Spring Bean的包掃描的實(shí)現(xiàn)方法
我們知道,Spring可以通過(guò)包掃描將使用@Component注解定義的Bean定義到容器中。今天就來(lái)探究下他實(shí)現(xiàn)的原理。
首先,找到@Component注解的處理類注解的定義,一般都需要配套的對(duì)注解的處理才能完成注解所代表的功能。所以我們通過(guò)@Component注解的用到的地方,來(lái)查找可能的處理邏輯;我們先進(jìn)入Spring的項(xiàng)目,在IDEA里面用Ctrl和鼠標(biāo)左鍵點(diǎn)擊Component注解的名稱,IDEA會(huì)顯示出使用到這個(gè)類的位置,我們從彈出的列表中找到一個(gè)名稱像的類,去看類上面的注釋說(shuō)明,如圖:
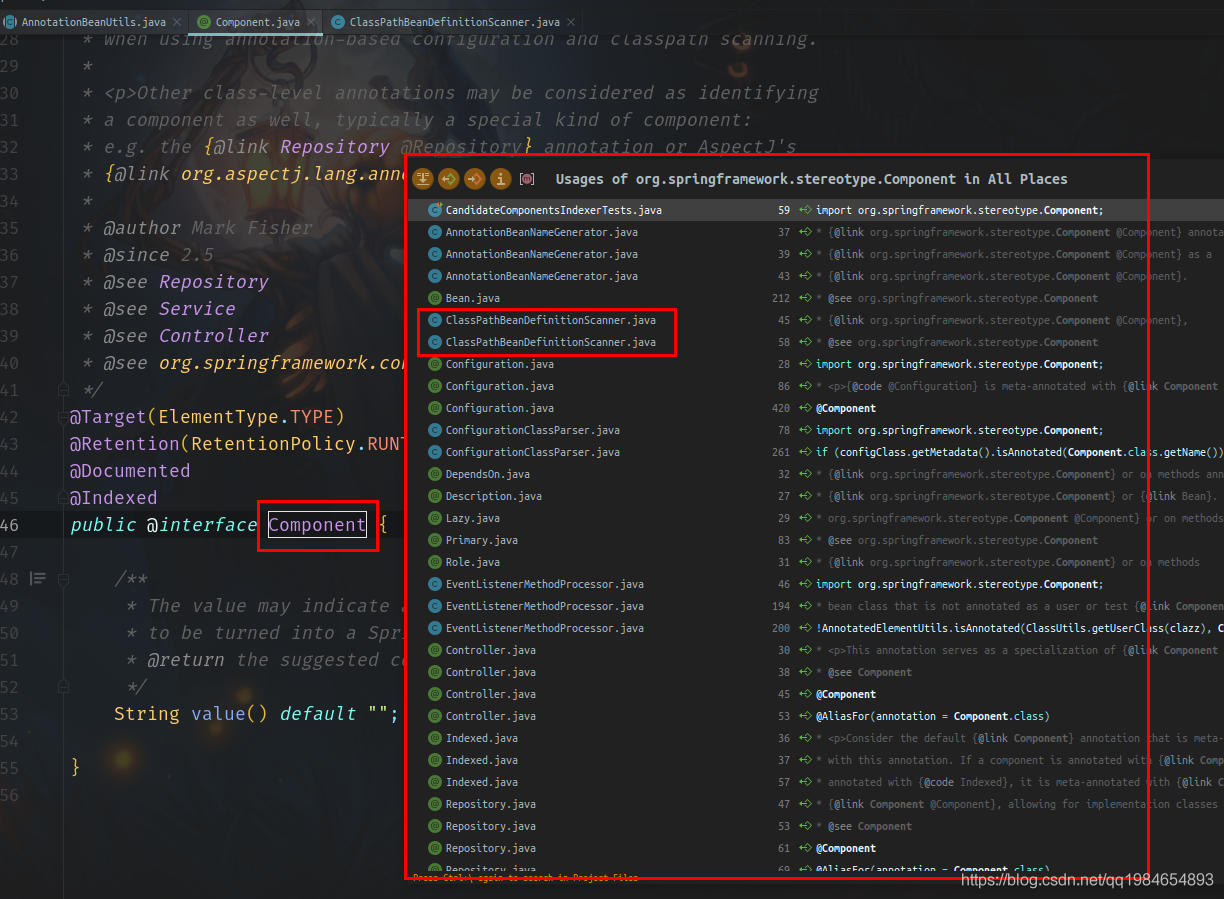
我們點(diǎn)進(jìn)類中,可以看到第一行就說(shuō)了這個(gè)類是為了從classpath里面找到定義的Bean:
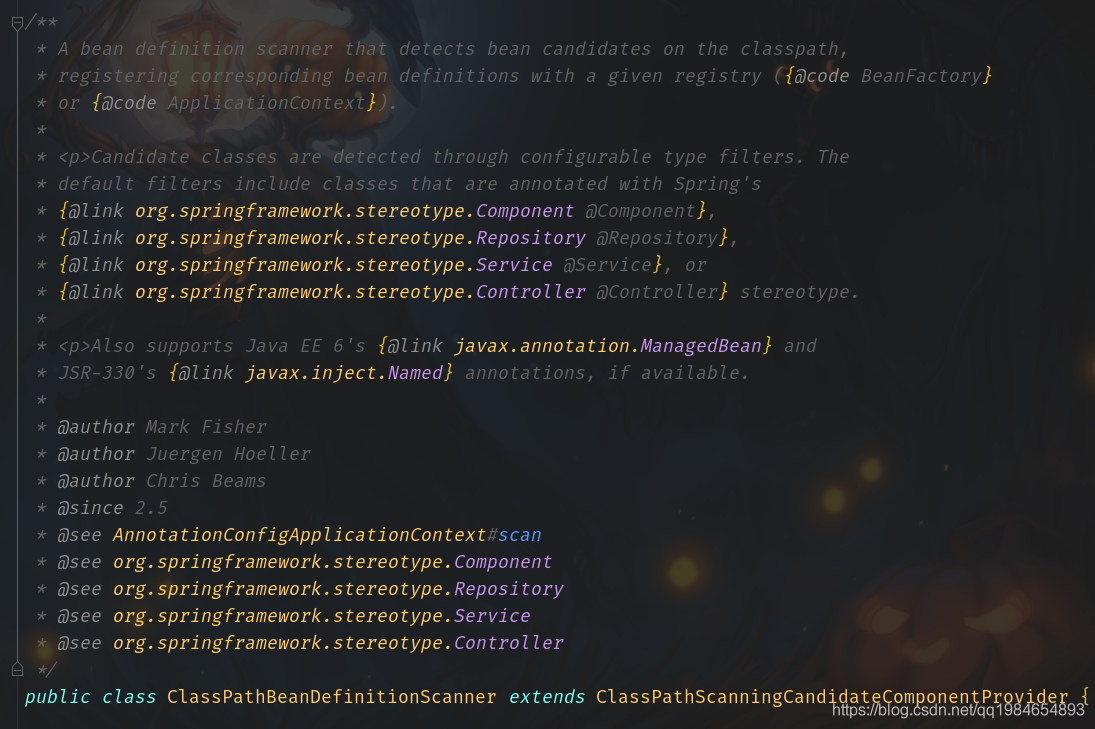
一般Spring的類都是經(jīng)過(guò)設(shè)計(jì)的,職責(zé)清晰。所以一般都是有簡(jiǎn)單直接的接口暴露,我們打開(kāi)類的公開(kāi)API可以看到有個(gè)很直接的方法就叫做掃描,看看注釋說(shuō)“從指定的包中掃描Bean”,那就是它了。
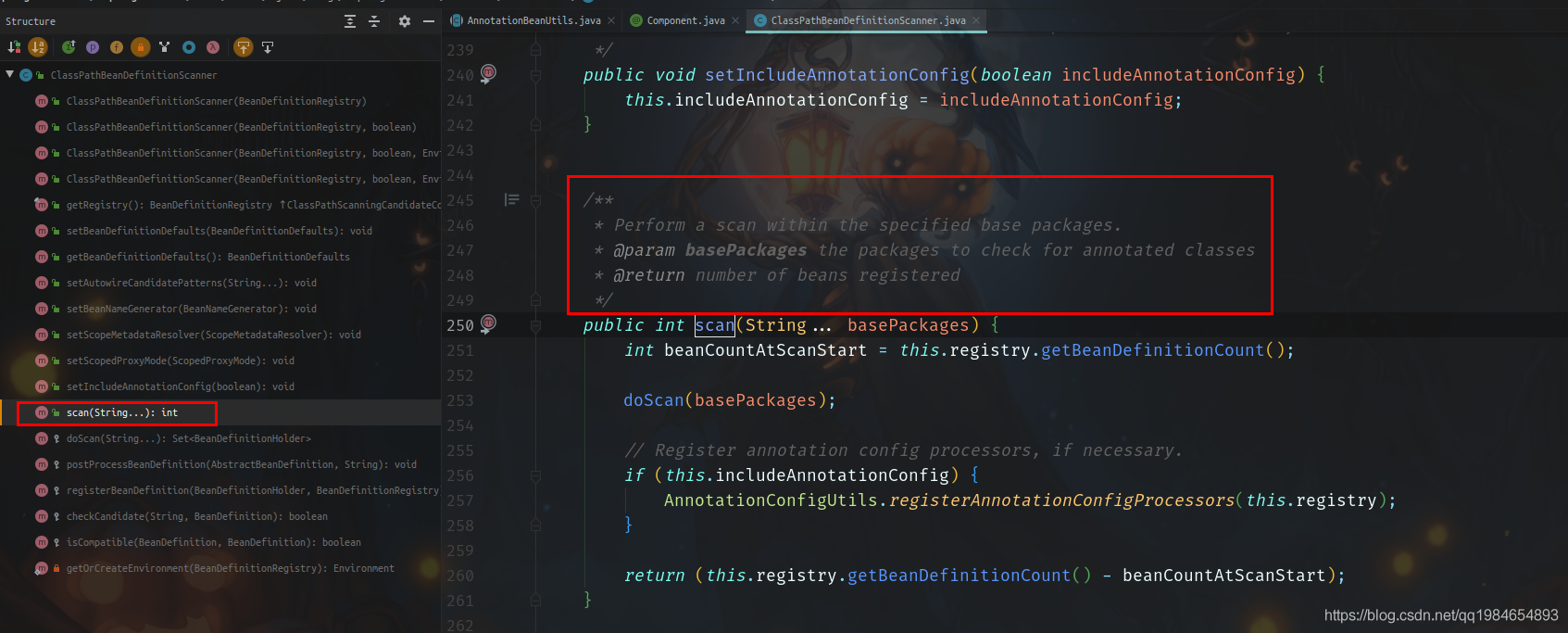
然后,我們?yōu)榱舜_認(rèn),實(shí)現(xiàn)確實(shí)是通過(guò)這個(gè)方法,可以啟動(dòng)程序,打個(gè)斷點(diǎn)看看是否經(jīng)過(guò)這里(但是這這里,沒(méi)有調(diào)用scan()方法,而是更深一層的doScan方法,也確實(shí)費(fèi)解)。
我們進(jìn)入doScan() 方法看看實(shí)現(xiàn):
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {Assert.notEmpty(basePackages, 'At least one base package must be specified');Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();// 可以指定多個(gè)basePackage,這里就對(duì)每個(gè)都處理for (String basePackage : basePackages) { // 這個(gè)方法是真正的查找候選Bean的地方Set<BeanDefinition> candidates = findCandidateComponents(basePackage);// 對(duì)于每個(gè)查找出的候選Bean,進(jìn)行處理for (BeanDefinition candidate : candidates) { // 解析@Scope的元數(shù)據(jù)ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);candidate.setScope(scopeMetadata.getScopeName());// 為候選的Bean生成一個(gè)名稱String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);// 應(yīng)用后置處理器if (candidate instanceof AbstractBeanDefinition) {postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);}// // 處理一些其它通用的注解的元數(shù)據(jù)if (candidate instanceof AnnotatedBeanDefinition) {AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);}// 校驗(yàn)通過(guò)后,注冊(cè)到 BeanFactoryif (checkCandidate(beanName, candidate)) {BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);registerBeanDefinition(definitionHolder, this.registry);}}}return beanDefinitions;}
從方法中我們可以明顯的看到,核心代碼還在findCandidateComponents方法里面,我們進(jìn)入這個(gè)方法后再通過(guò)調(diào)試一直找到核心代碼scanCandidateComponents。如下圖,第一處是找到指定包路徑所代表的classpath中的資源對(duì)象, 但是這里只是找到了包下面有什么,但是還不知道包下面的類是不是一個(gè)候選的Bean(可以看到將DTO類也掃描到了)。如下:
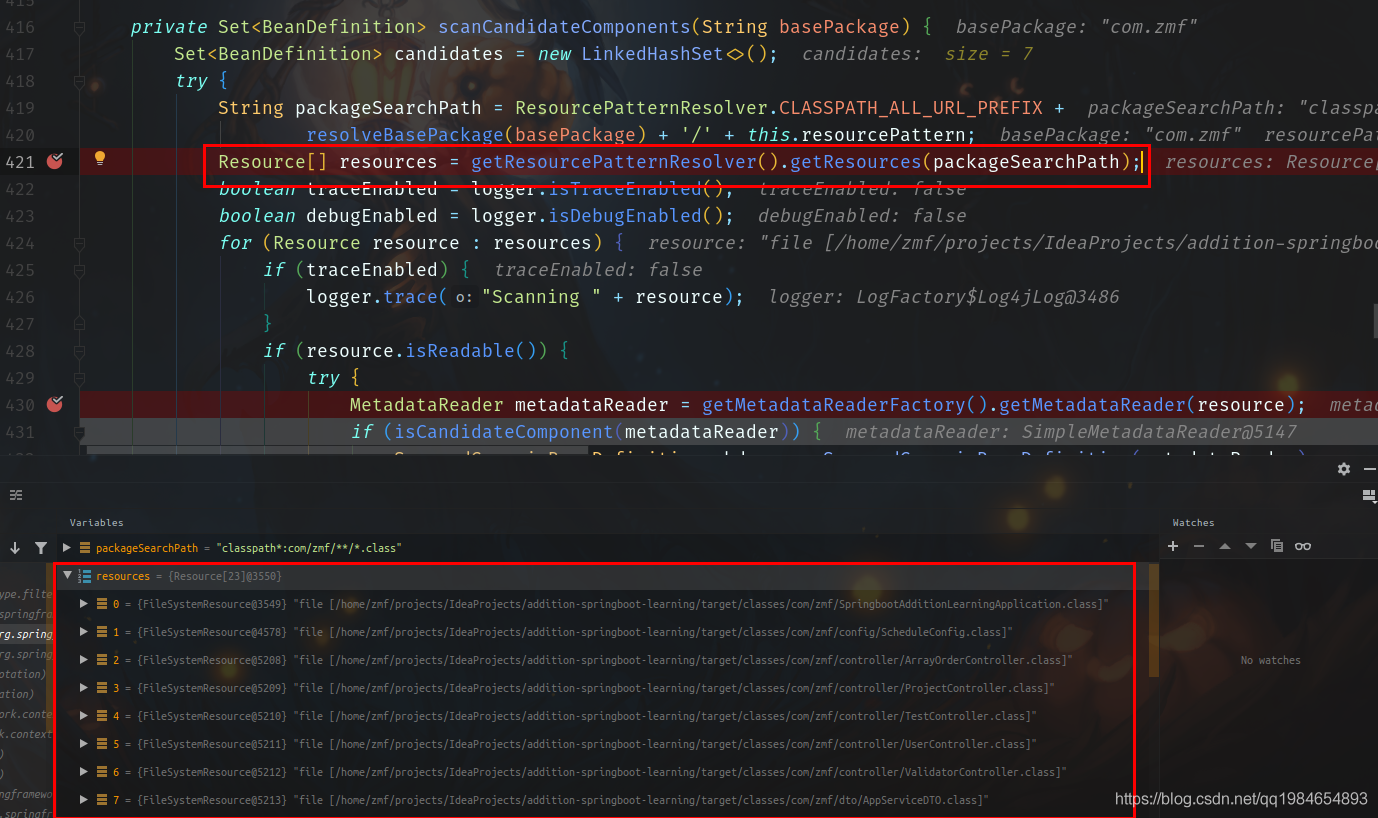
正常思路,拿到了有哪些資源就該進(jìn)一步去篩選,看看這些資源有哪些是真正的Bean的定義類。
現(xiàn)在我們還不清楚的是,Spring通過(guò)什么方式知道一個(gè)類是否是真正的Bean的。我們繼續(xù)調(diào)試,到上圖的430行debug進(jìn)去看看,可以走到org.springframework.core.type.classreading.SimpleMetadataReader這個(gè)類的構(gòu)造器中,如下:
SimpleMetadataReader(Resource resource, @Nullable ClassLoader classLoader) throws IOException { // 通過(guò)流讀取資源的內(nèi)容,現(xiàn)在這個(gè)資源可以認(rèn)為是我們的類InputStream is = new BufferedInputStream(resource.getInputStream());ClassReader classReader;try { // 這個(gè)Reader的構(gòu)造器中就將流讀取完畢了classReader = new ClassReader(is);}catch (IllegalArgumentException ex) { // 通過(guò)這個(gè)異常的信息,可以推測(cè)出,其實(shí)這里是通過(guò)ASM讀取Class文件的定義了throw new NestedIOException('ASM ClassReader failed to parse class file - ' +'probably due to a new Java class file version that isn’t supported yet: ' + resource, ex);}finally {is.close();} // 這里根據(jù)命名可以推測(cè)是訪問(wèn)者模式來(lái)暴露注解的元數(shù)據(jù)AnnotationMetadataReadingVisitor visitor = new AnnotationMetadataReadingVisitor(classLoader);// 這個(gè)accpect方法也是訪問(wèn)者模式中的典型方法,在這里面,是數(shù)據(jù)的解析邏輯classReader.accept(visitor, ClassReader.SKIP_DEBUG);this.annotationMetadata = visitor;// (since AnnotationMetadataReadingVisitor extends ClassMetadataReadingVisitor)this.classMetadata = visitor;this.resource = resource;}
我們?cè)谶M(jìn)入classReader.accept方法,這里面可以看到reader對(duì)于Class文件的的按字節(jié)解析。

例如,下面讀取的類聲明,類注解都是包掃描需要的類元數(shù)據(jù):
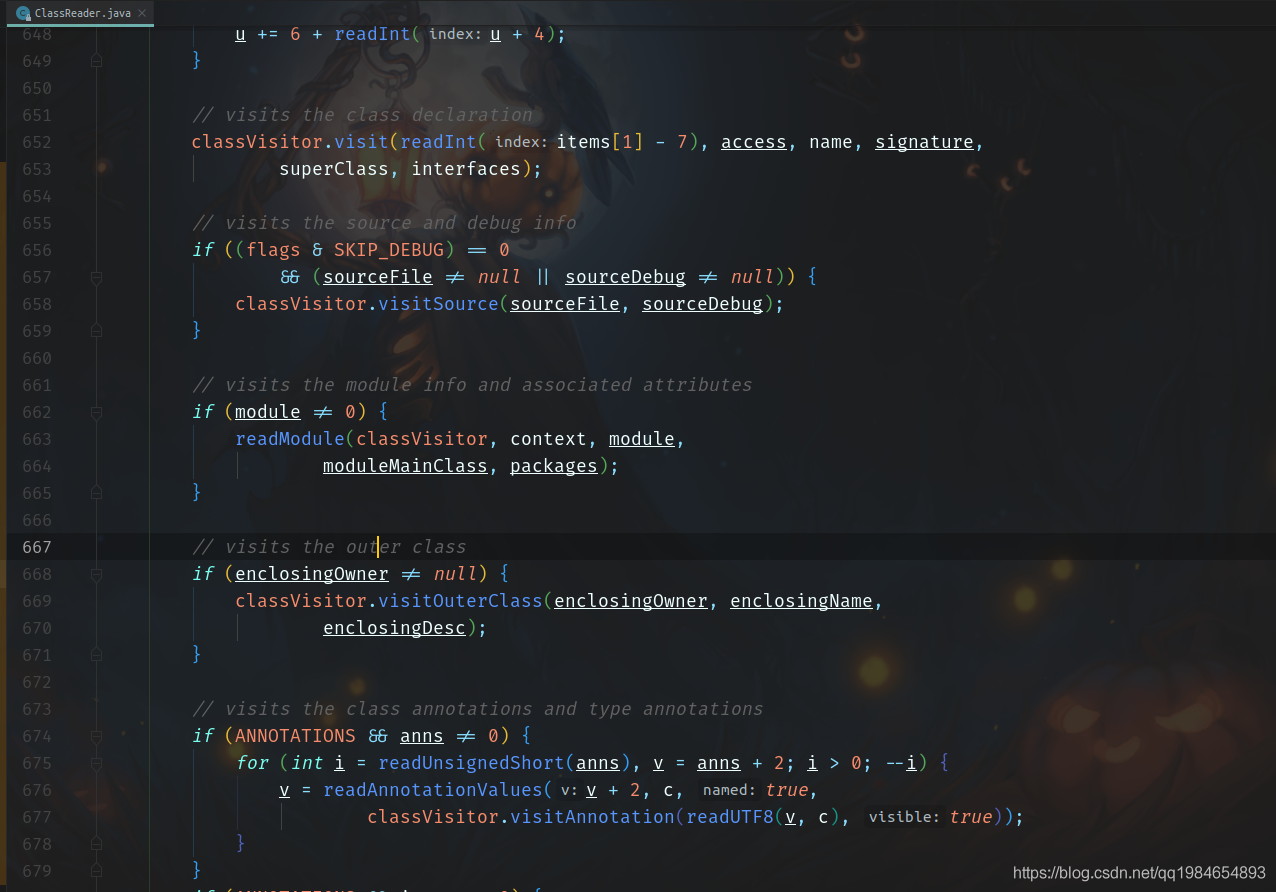
拿到這些元數(shù)據(jù)之后,就按照包掃描的過(guò)濾器就過(guò)濾出真正需要的類,作為候選的Bean
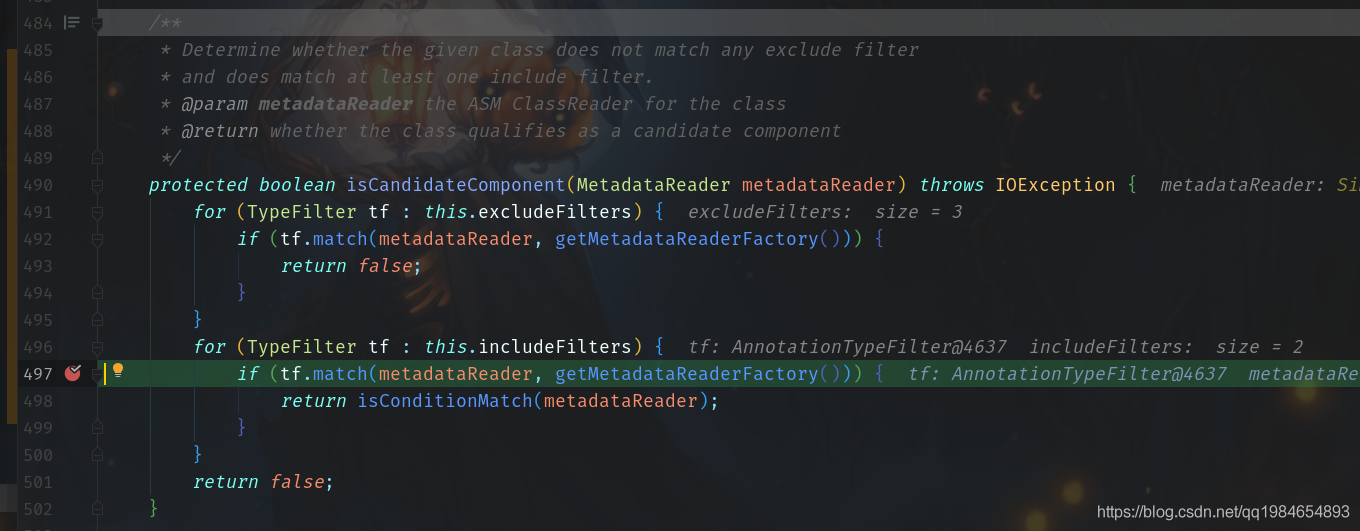
獲取到元數(shù)據(jù)之后,就可以按部就班對(duì)Bean進(jìn)行注冊(cè)、初始化等一系列邏輯啦~
總結(jié) 包掃描是通過(guò)讀取包對(duì)應(yīng)的類路徑下的class文件后,對(duì)class文件進(jìn)行解析元數(shù)據(jù)的方式,確定了Bean的定義的; 本地IDEA的啟動(dòng)方式可能和Jar包方式尋找資源的方式略有不同,但是思路是一致的,都是按照第一點(diǎn)查找;到此這篇關(guān)于Spring Bean的包掃描的實(shí)現(xiàn)方法的文章就介紹到這了,更多相關(guān)Spring Bean掃描包內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 使用Python和百度語(yǔ)音識(shí)別生成視頻字幕的實(shí)現(xiàn)2. Gitlab CI-CD自動(dòng)化部署SpringBoot項(xiàng)目的方法步驟3. ASP中解決“對(duì)象關(guān)閉時(shí),不允許操作。”的詭異問(wèn)題……4. IDEA版最新MyBatis程序配置教程詳解5. python pymysql鏈接數(shù)據(jù)庫(kù)查詢結(jié)果轉(zhuǎn)為Dataframe實(shí)例6. ASP刪除img標(biāo)簽的style屬性只保留src的正則函數(shù)7. idea設(shè)置自動(dòng)導(dǎo)入依賴的方法步驟8. 淺談SpringMVC jsp前臺(tái)獲取參數(shù)的方式 EL表達(dá)式9. 教你如何寫出可維護(hù)的JS代碼10. 詳解Java內(nèi)部類——匿名內(nèi)部類
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備