spring batch使用reader讀數(shù)據(jù)的內(nèi)存容量問題詳解
本篇博客是記錄使用spring batch做數(shù)據(jù)遷移時時遇到的一個關(guān)鍵問題:數(shù)據(jù)遷移量大時如何保證內(nèi)存。當我們在使用spring batch時,我們必須配置三個東西: reader,processor,和writer。其中,reader用于從數(shù)據(jù)庫中讀數(shù)據(jù),當數(shù)據(jù)量較小時,reader的邏輯不會對內(nèi)存帶來太多壓力,但是當我們要去讀的數(shù)據(jù)量非常大的時候,我們就不得不考慮內(nèi)存等方面的問題,因為若數(shù)據(jù)量非常大,內(nèi)存,執(zhí)行時間等等都會受到影響。關(guān)于spring batch的基礎(chǔ)知識和介紹請參考這篇博客:批處理框架spring batch介紹及使用。
問題是什么在上面的內(nèi)容當中我們已經(jīng)提到了,我們面臨的問題是數(shù)據(jù)遷移量大時的內(nèi)存問題。但是這樣的描述非常籠統(tǒng),因此博主決定將這一部分單獨拎出來說。
在學(xué)習(xí)了spring batch的知識之后我們應(yīng)該很清楚的一點是,每一個spring batch的step都包含如下的部分:

即讀數(shù)據(jù),處理數(shù)據(jù),寫數(shù)據(jù)。這三個步驟里面最可能會導(dǎo)致內(nèi)存變大問題的無疑是讀數(shù)據(jù)環(huán)節(jié)。讀數(shù)據(jù)作為spring batch的數(shù)據(jù)輸入,是整個spring batch job的開頭邏輯。
若我們的數(shù)據(jù)量不大,如只有幾十萬條,那我們無疑不會面臨內(nèi)存問題,即便一次將所有數(shù)據(jù)加載到內(nèi)存當中,占的內(nèi)存也不會非常多,且spring batch數(shù)據(jù)遷移的速度非常之快,幾十萬條的數(shù)據(jù)往往是幾十秒的時間就可以遷移完成。但是當數(shù)據(jù)量變大之后,問題就不一樣了。當我們的數(shù)據(jù)量達到數(shù)百萬或上千萬時,若一次性將所有數(shù)據(jù)全部讀到內(nèi)存當中,則會占據(jù)遠遠超出正常范圍的非常大的內(nèi)存。該問題示意圖如下所示:
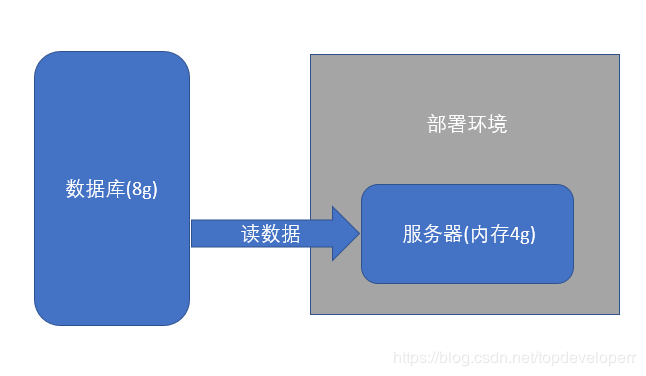
我們寫的任何程序都會有一個運行內(nèi)存,假設(shè)這個內(nèi)存的總?cè)萘楷F(xiàn)在只有4g,而我們數(shù)據(jù)庫里需要操作的數(shù)據(jù)有8g,那么無疑,一次性的將數(shù)據(jù)讀出來就會出錯。這便是需要考慮得問題。
Spring提供的reader實現(xiàn)spring提供了非常豐富的Reader實現(xiàn),其中比較常用的從數(shù)據(jù)庫讀數(shù)據(jù)的有JdbcCursorItemReader,JdbcPagingItemReader等。
JdbcCursorItemReader使用JdbcCursorItemReader的示例代碼如下:
@Beanpublic JdbcCursorItemReader<CustomerCredit> itemReader() { return new JdbcCursorItemReaderBuilder<CustomerCredit>() .dataSource(this.dataSource) .name('creditReader') .sql('select ID, NAME, CREDIT from CUSTOMER') .rowMapper(new CustomerCreditRowMapper()) .build(); }
JdbcCursorItemReader的好處在于使用簡單,但是我們從它的sql就能發(fā)現(xiàn),JdbcCursorItemReader會一次把所有的數(shù)據(jù)全部拿回來,當數(shù)據(jù)量過大而服務(wù)器內(nèi)存不夠時,就會遇到下面無法分配內(nèi)存的問題:

報錯信息為:Resource exhaustion event:The JVM was unable to allocate memory from the heap. 意思就是需要分配內(nèi)存的數(shù)據(jù)太多,但是無法找到足夠的內(nèi)存了。
反映在內(nèi)存里,堆內(nèi)存會呈現(xiàn)出如下的情況:
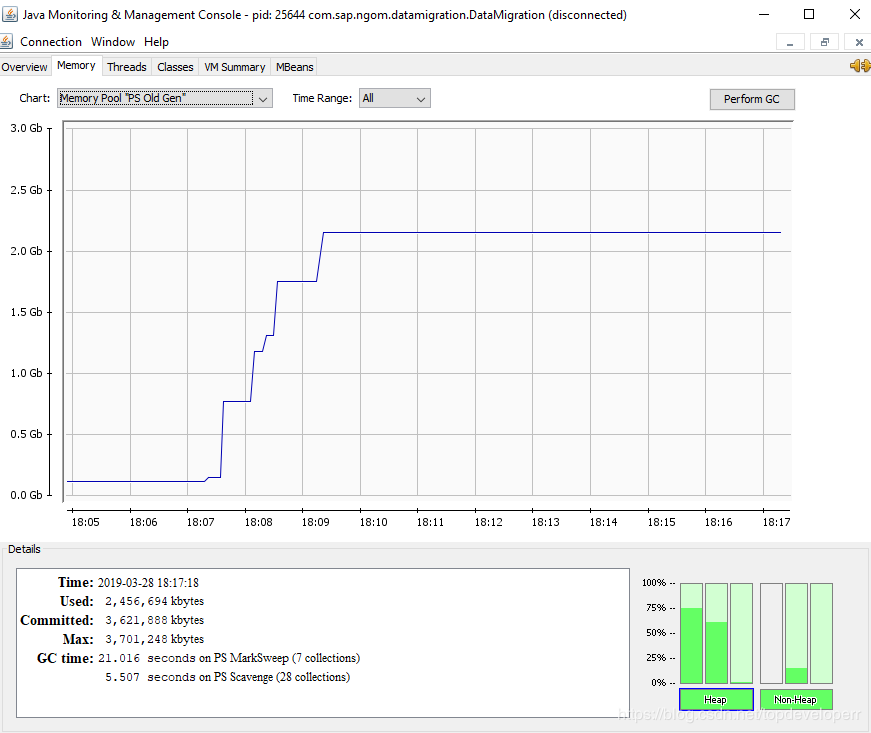
隨著每一次數(shù)據(jù)讀入,堆內(nèi)存都會增大,原因就在于JdbcCursorItemReader一次性讀回了所有的數(shù)據(jù),返回之后就會存在一個對象里面,而這個對象的尺寸過大,因此直接進入了老年代。在數(shù)據(jù)遷移完成之前,這些數(shù)據(jù)都不會被回收。如下圖所示:
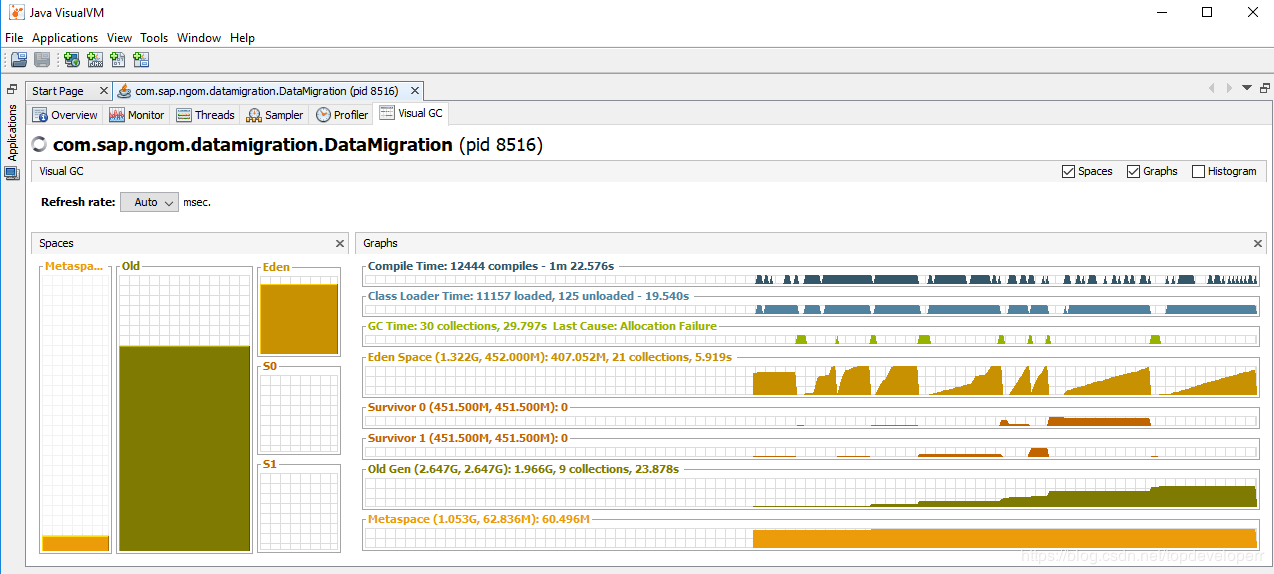
毫無疑問,當我們的數(shù)據(jù)量大時不應(yīng)該使用這種類型的reader來讀取數(shù)據(jù)。
JdbcPagingItemReaderJdbcPagingItemReader的作用和它的名字一樣,它可以分頁讀取數(shù)據(jù),但是使用起來相比于JdbcCursorItemReader更加復(fù)雜,示例代碼如下:
@Beanpublic JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) { Map<String, Object> parameterValues = new HashMap<>(); parameterValues.put('status', 'NEW'); return new JdbcPagingItemReaderBuilder<CustomerCredit>() .name('creditReader') .dataSource(dataSource) .queryProvider(queryProvider) .parameterValues(parameterValues) .rowMapper(customerCreditMapper()) .pageSize(1000) .build();} @Beanpublic SqlPagingQueryProviderFactoryBean queryProvider() { SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean(); provider.setSelectClause('select id, name, credit'); provider.setFromClause('from customer'); provider.setWhereClause('where status=:status'); provider.setSortKey('id'); return provider;}
可以看到我們能夠設(shè)置page的大小,JdbcPagingItemReader將根據(jù)這個頁的大小,每次讀取這么多的數(shù)據(jù),因此這些數(shù)據(jù)返回保存的對象,就只會是小對象,因此他們不會直接在老年代里分配,而是先分配在年輕代,隨著年輕代不斷變大,minor gc也不斷進行,回收掉已經(jīng)處理完的數(shù)據(jù),老年代的內(nèi)存使用量不會有任何增大,類似下圖:
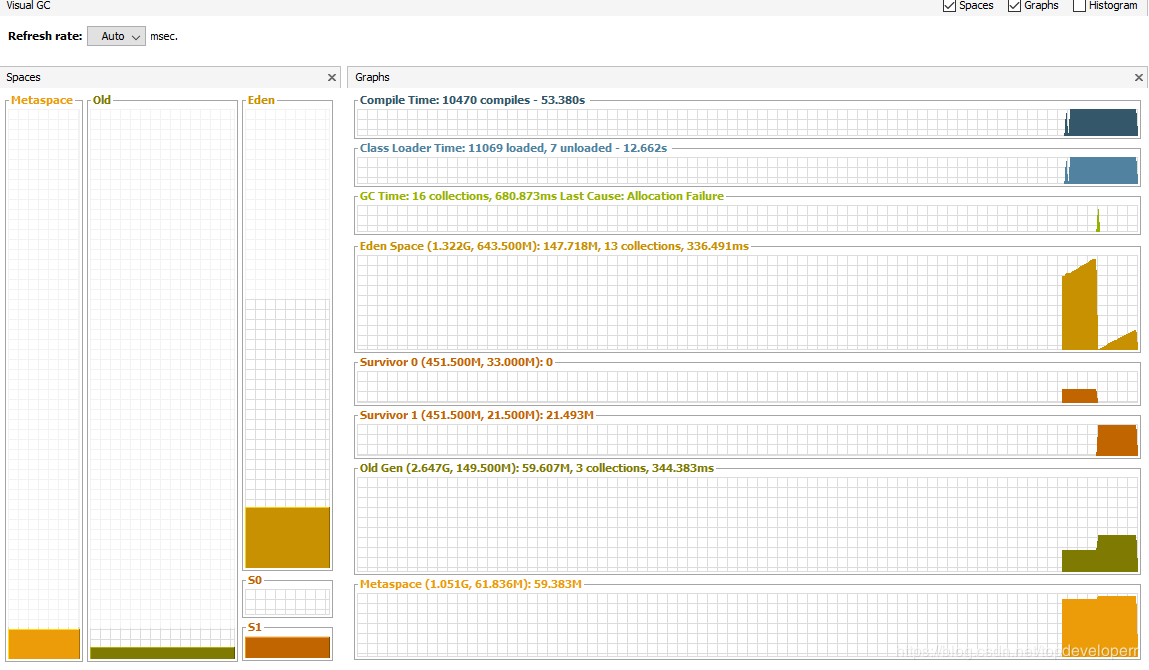
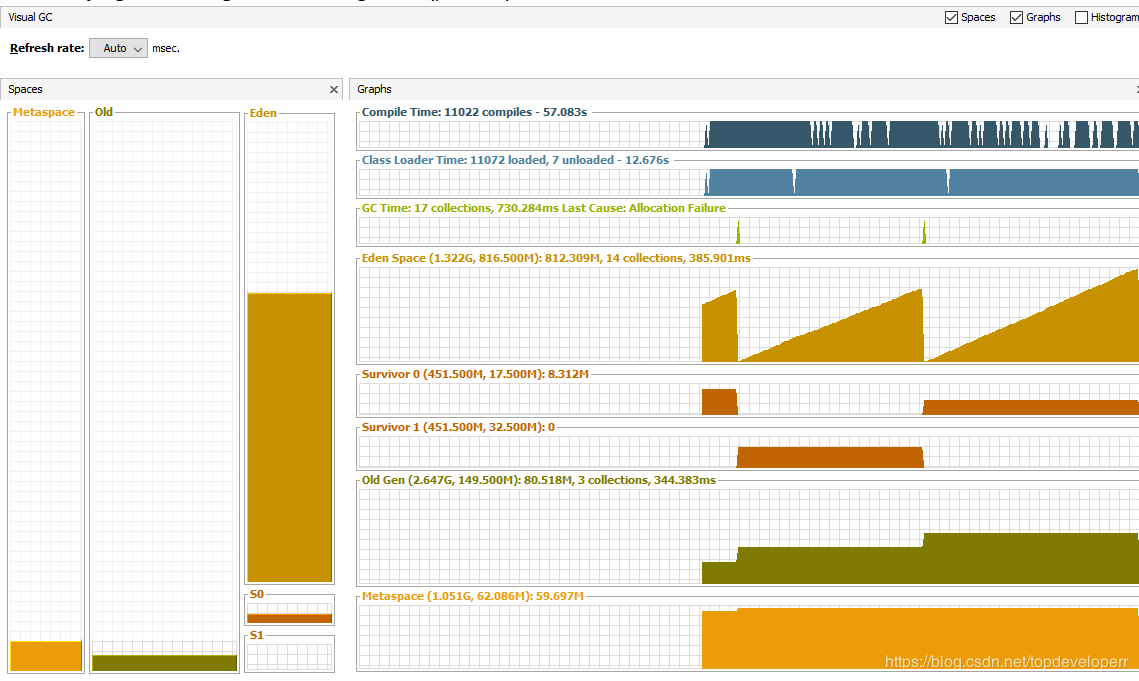
老年代內(nèi)存不會有任何變化,年輕帶會隨著服務(wù)器數(shù)據(jù)遷移進行而增大同時被回收。
在使用JdbcPagingItemReader時,有一個必須注意的地方就是排序關(guān)鍵字是必須指定的,原因在于排序是分頁實現(xiàn)原理的技術(shù)基礎(chǔ)。sortKey和我們指定的其他字句一起構(gòu)建出SQL語句出來。在sortKey上必須使用unique key constraint約束,因為只有這樣才能得以確保執(zhí)行之間不會丟失任何數(shù)據(jù)。這也可以說是JdbcCursorItemReader相對便利的一點優(yōu)勢。
總結(jié)數(shù)據(jù)量小時選擇的方案差別不會很大,當數(shù)據(jù)量大時,為了有好的內(nèi)存表現(xiàn)則使用分頁的reader是必要的。但同時,因為要實現(xiàn)分頁,也會帶來一些不可避免的限制。
到此這篇關(guān)于spring batch使用reader讀數(shù)據(jù)的內(nèi)存容量問題詳解的文章就介紹到這了,更多相關(guān)spring batch使用reader讀數(shù)據(jù)內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備