Python selenium自動化測試模型圖解
1、線性測試
優勢:每一個腳本都是完整獨立的,每一個腳本對應一個測試用例
缺點:開發成本高,會有重復操作重復腳本;維護成本也高,修改重復操作的腳本時,要逐一進行修改。
2、模塊化驅動測試
把重復的操作獨立成公共模塊,當用例執行中需要這一模塊操作時調用,這樣最大限度的消除重復,提高測試用例的可維護性。
解決了線性測試的兩個問題:
(1)提高了開發效率
(2)簡化了維護復雜性
缺點:在數據會改變的情況下,會加大編寫重復的腳本(比如現在我要測試不同用戶登錄的場景,先是張三登錄,登錄完后換李四登錄,然后繼續換用戶登錄,這樣會有重復的登錄腳本,雖然登錄的步驟一樣,但是登錄的數據不一樣)
寫一個類,將登錄的函數包裝起來
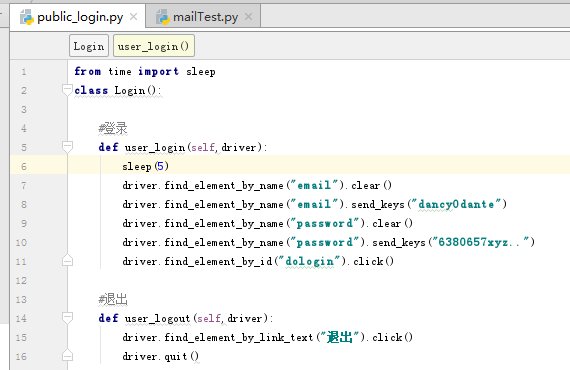
然后寫個主程序調用登錄的函數
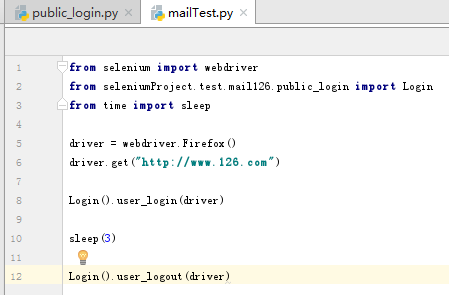
3、數據驅動測試
數據驅動是數據的參數化,因為輸入數據的不痛而引起輸出結果的不同;比如定義的數組、字典、或者是外部文件(Excel、csv、txt、xml等)都可以看做是數據驅動,目的就是實現數據與腳本的分離。
優點:進一步增強了腳本的復用性。
(1)通過參數化來實現數據驅動
將要輸入的值當做一個參數來進行傳入,實現根據數據輸入的不同而有不同的執行結果
登錄的函數以傳參的方式封裝
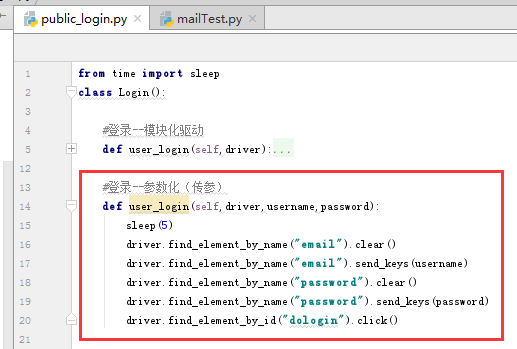
然后主方法中調用該方法,傳入不同的參數
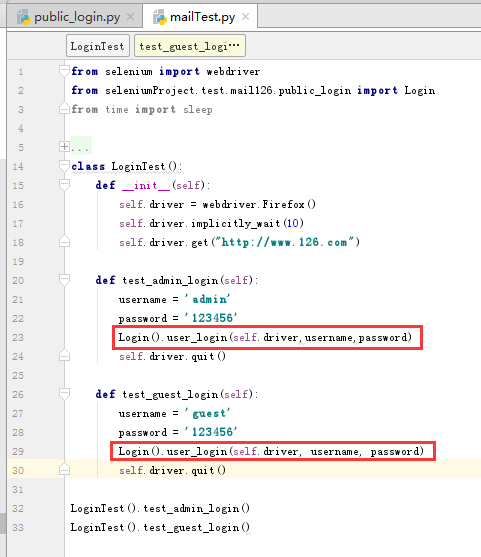
(2)參數化搜索關鍵字
將要搜索的關鍵字定義為一組數組,然后通過循環的方式進行搜索,搜索的關鍵字不一樣測試結果也不一樣。
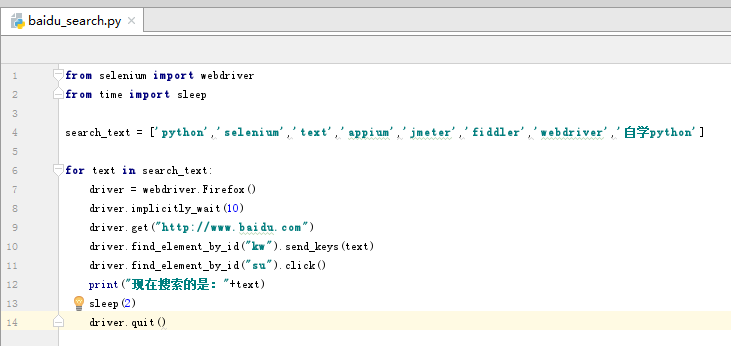
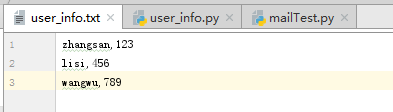
(3)讀取txt文件
Python中提供了幾種讀取txt文件的方式:
read():讀取整個文件
readline():讀取一行數據
readlines():讀取所有行的數據
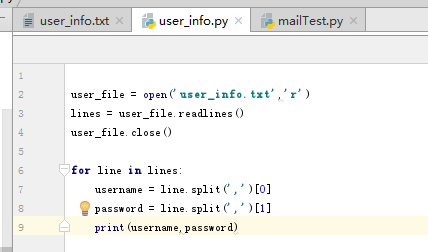
(4)讀取csv文件
(5)讀取xml文件
parse():打開xml文件
documentElement:用于得到xml文件唯一的根元素
nodeName:節點名稱
nodeValue:節點值
nodeType:節點類型
ELEMENT_NODE:元素節點類型
getElementsByTagName:可以通過標簽名獲取標簽,獲取的對象以數組的形式存儲
getAttribute():用于獲取元素的屬性值,與webdriver中的get_attribute()類似
firstChild:屬性返回被選節點的第一個子節點
data:表示獲取該節點的數據,與webdriver中的text方法類似
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:

 網公網安備
網公網安備