Python抓包程序mitmproxy安裝和使用過程圖解
一、介紹說明
mitmproxy是一個支持HTTP和HTTPS的抓包程序,有類似Fiddler、Charles的功能,只不過它是一個控制臺的形式操作。
mitmproxy還有兩個關(guān)聯(lián)組件。一個是mitmdump,它是mitmproxy的命令行接口,利用它我們可以對接Python腳本,用Python實(shí)現(xiàn)監(jiān)聽后的處理。另一個是mitmweb,它是一個Web程序,通過它我們可以清楚觀察mitmproxy捕獲的請求。
mitmproxy的功能:
1、攔截HTTP和HTTPS請求和響應(yīng)
2、保存HTTP會話并進(jìn)行分析
3、模擬客戶端發(fā)起請求,模擬服務(wù)器端返回響應(yīng)
4、利用反向代理將流量轉(zhuǎn)發(fā)給指定的服務(wù)器
5、支持Mac和linux上的透明代理
6、利用Python對HTTP請求與響應(yīng)進(jìn)行實(shí)時處理
mitmproxy運(yùn)行與自己的PC上,在PC的8080端口運(yùn)行,然后開啟一個代理服務(wù),這個服務(wù)實(shí)際上是一個HTTP/HTTPS的代理。
手機(jī)和PC在一個局域網(wǎng)內(nèi),設(shè)置代理是mitmproxy的代理地址,這樣手機(jī)在訪問互聯(lián)網(wǎng)的時候流量數(shù)據(jù)包就會流經(jīng)mitmproxy,mitmproxy再去轉(zhuǎn)發(fā)這些數(shù)據(jù)包到真實(shí)的服務(wù)器,服務(wù)器返回?cái)?shù)據(jù)包時再由mitmproxy轉(zhuǎn)發(fā)回手機(jī),這樣mitmproxy就相當(dāng)于起了中間人的作用,抓取到所有request和response,另外這個過程還可以對接mitmproxy,抓取到的request和response的具體內(nèi)容都可以直接用python來處理,比如:得到response之后我們可以直接進(jìn)行解析,然后存入數(shù)據(jù)庫,這樣就完成了數(shù)據(jù)的解析和存儲過程。
二、安裝以及配置
pip install mitmproxy
如果安裝失敗報(bào)錯timeout,那就多試幾遍或者加上參數(shù)--timeout秒數(shù)
pip --timeout 10000 install mitmproxy
注意 :在 Windows 上不支持 mitmproxy 的控制臺接口,但是可以使用 mitmdump和mitmweb。
這三個命令功能一致,且都可以加載自定義腳本,唯一的區(qū)別是交互界面的不同。
mitmproxy命令啟動后,會提供一個命令行界面,用戶可以實(shí)時看到發(fā)生的請求,并通過命令過濾請求,查看請求數(shù)據(jù)。
mitmweb命令啟動后,會提供一個 web 界面,用戶可以實(shí)時看到發(fā)生的請求,并通過 GUI 交互來過濾請求,查看請求數(shù)據(jù)。
mitmdump命令啟動后,沒有界面,程序默默運(yùn)行,所以 mitmdump 無法提供過濾請求、查看數(shù)據(jù)的功能,只能結(jié)合自定義腳本,默默工作。
證書配置
運(yùn)行mitmdump命令產(chǎn)生CA證書,并在用戶目錄下的.mitmproxy 目錄里面找到CA證書,如下圖所示。
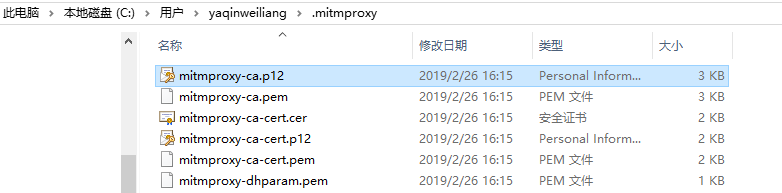
在windows平臺下安裝證書
點(diǎn)擊mitmproxy-ca.p12,就會出現(xiàn)導(dǎo)入證書的引導(dǎo)頁,如下圖所示:

然后直接點(diǎn)擊下一步即可,如果不需要設(shè)置密碼,繼續(xù)點(diǎn)擊下一步。
接下來需要選擇證書的存儲區(qū)域,如下圖所示。

這里點(diǎn)擊第二個選項(xiàng)“將所有的證書都放入下列存儲”,然后點(diǎn)擊“瀏覽”按鈕,選擇證書存儲位置為 受信任的根證書頒發(fā)機(jī)構(gòu)”,接著點(diǎn)擊“確定”按鈕,然后點(diǎn)擊“下一步”按鈕。
最后,如果有安全警告彈出,直接點(diǎn)擊“是”按鈕即可。這樣就完成了CA證書的配置了。
在Android平臺下安裝證書
在Android手機(jī)上,需要將mitmproxy-ca-cert.pem文件發(fā)送到手機(jī)上,接下來點(diǎn)擊證書會出現(xiàn)一個提示窗口。
如果手機(jī)不能識別.pem文件,那就將.cer文件復(fù)制到手機(jī),然后點(diǎn)擊安裝證書。
這時候輸入證書名稱,例如:mitmproxy,然后點(diǎn)擊確定則完成了安裝。
安卓手機(jī)還有一種方法安裝證書
命令行輸入ipconfig查看本機(jī)IP,并輸入mitmweb啟動mitmproxy
可以看到
Web server listening at http://127.0.0.1:8081/Proxy server listening at http://*:8080
所以可以確定,我們代理IP端口號為8080,于是,在手機(jī)Wifi設(shè)置手動代理,輸入本機(jī)IP和端口號8080。此時,打開mitmproxy界面并操作手機(jī),可以看到手機(jī)請求信息:

此時在手機(jī)端打開http://mitm.it/,可以進(jìn)入到如下界面:(如果沒有進(jìn)入如下界面,請檢查手機(jī)端代理IP和端口號是否輸入正確!)

選擇第一個進(jìn)行證書安裝,有時網(wǎng)絡(luò)不好,可能頁面一直沒有響應(yīng)。我就遇到這樣的問題,最后,多試幾次,就可以進(jìn)入證書安裝界面。
成功安裝證書后,Go to Settings > General > About > Certificate Trust Settings.Under “Enable full trust for root certificates”, turn on trust for the mitmproxy certificate.

三、mitmdump的使用
mitmdump是mitmproxy的命令行接口,同時還可以對接Python對請求進(jìn)行處理,這是相對于fiddler和Charles這些工具更加方便的地方,有了它我們可以不用手動截獲和分析HTTP請求和響應(yīng),只需要寫好請求與響應(yīng)的處理邏輯即可。它還可以實(shí)現(xiàn)數(shù)據(jù)的解析、存儲等工作,這些過程都可以通過Python來實(shí)現(xiàn)。
1、我們可以使用命令啟動mitmproxy,并把截獲的數(shù)據(jù)保存到文件中
命令如下:
mitmdump -w outfile
其中outfile的名稱任意,截獲的數(shù)據(jù)都會被保存到此文件中。
還可以指定一個腳本來處理截獲的數(shù)據(jù),使用-s參數(shù)即可
mitmdump -s script.py
這里指定了當(dāng)前處理腳本為script.py,它需要放置在當(dāng)前命令執(zhí)行的目錄下。我們可以在腳本里寫入如下的代碼:
def request(flow) : flow.request.headers[’User-Agent’] = ’MitmProxy’ print(flow.request.headers)
我們定義了 一個request ()方法,參數(shù)為 flow ,它其實(shí)是一個 HTTP Flow 對象,通過 request 屬性即可獲取到當(dāng)前請求對象 。然后打印輸出了請求的請求頭,將請求頭的 User-Agent 改成了MitmProxy。運(yùn)行之后在手機(jī)端訪問 http: //httpbin.org get 。
手機(jī)端返回結(jié)果的 Headers 實(shí)際上就是請求的 Headers, User-Agent 被修改成了 mitmproxy ,PC控制臺輸出了修改后Headers 內(nèi)容,其 User-Agent 的內(nèi)容正是 mitmproxy。所以,通過這上面三行代碼我們就可以完成對請求的改寫。
print()方法輸出結(jié)果可以呈現(xiàn)在 PC 端控制臺上,可以方便地進(jìn)行調(diào)試。
2、日志的輸出
mitmdump提供了專門的日志輸出功能,可以設(shè)定不同級別以不同顏色輸出結(jié)果,我們可以把腳本修改成以下內(nèi)容:
from mitmproxy import ctx def request(flow): flow .request . headers[’User-Agent’] =’mitmProxy’ ctx.log.info(str(flow.request.headers)) ctx.log.warn(str(flow.request.headers)) ctx.log.error(str(flow.request.headers))
在這里調(diào)用了ctx模塊,它有一個log功能,調(diào)用不同的輸出方法就可以輸出不同顏色的結(jié)果,以方便我們做調(diào)試。例如:info()方法輸出的內(nèi)容是白色的,warn()方法輸出的內(nèi)容是黃色的,error()方法輸出的內(nèi)容是紅色的。
不同的顏色對應(yīng)不同級別的輸出,我們可以將不同的結(jié)果合理劃分級別輸出,以更直觀方便地查看調(diào)試信息。
3、request的使用
我們在上面也實(shí)現(xiàn)了request()方法并且對Headers進(jìn)行了修改。下面我們介紹下request其他常用的一些功能,如下:
from mitmproxy import ctx def request(flow):request = flow.request info = ctx.log.info info(request.url) info(str(request.headers)) info(str(request.cookies)) info(request.host) info(request.method) info(str(request.port)) info(request.scheme)
在手機(jī)上打開百度,就可以看到pc端控制臺輸出了一系列的請求,在這里我們找到第一個請求。控制臺打印輸出了request的一些常見的屬性,如URL、headers、cookies、host、method、scheme即請求鏈接、請求頭、請求cookies、請求host、請求方法、請求端口、請求協(xié)議這些內(nèi)容。
同時我們還可以對任意屬性進(jìn)行修改,就像最初修改headers一樣,直接賦值即可,例如把請求的URL修改了,如下:‘
def request(flow): url =’https://httpbin.org/get’ flow.request.url = url
我們只需要用簡單的腳本就可以成功把請求修改為其他的站點(diǎn),通過這種方式修改和偽造請求就變得很容易。
通過這個例子我們也可以知道,有時候URL雖然是正確的,但是內(nèi)容并非是正確的,我們需要進(jìn)一步提高自己的安全防范意識。
所以我們能很容易地獲取和修改request的任意內(nèi)容,比如:可以用修改cookies、添加代理的方式來規(guī)避反爬。
4、響應(yīng)的使用
對于爬蟲來說,我們會更加關(guān)心響應(yīng)的內(nèi)容,因?yàn)閞esponse body才是爬取的結(jié)果。對于響應(yīng)來說,mitmdump也提供了對應(yīng)的處理接口,就是response()方法。
from mitmproxy import ctx def response(flow): response = flow.response info = ctx.log.infoinf(str(response.status_code))info(str(response.headers)) info(str(response.cookies)) info(str(response .text))
在這里打印輸出了響應(yīng)的狀態(tài)碼status_code、響應(yīng)頭headers、cookies、響應(yīng)體text這幾個屬性,其中最重要的是text屬性也就是網(wǎng)頁的源代碼。
通過response()方法獲取每個請求的響應(yīng)內(nèi)容,然后再進(jìn)行響應(yīng)的信息提取和存儲,我們就可以完成數(shù)據(jù)爬取啦!
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. PHP設(shè)計(jì)模式中工廠模式深入詳解2. 在JSP中使用formatNumber控制要顯示的小數(shù)位數(shù)方法3. ASP.NET Core實(shí)現(xiàn)中間件的幾種方式4. 得到XML文檔大小的方法5. ASP常用日期格式化函數(shù) FormatDate()6. 利用CSS3新特性創(chuàng)建透明邊框三角7. 將properties文件的配置設(shè)置為整個Web應(yīng)用的全局變量實(shí)現(xiàn)方法8. jsp實(shí)現(xiàn)textarea中的文字保存換行空格存到數(shù)據(jù)庫的方法9. XML入門的常見問題(二)10. 如何在jsp界面中插入圖片
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備