Python 實(shí)現(xiàn)將numpy中的nan和inf,nan替換成對(duì)應(yīng)的均值
nan:not a number
inf:infinity;正無(wú)窮
numpy中的nan和inf都是float類型

t!=t 返回bool類型的數(shù)組(矩陣)
np.count_nonzero() 返回的是數(shù)組中的非0元素個(gè)數(shù);true的個(gè)數(shù)。
np.isnan() 返回bool類型的數(shù)組。
那么問(wèn)題來(lái)了,在一組數(shù)據(jù)中單純的把nan替換為0,合適么?會(huì)帶來(lái)什么樣的影響?
比如,全部替換為0后,替換之前的平均值如果大于0,替換之后的均值肯定會(huì)變小,所以更一般的方式是把缺失的數(shù)值替換為均值(中值)或者是直接刪除有缺失值的一行
demo.py(numpy,將數(shù)組中的nan替換成對(duì)應(yīng)的均值):
# coding=utf-8import numpy as np def fill_ndarray(t1): for i in range(t1.shape[1]): # 遍歷每一列(每一列中的nan替換成該列的均值) temp_col = t1[:, i] # 當(dāng)前的一列 nan_num = np.count_nonzero(temp_col != temp_col) if nan_num != 0: # 不為0,說(shuō)明當(dāng)前這一列中有nan temp_not_nan_col = temp_col[temp_col == temp_col] # 去掉nan的ndarray # 選中當(dāng)前為nan的位置,把值賦值為不為nan的均值 temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean() # mean()表示求均值。 return t1 if __name__ == ’__main__’: t1 = np.array([[ 0., 1., 2., 3., 4., 5.], [ 6., 7., np.nan, np.nan, np.nan, np.nan], [12., 13., 14., 15., 16., 17.], [18., 19., 20., 21., 22., 23.]]) t1 = fill_ndarray(t1) # 將nan替換成對(duì)應(yīng)的均值 print(t1) ’’’ [[ 0. 1. 2. 3. 4. 5.] [ 6. 7. 12. 13. 14. 15.] [12. 13. 14. 15. 16. 17.] [18. 19. 20. 21. 22. 23.]] ’’’
補(bǔ)充知識(shí):numpy對(duì)數(shù)組求平均時(shí)如何忽略nan值
前言:在對(duì)numpy數(shù)組求平均np.mean()或者求數(shù)組中最大最小值np.max()/np.min()時(shí),如果數(shù)組中有nan,此時(shí)求得的結(jié)果為:nan,那么該如何忽略其中的nan呢?此時(shí)應(yīng)該用另一個(gè)方法:np.nanmean(),np.nanmax(),np.nanmin().
使用np.mean()的效果
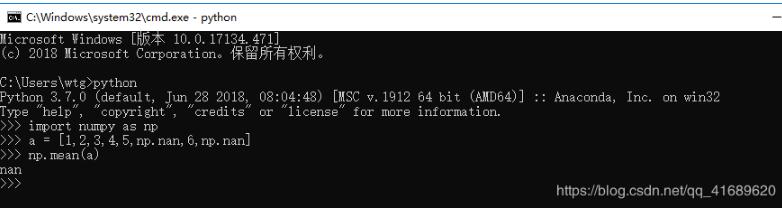
使用np.nanmean()的效果
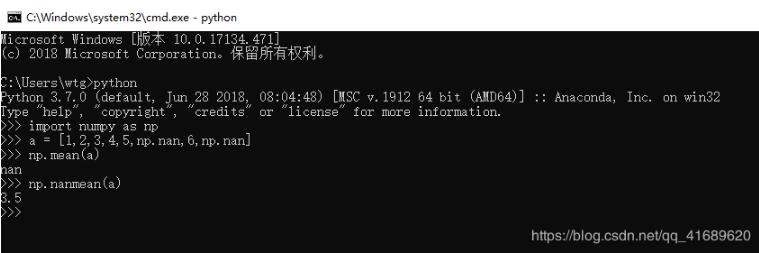
以上這篇Python 實(shí)現(xiàn)將numpy中的nan和inf,nan替換成對(duì)應(yīng)的均值就是小編分享給大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備