python:批量統(tǒng)計(jì)xml中各類目標(biāo)的數(shù)量案例
之前寫了一個(gè)matlab的,越用越覺得麻煩,如果不同數(shù)據(jù)集要改類別數(shù)目,而且運(yùn)行速度慢。所以重新寫了一個(gè)Python的,直接讀取xml文件夾路徑就可以,不用預(yù)先知道類別,直接能夠檢測出所有類別的目標(biāo)名稱及其對應(yīng)的數(shù)量。
分享出來給大家。
代碼如下:
# -*- coding:utf-8 -*-import osimport xml.etree.ElementTree as ETimport numpy as npnp.set_printoptions(suppress=True, threshold=np.nan)import matplotlibfrom PIL import Image def parse_obj(xml_path, filename): tree=ET.parse(xml_path+filename) objects=[] for obj in tree.findall(’object’): obj_struct={} obj_struct[’name’]=obj.find(’name’).text objects.append(obj_struct) return objects def read_image(image_path, filename): im=Image.open(image_path+filename) W=im.size[0] H=im.size[1] area=W*H im_info=[W,H,area] return im_info if __name__ == ’__main__’: xml_path=’C:/Users/nansbas/Desktop/hebin/03/’ filenamess=os.listdir(xml_path) filenames=[] for name in filenamess: name=name.replace(’.xml’,’’) filenames.append(name) recs={} obs_shape={} classnames=[] num_objs={} obj_avg={} for i,name in enumerate(filenames): recs[name]=parse_obj(xml_path, name+ ’.xml’ ) for name in filenames: for object in recs[name]: if object[’name’] not in num_objs.keys(): num_objs[object[’name’]]=1 else: num_objs[object[’name’]]+=1 if object[’name’] not in classnames: classnames.append(object[’name’]) for name in classnames: print(’{}:{}個(gè)’.format(name,num_objs[name])) print(’信息統(tǒng)計(jì)算完畢。’)
補(bǔ)充知識(shí):Python對目標(biāo)檢測數(shù)據(jù)集xml文件操作(統(tǒng)計(jì)目標(biāo)種類、數(shù)量、面積、比例等&修改目標(biāo)名字)
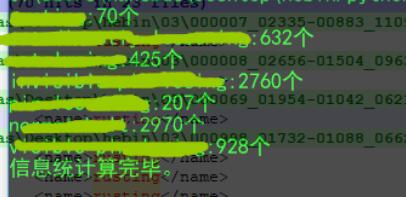
1. 根據(jù)xml文件統(tǒng)計(jì)目標(biāo)種類以及數(shù)量
# -*- coding:utf-8 -*-#根據(jù)xml文件統(tǒng)計(jì)目標(biāo)種類以及數(shù)量import osimport xml.etree.ElementTree as ETimport numpy as npnp.set_printoptions(suppress=True, threshold=np.nan)import matplotlibfrom PIL import Image def parse_obj(xml_path, filename): tree=ET.parse(xml_path+filename) objects=[] for obj in tree.findall(’object’): obj_struct={} obj_struct[’name’]=obj.find(’name’).text objects.append(obj_struct) return objects def read_image(image_path, filename): im=Image.open(image_path+filename) W=im.size[0] H=im.size[1] area=W*H im_info=[W,H,area] return im_info if __name__ == ’__main__’: xml_path=’/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/Annotations/’ filenamess=os.listdir(xml_path) filenames=[] for name in filenamess: name=name.replace(’.xml’,’’) filenames.append(name) recs={} obs_shape={} classnames=[] num_objs={} obj_avg={} for i,name in enumerate(filenames): recs[name]=parse_obj(xml_path, name+ ’.xml’ ) for name in filenames: for object in recs[name]: if object[’name’] not in num_objs.keys(): num_objs[object[’name’]]=1 else: num_objs[object[’name’]]+=1 if object[’name’] not in classnames: classnames.append(object[’name’]) for name in classnames: print(’{}:{}個(gè)’.format(name,num_objs[name])) print(’信息統(tǒng)計(jì)算完畢。’)
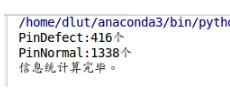
2.根據(jù)xml文件統(tǒng)計(jì)目標(biāo)的平均長度、寬度、面積以及每一個(gè)目標(biāo)在原圖中的占比
# -*- coding:utf-8 -*-#統(tǒng)計(jì)# 計(jì)算每一個(gè)目標(biāo)在原圖中的占比# 計(jì)算目標(biāo)的平均長度、# 計(jì)算平均寬度,# 計(jì)算平均面積、# 計(jì)算目標(biāo)平均占比import osimport xml.etree.ElementTree as ETimport numpy as np#np.set_printoptions(suppress=True, threshold=np.nan) #10,000,000np.set_printoptions(suppress=True, threshold=10000000) #10,000,000import matplotlibfrom PIL import Imagedef parse_obj(xml_path, filename): tree = ET.parse(xml_path + filename) objects = [] for obj in tree.findall(’object’): obj_struct = {} obj_struct[’name’] = obj.find(’name’).text bbox = obj.find(’bndbox’) obj_struct[’bbox’] = [int(bbox.find(’xmin’).text),int(bbox.find(’ymin’).text),int(bbox.find(’xmax’).text),int(bbox.find(’ymax’).text)] objects.append(obj_struct) return objectsdef read_image(image_path, filename): im = Image.open(image_path + filename) W = im.size[0] H = im.size[1] area = W * H im_info = [W, H, area] return im_infoif __name__ == ’__main__’: image_path = ’/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/JPEGImages/’ xml_path = ’/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/Annotations/’ filenamess = os.listdir(xml_path) filenames = [] for name in filenamess: name = name.replace(’.xml’, ’’) filenames.append(name) print(filenames) recs = {} ims_info = {} obs_shape = {} classnames = [] num_objs={} obj_avg = {} for i, name in enumerate(filenames): print(’正在處理 {}.xml ’.format(name)) recs[name] = parse_obj(xml_path, name + ’.xml’) print(’正在處理 {}.jpg ’.format(name)) ims_info[name] = read_image(image_path, name + ’.jpg’) print(’所有信息收集完畢。’) print(’正在處理信息......’) for name in filenames: im_w = ims_info[name][0] im_h = ims_info[name][1] im_area = ims_info[name][2] for object in recs[name]: if object[’name’] not in num_objs.keys(): num_objs[object[’name’]] = 1 else: num_objs[object[’name’]] += 1 #num_objs += 1 ob_w = object[’bbox’][2] - object[’bbox’][0] ob_h = object[’bbox’][3] - object[’bbox’][1] ob_area = ob_w * ob_h w_rate = ob_w / im_w h_rate = ob_h / im_h area_rate = ob_area / im_area if not object[’name’] in obs_shape.keys(): obs_shape[object[’name’]] = ([[ob_w, ob_h, ob_area, w_rate, h_rate, area_rate]]) else: obs_shape[object[’name’]].append([ob_w, ob_h, ob_area, w_rate, h_rate, area_rate]) if object[’name’] not in classnames: classnames.append(object[’name’]) # 求平均 for name in classnames: obj_avg[name] = (np.array(obs_shape[name]).sum(axis=0)) / num_objs[name] print(’{}的情況如下:*******n’.format(name)) print(’ 目標(biāo)平均W={}’.format(obj_avg[name][0])) print(’ 目標(biāo)平均H={}’.format(obj_avg[name][1])) print(’ 目標(biāo)平均area={}’.format(obj_avg[name][2])) print(’ 目標(biāo)平均與原圖的W比例={}’.format(obj_avg[name][3])) print(’ 目標(biāo)平均與原圖的H比例={}’.format(obj_avg[name][4])) print(’ 目標(biāo)平均原圖面積占比={}n’.format(obj_avg[name][5])) print(’信息統(tǒng)計(jì)計(jì)算完畢。’)

3.修改xml文件中某個(gè)目標(biāo)的名字為另一個(gè)名字
#修改xml文件中的目標(biāo)的名字,import os, sysimport globfrom xml.etree import ElementTree as ET# 批量讀取Annotations下的xml文件# per=ET.parse(r’C:UsersrockhuangDesktopAnnotations000003.xml’)xml_dir = r’/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/Annotations’xml_list = glob.glob(xml_dir + ’/*.xml’)for xml in xml_list: print(xml) per = ET.parse(xml) p = per.findall(’/object’) for oneper in p: # 找出person節(jié)點(diǎn) child = oneper.getchildren()[0] # 找出person節(jié)點(diǎn)的子節(jié)點(diǎn) if child.text == ’PinNormal’: #需要修改的名字 child.text = ’normal bolt’ #修改成什么名字 if child.text == ’PinDefect’: #需要修改的名字 child.text = ’defect bolt-1’ #修改成什么名字 per.write(xml) print(child.tag, ’:’, child.text)

以上這篇python:批量統(tǒng)計(jì)xml中各類目標(biāo)的數(shù)量案例就是小編分享給大家的全部內(nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. 詳解CSS偽元素的妙用單標(biāo)簽之美2. XML入門的常見問題(四)3. ASP基礎(chǔ)知識(shí)VBScript基本元素講解4. 利用CSS3新特性創(chuàng)建透明邊框三角5. asp(vbscript)中自定義函數(shù)的默認(rèn)參數(shù)實(shí)現(xiàn)代碼6. 使用Spry輕松將XML數(shù)據(jù)顯示到HTML頁的方法7. 淺談SpringMVC jsp前臺(tái)獲取參數(shù)的方式 EL表達(dá)式8. HTML5 Canvas繪制圖形從入門到精通9. XHTML 1.0:標(biāo)記新的開端10. JSP的Cookie在登錄中的使用
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備