Python Excel vlookup函數(shù)實(shí)現(xiàn)過程解析
用法:注意是用英文的逗號',',且之間沒有空格。
文件名,[工作表名稱,不寫則默認(rèn)當(dāng)前激活的表],[從第幾行開始,不寫則默認(rèn)第二行,因?yàn)楹芏啾淼谝恍惺莟itle],列名(第一列是要查找的元素,列名可以不連續(xù),比如“ade”)
腳本會自動把要查找的第一列進(jìn)行大小寫變換,去除空格等操作,下面的例子中,第一列的名字有的是大寫,有的小寫,前后還有空格,腳本會默認(rèn)它們相同
現(xiàn)有Sheet1,內(nèi)容如下
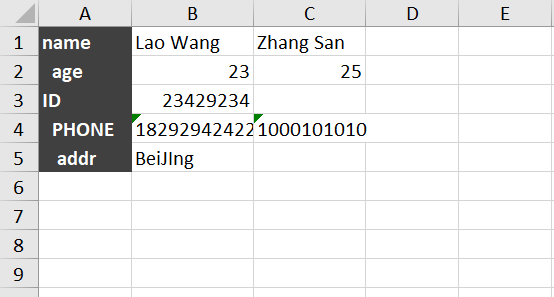
Sheet2內(nèi)容如下

想把 Sheet1 的 B,C 列的信息復(fù)制到 Sheet2 的 B,C列上,執(zhí)行腳本:
Source fileName,[sheetName],[row],columns:vlookup.xlsx,Sheet1,1,abcTarget fileName,[sheetName],[row],columns:vlookup.xlsx,Sheet2,1,abc{’name’: [’Lao Wang’, ’Zhang San’], ’age’: [23, 25], ’id’: [23429234, None], ’phone’: [’18292942422’, ’1000101010’], ’addr’: [’BeiJIng’, None]}{’addr’: [None, None], ’phone’: [None, None], ’id’: [None, None], ’age’: [None, None], ’name’: [None, None]}Processing...Done.
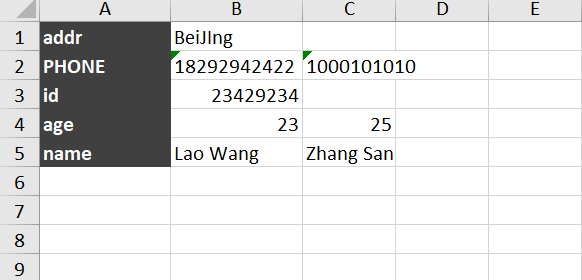
然后Sheet2的內(nèi)容就變成了:
import openpyxldef read_Excel(path,sheetName,row,*col): # 默認(rèn)從第二行開始,因?yàn)楹芏啾矶加斜眍^ if row == ’’: row = 2 else: row = int(row) workbook = openpyxl.load_workbook(path) # 默認(rèn)打開當(dāng)前激活的工作表 if sheetName == '': sheet0 = workbook.active # 獲取當(dāng)前激活的工作表 else: sheet0 = workbook[sheetName] # 如果制定了工作表,就打開指定的工作表 highest = sheet0.max_row case_list = {} # title 所在列,對比的那一列,假設(shè)A列 title = col[0] for i in range(row,highest+1): # 遍歷行 value_list = [] if sheet0[title+str(i)].value == None: # 如果A5是空的,pass pass else: v1 = sheet0[title+str(i)].value.lower().strip() # 忽略大小寫和前后空格 # 除去 title的其他列 for j in range(1,len(col)):v2 = sheet0[col[j]+str(i)].valuevalue_list.append(v2) case_list[v1] = value_list print(case_list) return case_listdef write_Excel(dict,path,sheetName,row,*col): # 將處理好的數(shù)據(jù)再次寫入excel if row == '': row = 2 else: row = int(row) workbook = openpyxl.load_workbook(path) if sheetName == '': sheet0 = workbook.active # 獲取當(dāng)前激活的工作表 else: sheet0 = workbook[sheetName] highest = sheet0.max_row # case title 所在列 title = col[0] for i in range(row,highest+1): if sheet0[title + str(i)].value != None: v1 = sheet0[title + str(i)].value.lower().strip() # 忽略大小寫和前后空格 for key in dict:if key == v1: for j in range(1,len(col)): v2 = sheet0[col[j]+str(i)] v2.value = dict[key][j-1] workbook.save(path)def process(r1,r2): # 對比處理兩次讀取的內(nèi)容,然后更新r2的內(nèi)容 print(’Processing...’) for key in r1: if key in r2: length = len(r1[key]) if length > 0:for i in range(0, len(r1[key])): # 如果想要不想覆蓋原有的數(shù)值,可以取消注釋,然后刪除下面那行 # if r2[key][i] == None: # r2[key][i] = r1[key][i] r2[key][i] = r1[key][i] else: pass return r2def manual(): info1 = input(’Read from fileName,[sheetName],[row],columns:n’) file1,sheetName1,row1,list1 = info1.split(’,’) info2 = input(’Write into fileName,[sheetName],[row],columns:n’) file2,sheetName2,row2,list2 = info2.split(’,’) r1 = read_Excel(file1,sheetName1,row1,*list1) r2 = read_Excel(file2,sheetName2,row2,*list2) r3 = process(r1,r2) write_Excel(r3,file2,sheetName2,row2,*list2) print(’Done.’)if __name__ == '__main__': manual()
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. Python requests庫參數(shù)提交的注意事項(xiàng)總結(jié)2. IntelliJ IDEA導(dǎo)入jar包的方法3. JavaScript中l(wèi)ayim之整合右鍵菜單的示例代碼4. ASP基礎(chǔ)知識VBScript基本元素講解5. python ansible自動化運(yùn)維工具執(zhí)行流程6. 詳談ajax返回?cái)?shù)據(jù)成功 卻進(jìn)入error的方法7. python操作mysql、excel、pdf的示例8. SpringBoot參數(shù)校驗(yàn)與國際化使用教程9. 通過Python pyecharts輸出保存圖片代碼實(shí)例10. vue-electron中修改表格內(nèi)容并修改樣式

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備