深入理解Javascript--作用域和賦值操作
作用域作為一個最基礎的功能存在于各種編程語言中,它使得我們的編程更加靈活有趣。其基礎功能就是存儲變量中的值,然后可以對值進行訪問和修改。
可能我們都知道作用域的一些概念,以及其一些擴展的一些內容閉包等,但是相對于這些可能我們去了解這些變量到底是存到了哪里,而我們的程序是如何訪問到他們的會更加有趣。
var a = 1;
首先我們要了解到在我們進行聲明變量并進行賦值的時候到底誰參與了我們的整個流程。
1,引擎:它參與了整個JS程序的編譯和執行。
2,編譯器:它負責了語法分析和代碼的生成。
3,作用域:它負責手機并維護所有的標識符也就(變量)組成的一系列查詢,并對此實施了一套十分嚴格的規則,確定當前執行的代碼對這些標識符的訪問權限。
當引擎看到var a =1;的時候它和我們所想的是不一樣的,我們想這是一個聲明,他所認為的其實是這里有倆完全不同的聲明,一個由編譯器在編譯的時候處理,另一個則由引擎在運行時候處理。那我們看看他們到底是怎么工作的。
編譯器會先講var a = 1;這段程序分解成詞法單元,然后將詞法單元解析成一個樹結構,但是當編譯器開始進行代碼生成的時候,他對這段程序的處理方式會有所不同。
在我們理解的范圍內,編譯器是這樣工作的:為一個變量分配內存,將其命名為a,然后講值1保存進這個變量,但事實是不同的。
1,遇到 var a 的時候,編譯器會先詢問作用域是否已經有一個該名稱的變量存在于同一個作用域的集合中。如果是,編譯器就會忽略該聲明并繼續進行編譯,不然的話他會要求作用域在當前作用域的集合中聲明一個變量命名為a。
2,然后編譯器開始為引擎生成運行所需的代碼,這些代碼會被用來處理 a = 1 這個賦值的操作。然后引擎運行,它會先詢問作用域,當前作用域集合中是否存在了一個叫a的變量,如果是引擎就會使用這個變量,如果否,引擎會繼續在當前作用域的上級作用域查找該變量。最后只要找到了a,引擎就會把1賦值給它,如果沒有找到,引擎就會拋出一個異常。
所以說:在新變量的賦值中存在兩個操作,第一個是編譯器聲明變量,第二個就是引擎在作用域中查找該變量,并對其賦值。
下面看一段簡單的代碼
function demo(a){console.log(a) }demo(2);
在繼續說之前,我們先看看LHS和RHS,顧名思義,一個左一個右。這是引擎對變量所用的兩個查詢,L和R代表的是一個賦值的左側和右側(大部分情況下),也就是說當變量出現在賦值的左側時進行LHS查詢,出現在右側時進行RHS查詢。但是更確切的說法其實是RHS查詢只是簡單的查找某個變量的值,而LHS查詢則是找到變量的容器本身,從而對其進行賦值操作。那么根據這個說法,我們可以發現RHS其實代表的應該是“非左側”。我們看一個簡單代碼。
var a = 1; console.log(a);
在上面的代碼中,var a =1;對a的引用是一個LHS引用,而console.log(a)的a其實就是一個RHS引用。再看一個例子:
function demo(a){console.log(a); }demo(1);
上面的代碼中其實包含了RHS和LHS引用。我們理解下demo(1);的意思,它其實意味著RHS引用demo這個值,(...)意味著它需要被執行,而在執行的過程中,有一個隱式的LRS引用 a = 1; 這個查詢發生在參數傳遞的過程中。其中的console.log(a)也是個RHS引用。
同時我們需要知道,不成功的RHS會導致拋出一個異常,而不成功的LHS引用會導致自動隱式的創建一個全局變量(非嚴格模式),或者拋出異常(嚴格模式)。
作用域的嵌套當一個塊或者函數嵌套在另一個塊或者函數內時,就發生了作用域的嵌套。因此,當在當前作用域中無法找到該變量時,引擎就會在外層嵌套的作用域中繼續查找(若一直沒有找到會到達全局作用域),直到找到該變量。
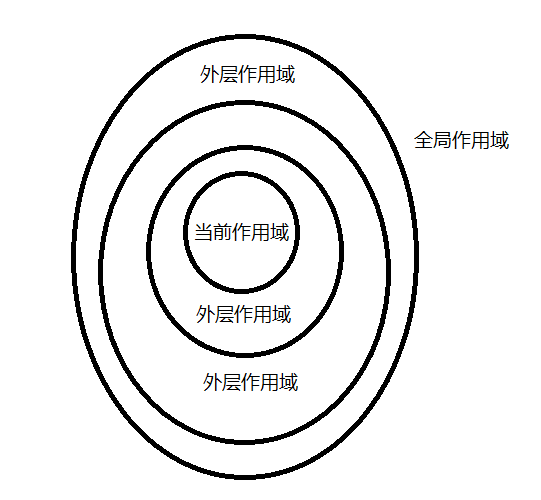
上圖一層一層往外形成的結構就是我們常說的作用域鏈,最內層代表當前執行環境的作用域,最外層代表全局作用域。LHS和RHS都會在當前作用域進行查找,如果沒有找到,就會向外,以此類推,如果到達全局作用域都沒有找到,那無論如何這個查找過程都會停止。
來自:http://www.cnblogs.com/xiaoloulan/p/5961528.html
相關文章:
 網公網安備
網公網安備