names=[’date’,’nickname’,’city’,’rate’,’comment’])city = data.groupby([’city’])city_com = city[’rate’].agg([’mean’,’count’])city_com.reset_index(inplace=True)fo = open('citys.json',’r’)citys_info = fo.readlines()citysJson = json.loads(str(citys_info[0]))data_map_all = [(getRealName(city_com[’city’][i], citysJson),city_com[’count’][i]) for i in range(0,city_com.shape[0])]data_map_list = {}for item in data_map_all: if data_map_list.has_key(item[0]): value = data_map_list[item[0]] value += item[1] data_map_list[item[0]] = value else: data_map_list[item[0]] = item[1]data_map = [(realKeys(key), data_map_list[key] ) for key in data_map_list.keys()]def getRealName(name, jsonObj): for item in jsonObj: if item.startswith(name) : return jsonObj[item] return namedef realKeys(name): return name.replace(u'省', '').replace(u'市', '') .replace(u'回族自治區', '').replace(u'維吾爾自治區', '') .replace(u'壯族自治區', '').replace(u'自治區', '')
經過上面的數據處理,使用 Pyecharts 提供的 map 來生成一個按省/市來展示的地圖:
def generateMap(data_map): map = Map('城市評論數', width= 1200, height = 800, title_pos='center') while True: try: attr,val = geo.cast(data_map) map.add('',attr,val,visual_range=[0,800], visual_text_color='#fff',symbol_size=5, is_visualmap=True,maptype=’china’, is_map_symbol_show=False,is_label_show=True,is_roam=False, ) except ValueError as e: e = e.message.split('No coordinate is specified for ')[1] data_map = filter(lambda item: item[0] != e, data_map) else : break map.render(’city_rate_count.html’)
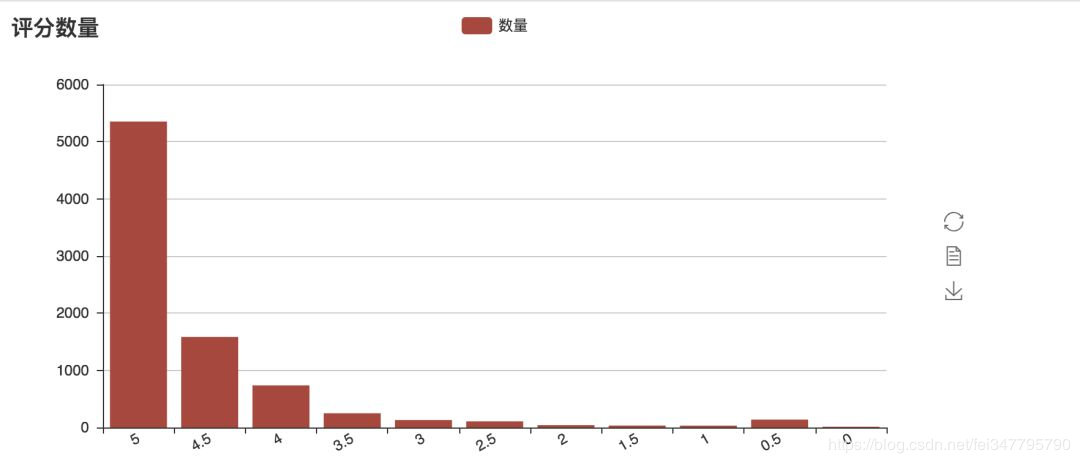
當然,我們還可以來可視化一下每一個評分的人數,這個地方采用柱狀圖來顯示:
data = pd.read_csv(f,sep=’{’,header=None,encoding=’utf-8’,names=[’date’,’nickname’,’city’,’rate’,’comment’])# 按評分分類rateData = data.groupby([’rate’])rateDataCount = rateData['date'].agg([ 'count'])rateDataCount.reset_index(inplace=True)count = rateDataCount.shape[0] - 1attr = [rateDataCount['rate'][count - i] for i in range(0, rateDataCount.shape[0])]v1 = [rateDataCount['count'][count - i] for i in range(0, rateDataCount.shape[0])]bar = Bar('評分數量')bar.add('數量',attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, xaxis_interval=0,is_splitline_show=True)bar.render('html/rate_count.html')
畫出來的圖,如下所示,在貓眼的數據中,五星好評的占比超過了 50%,比豆瓣上 34.8% 的五星數據好很多。
從以上觀眾分布和評分的數據可以看到,這一部劇,觀眾朋友還是非常地喜歡。前面,從貓眼拿到了觀眾的評論數據。現在,筆者將通過 jieba 把評論進行分詞,然后通過 Wordcloud 制作詞云,來看看,觀眾朋友們對《無名之輩》的整體評價:
data = pd.read_csv(f,sep=’{’,header=None,encoding=’utf-8’,names=[’date’,’nickname’,’city’,’rate’,’comment’])comment = jieba.cut(str(data[’comment’]),cut_all=False)wl_space_split = ' '.join(comment)backgroudImage = np.array(Image.open(r'./unknow_3.png'))stopword = STOPWORDS.copy()wc = WordCloud(width=1920,height=1080,background_color=’white’, mask=backgroudImage, font_path='./Deng.ttf', stopwords=stopword,max_font_size=400, random_state=50)wc.generate_from_text(wl_space_split)plt.imshow(wc)plt.axis('off')wc.to_file(’unknow_word_cloud.png’)
導出:
 .
.
到此這篇關于用Python 爬取貓眼電影數據分析《無名之輩》的文章就介紹到這了,更多相關Python 爬取貓眼電影數據分析《無名之輩》內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備