python 多線程實現(xiàn)多任務(wù)的方法示例
進程是操作系統(tǒng)分配程序執(zhí)行資源的單位,而線程是進程的一個實體,是CPU調(diào)度和分配的單位。一個進程肯定有一個主線程,我們可以在一個進程里創(chuàng)建多個線程來實現(xiàn)多任務(wù)。
1.2 一個程序?qū)崿F(xiàn)多任務(wù)的方法實現(xiàn)多任務(wù),我們可以用幾種方法。
(1)在主進程里面開啟多個子進程,主進程和多個子進程一起處理任務(wù)。
(2)在主進程里開啟多個子線程,主線程和多個子線程一起處理任務(wù)。
(3)在主進程里開啟多個協(xié)程,多個協(xié)程一起處理任務(wù)。
注意:因為用多個線程一起處理任務(wù),會產(chǎn)生線程安全問題,所以在開發(fā)中一般使用多進程+多協(xié)程來實現(xiàn)多任務(wù)。
1.3 多線程的創(chuàng)建方式1.3.1 創(chuàng)建threading.Thread對象import threadingp1 = threading.Thread(target=[函數(shù)名],args=([要傳入函數(shù)的參數(shù)]))p1.start() # 啟動p1線程
我們來模擬一下多線程實現(xiàn)多任務(wù)。
假如你在用網(wǎng)易云音樂一邊聽歌一邊下載。網(wǎng)易云音樂就是一個進程。假設(shè)網(wǎng)易云音樂內(nèi)部程序是用多線程來實現(xiàn)多任務(wù)的,網(wǎng)易云音樂開兩個子線程。一個用來緩存音樂,用于現(xiàn)在的播放。一個用來下載用戶要下載的音樂的。這時候的代碼框架是這樣的:
import threadingimport time def listen_music(name): while True:time.sleep(1)print(name,'正在播放音樂') def download_music(name): while True:time.sleep(2)print(name,'正在下載音樂') if __name__ == ’__main__’: p1 = threading.Thread(target=listen_music,args=('網(wǎng)易云音樂',)) p2 = threading.Thread(target=download_music,args=('網(wǎng)易云音樂',)) p1.start() p2.start()
輸出:
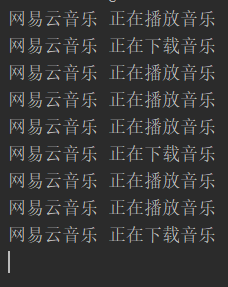
觀察上面的輸出代碼可以知道:
CPU是按照時間片輪詢的方式來執(zhí)行子線程的。cpu內(nèi)部會合理分配時間片。時間片到a程序的時候,a程序如果在休眠,就會自動切換到b程序。
嚴謹來說,CPU在某個時間點,只在執(zhí)行一個任務(wù),但是由于CPU運行速度和切換速度快,因為看起來像多個任務(wù)在一起執(zhí)行而已。
1.3.2 繼承threading.Thread,并重寫run除了上面的方法創(chuàng)建線程,還有另一種方法。可以編寫一個類,繼承threaing.Thread類,然后重寫父類的run方法。
import threadingimport time class MyThread(threading.Thread): def run(self):for i in range(5): time.sleep(1) print(self.name,i) t1 = MyThread()t2 = MyThread()t3 = MyThread()t1.start()t2.start()t3.start()
輸出:

運行時無序的,說明已經(jīng)啟用了多任務(wù)。
下面是threading.Thread提供的線程對象方法和屬性:
start():創(chuàng)建線程后通過start啟動線程,等待CPU調(diào)度,為run函數(shù)執(zhí)行做準(zhǔn)備; run():線程開始執(zhí)行的入口函數(shù),函數(shù)體中會調(diào)用用戶編寫的target函數(shù),或者執(zhí)行被重載的run函數(shù); join([timeout]):阻塞掛起調(diào)用該函數(shù)的線程,直到被調(diào)用線程執(zhí)行完成或超時。通常會在主線程中調(diào)用該方法,等待其他線程執(zhí)行完成。 name、getName()&setName():線程名稱相關(guān)的操作; ident:整數(shù)類型的線程標(biāo)識符,線程開始執(zhí)行前(調(diào)用start之前)為None; isAlive()、is_alive():start函數(shù)執(zhí)行之后到run函數(shù)執(zhí)行完之前都為True; daemon、isDaemon()&setDaemon():守護線程相關(guān); 1.4 線程何時開啟,何時結(jié)束(1)子線程何時開啟,何時運行 當(dāng)調(diào)用thread.start()時 開啟線程,再運行線程的代碼
(2)子線程何時結(jié)束 子線程把target指向的函數(shù)中的語句執(zhí)行完畢后,或者線程中的run函數(shù)代碼執(zhí)行完畢后,立即結(jié)束當(dāng)前子線程
(3)查看當(dāng)前線程數(shù)量 通過threading.enumerate()可枚舉當(dāng)前運行的所有線程
(4)主線程何時結(jié)束 所有子線程執(zhí)行完畢后,主線程才結(jié)束
示例一:
import threadingimport time def run(): for i in range(5):time.sleep(1)print(i) t1 = threading.Thread(target=run)t1.start()print('我會在哪里出現(xiàn)')
輸出:
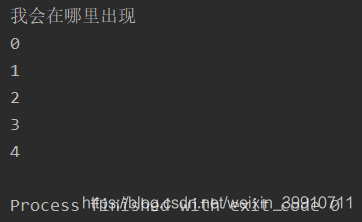
為什么主進程(主線程)的代碼會先出現(xiàn)呢?因為CPU采用時間片輪詢的方式,如果輪詢到子線程,發(fā)現(xiàn)他要休眠1s,他會先去運行主線程。所以說CPU的時間片輪詢方式可以保證CPU的最佳運行。
那如果我想主進程輸出的那句話運行在結(jié)尾呢?該怎么辦呢?這時候就需要用到 join() 方法了。
1.5 線程的 join() 方法import threadingimport time def run(): for i in range(5):time.sleep(1)print(i) t1 = threading.Thread(target=run)t1.start()t1.join() print('我會在哪里出現(xiàn)')
輸出:
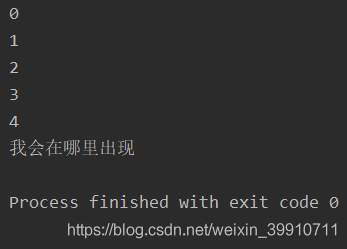
join() 方法可以阻塞主線程(注意只能阻塞主線程,其他子線程是不能阻塞的),直到 t1 子線程執(zhí)行完,再解阻塞。
1.6 多線程共享全局變量出現(xiàn)的問題我們開兩個子線程,全局變量是0,我們每個線程對他自加1,每個線程加一百萬次,這時候就會出現(xiàn)問題了,來,看代碼:
import threadingimport time num = 0 def work1(loop): global num for i in range(loop):# 等價于 num += 1temp = numnum = temp + 1 print(num) def work2(loop): global num for i in range(loop):# 等價于 num += 1temp = numnum = temp + 1 print(num) if __name__ == ’__main__’: t1 = threading.Thread(target=work1,args=(1000000,)) t2 = threading.Thread(target=work2, args=(1000000,)) t1.start() t2.start() while len(threading.enumerate()) != 1:time.sleep(1) print(num)
輸出
1459526 # 第一個子線程結(jié)束后全局變量一共加到這個數(shù)1588806 # 第二個子線程結(jié)束后全局變量一共加到這個數(shù)1588806 # 兩個線程都結(jié)束后,全局變量一共加到這個數(shù)
奇怪了,我不是每個線程都自加一百萬次嗎?照理來說,應(yīng)該最后的結(jié)果是200萬才對的呀。問題出在哪里呢?
我們知道CPU是采用時間片輪詢的方式進行幾個線程的執(zhí)行。
假設(shè)我CPU先輪詢到work1(),num此時為100,在我運行到第10行時,時間結(jié)束了!此時,賦值了,但是還沒有自加!即temp=100,num=100。
然后,時間片輪詢到了work2(),進行賦值自加。num=101了。
又回到work1()的斷點處,num=temp+1,temp=100,所以num=101。
就這樣!num少了一次自加!在次數(shù)多了之后,這樣的錯誤積累在一起,結(jié)果只得到158806!
這就是線程安全問題!
1.7 互斥鎖可以彌補部分線程安全問題。(互斥鎖和GIL鎖是不一樣的東西!)當(dāng)多個線程幾乎同時修改某一個共享數(shù)據(jù)的時候,需要進行同步控制
線程同步能夠保證多個線程安全訪問競爭資源,最簡單的同步機制是引入互斥鎖。
互斥鎖為資源引入一個狀態(tài):鎖定/非鎖定
某個線程要更改共享數(shù)據(jù)時,先將其鎖定,此時資源的狀態(tài)為“鎖定”,其他線程不能更改;直到該線程釋放資源,將資源的狀態(tài)變成“非鎖定”,其他的線程才能再次鎖定該資源。互斥鎖保證了每次只有一個線程進行寫入操作,從而保證了多線程情況下數(shù)據(jù)的正確性。
互斥鎖有三個常用步驟:
lock = threading.Lock() # 取得鎖lock.acquire() # 上鎖lock.release() # 解鎖
下面讓我們用互斥鎖來解決上面例子的線程安全問題。
import threadingimport time num = 0lock = threading.Lock() # 取得鎖def work1(loop): global num for i in range(loop):# 等價于 num += 1lock.acquire() # 上鎖temp = numnum = temp + 1lock.release() # 解鎖 print(num) def work2(loop): global num for i in range(loop):# 等價于 num += 1lock.acquire() # 上鎖temp = numnum = temp + 1lock.release() # 解鎖 print(num) if __name__ == ’__main__’: t1 = threading.Thread(target=work1,args=(1000000,)) t2 = threading.Thread(target=work2, args=(1000000,)) t1.start() t2.start() while len(threading.enumerate()) != 1:time.sleep(1) print(num)
輸出:
1945267 # 第一個子線程結(jié)束后全局變量一共加到這個數(shù)2000000 # 第二個子線程結(jié)束后全局變量一共加到這個數(shù)2000000 # 兩個線程都結(jié)束后,全局變量一共加到這個數(shù)
1.8 線程池ThreadPoolExecutor從Python3.2開始,標(biāo)準(zhǔn)庫為我們提供了concurrent.futures模塊,它提供了ThreadPoolExecutor和ProcessPoolExecutor兩個類,實現(xiàn)了對threading和multiprocessing的進一步抽象(這里主要關(guān)注線程池),不僅可以幫我們自動調(diào)度線程,還可以做到:
主線程可以獲取某一個線程(或者任務(wù)的)的狀態(tài),以及返回值。 當(dāng)一個線程完成的時候,主線程能夠立即知道。 讓多線程和多進程的編碼接口一致。1.8.1 創(chuàng)建線程池示例:
from concurrent.futures import ThreadPoolExecutorimport time # 參數(shù)times用來模擬網(wǎng)絡(luò)請求的時間def get_html(times): time.sleep(times) print('get page {}s finished'.format(times)) return times executor = ThreadPoolExecutor(max_workers=2)# 通過submit函數(shù)提交執(zhí)行的函數(shù)到線程池中,submit函數(shù)立即返回,不阻塞task1 = executor.submit(get_html, (3))task2 = executor.submit(get_html, (2))# done方法用于判定某個任務(wù)是否完成print('1: ', task1.done())# cancel方法用于取消某個任務(wù),該任務(wù)沒有放入線程池中才能取消成功print('2: ', task2.cancel())time.sleep(4)print('3: ', task1.done())# result方法可以獲取task的執(zhí)行結(jié)果print('4: ', task1.result())
輸出:
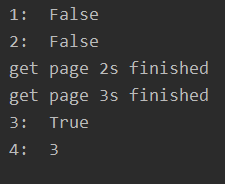
上面雖然提供了判斷任務(wù)是否結(jié)束的方法,但是不能在主線程中一直判斷啊。有時候我們是得知某個任務(wù)結(jié)束了,就去獲取結(jié)果,而不是一直判斷每個任務(wù)有沒有結(jié)束。這是就可以使用as_completed方法一次取出所有任務(wù)的結(jié)果。
from concurrent.futures import ThreadPoolExecutor, as_completedimport time # 參數(shù)times用來模擬網(wǎng)絡(luò)請求的時間def get_html(times): time.sleep(times) print('get page {}s finished'.format(times)) return times executor = ThreadPoolExecutor(max_workers=2)urls = [3, 2, 4] # 并不是真的urlall_task = [executor.submit(get_html, (url)) for url in urls] for future in as_completed(all_task): data = future.result() print('in main: get page {}s success'.format(data)) # 執(zhí)行結(jié)果# get page 2s finished# in main: get page 2s success# get page 3s finished# in main: get page 3s success# get page 4s finished# in main: get page 4s success
as_completed()方法是一個生成器,在沒有任務(wù)完成的時候,會阻塞,在有某個任務(wù)完成的時候,會yield這個任務(wù),就能執(zhí)行for循環(huán)下面的語句,然后繼續(xù)阻塞住,循環(huán)到所有的任務(wù)結(jié)束。從結(jié)果也可以看出,先完成的任務(wù)會先通知主線程。
1.8.3 map除了上面的as_completed方法,還可以使用executor.map方法,但是有一點不同。
from concurrent.futures import ThreadPoolExecutorimport time # 參數(shù)times用來模擬網(wǎng)絡(luò)請求的時間def get_html(times): time.sleep(times) print('get page {}s finished'.format(times)) return times executor = ThreadPoolExecutor(max_workers=2)urls = [3, 2, 4] # 并不是真的url for data in executor.map(get_html, urls): print('in main: get page {}s success'.format(data))# 執(zhí)行結(jié)果# get page 2s finished# get page 3s finished# in main: get page 3s success# in main: get page 2s success# get page 4s finished# in main: get page 4s success
使用map方法,無需提前使用submit方法,map方法與python標(biāo)準(zhǔn)庫中的map含義相同,都是將序列中的每個元素都執(zhí)行同一個函數(shù)。上面的代碼就是對urls的每個元素都執(zhí)行g(shù)et_html函數(shù),并分配各線程池。可以看到執(zhí)行結(jié)果與上面的as_completed方法的結(jié)果不同,輸出順序和urls列表的順序相同,就算2s的任務(wù)先執(zhí)行完成,也會先打印出3s的任務(wù)先完成,再打印2s的任務(wù)完成。
1.8.4 waitwait方法可以讓主線程阻塞,直到滿足設(shè)定的要求。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETEDimport time # 參數(shù)times用來模擬網(wǎng)絡(luò)請求的時間def get_html(times): time.sleep(times) print('get page {}s finished'.format(times)) return times executor = ThreadPoolExecutor(max_workers=2)urls = [3, 2, 4] # 并不是真的urlall_task = [executor.submit(get_html, (url)) for url in urls]wait(all_task, return_when=ALL_COMPLETED)print('main')# 執(zhí)行結(jié)果 # get page 2s finished# get page 3s finished# get page 4s finished# main
wait方法接收3個參數(shù),等待的任務(wù)序列、超時時間以及等待條件。等待條件return_when默認為ALL_COMPLETED,表明要等待所有的任務(wù)都結(jié)束。可以看到運行結(jié)果中,確實是所有任務(wù)都完成了,主線程才打印出main。等待條件還可以設(shè)置為FIRST_COMPLETED,表示第一個任務(wù)完成就停止等待。
2 多進程實行多任務(wù)2.1 多線程的創(chuàng)建方式創(chuàng)建進程的方式和創(chuàng)建線程的方式類似:
實例化一個multiprocessing.Process的對象,并傳入一個初始化函數(shù)對象(initial function )作為新建進程執(zhí)行入口; 繼承multiprocessing.Process,并重寫run函數(shù);2.1.1 方式1在開始之前,我們要知道什么是進程。道理很簡單,你平時電腦打開QQ客戶端,就是一個進程。再打開一個QQ客戶端,又是一個進程。那么,在python中如何用一篇代碼就可以開啟幾個進程呢?通過一個簡單的例子來演示:
import multiprocessingimport time def task1(): while True:time.sleep(1)print('I am task1') def task2(): while True:time.sleep(2)print('I am task2') if __name__ == ’__main__’: p1 = multiprocessing.Process(target=task1) # multiprocessing.Process創(chuàng)建了子進程對象p1 p2 = multiprocessing.Process(target=task2) # multiprocessing.Process創(chuàng)建了子進程對象p2 p1.start() # 子進程p1啟動 p2.start() # 子進程p2啟動 print('I am main task') # 這是主進程的任務(wù)
輸出:
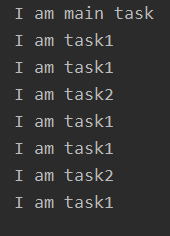
可以看到子進程對象是由multiprocessing模塊中的Process類創(chuàng)建的。除了p1,p2兩個被創(chuàng)建的子進程外。當(dāng)然還有主進程。主進程就是我們從頭到尾的代碼,包括子進程也是由主進程創(chuàng)建的。
注意的點有:
(1)首先解釋一下并發(fā):并發(fā)就是當(dāng)任務(wù)數(shù)大于cpu核數(shù)時,通過操作系統(tǒng)的各種任務(wù)調(diào)度算法,實現(xiàn)多個任務(wù)“一起”執(zhí)行。(實際上總有一些任務(wù)不在執(zhí)行,因為切換任務(wù)相當(dāng)快,看上去想同時執(zhí)行而已。)
(2)當(dāng)是并發(fā)的情況下,子進程與主進程的運行都是沒有順序的,CPU會采用時間片輪詢的方式,哪個程序先要運行就先運行哪個。
(3)主進程會默認等待所有子進程執(zhí)行完畢后,它才會退出。所以在上面的例子中,p1,p2子進程是死循環(huán)進程,主進程的最后一句代碼print('I am main task')雖然運行完了,但是主進程并不會關(guān)閉,他會一直等待著子進程。
(4)主進程默認創(chuàng)建的是非守護進程。注意,結(jié)合3.和5.看。
(5)但是!如果子進程是守護進程的話,那么主進程運行完最后一句代碼后,主進程會直接關(guān)閉,不管你子進程運行完了沒有!
2.1.2 方式2from multiprocessing import Process import os, time class CustomProcess(Process): def __init__(self, p_name, target=None):# step 1: call base __init__ function()super(CustomProcess, self).__init__(name=p_name, target=target, args=(p_name,)) def run(self):# step 2:# time.sleep(0.1)print('Custom Process name: %s, pid: %s '%(self.name, os.getpid())) if __name__ == ’__main__’: p1 = CustomProcess('process_1') p1.start() p1.join() print('subprocess pid: %s'%p1.pid) print('current process pid: %s' % os.getpid())
輸出:
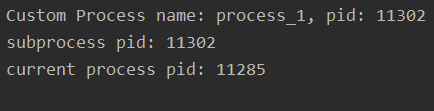
這里可以思考一下,如果像多線程一樣,存在一個全局的變量share_data,不同進程同時訪問share_data會有問題嗎?
由于每一個進程擁有獨立的內(nèi)存地址空間且互相隔離,因此不同進程看到的share_data是不同的、分別位于不同的地址空間,同時訪問不會有問題。這里需要注意一下。
2.2 守護進程測試下:
import multiprocessingimport time def task1(): while True:time.sleep(1)print('I am task1') def task2(): while True:time.sleep(2)print('I am task2') if __name__ == ’__main__’: p1 = multiprocessing.Process(target=task1) p2 = multiprocessing.Process(target=task2) p1.daemon = True # 設(shè)置p1子進程為守護進程 p2.daemon = True # 設(shè)置p2子進程為守護進程 p1.start() p2.start() print('I am main task')
輸出:
I am main task
輸出結(jié)果是不是有點奇怪。為什么p1,p2子進程都沒有輸出的?
讓我們來整理一下思路:
創(chuàng)建p1,p2子進程 設(shè)置p1,p2子進程為守護進程 p1,p2子進程開啟 p1,p2子進程代碼里面都有休眠時間,所以cpu為了不浪費時間,先做主進程后續(xù)的代碼。 執(zhí)行主進程后續(xù)的代碼,print('I am main task') 主進程后續(xù)的代碼執(zhí)行完成了,所以剩下的子進程是守護進程的,全都要關(guān)閉了。但是,如果主進程的代碼執(zhí)行完了,有兩個子進程,一個是守護的,一個非守護的,怎么辦呢?其實,他會等待非守護的那個子進程運行完,然后三個進程一起關(guān)閉。 p1,p2還在休眠時間內(nèi)就被終結(jié)生命了,所以什么輸出都沒有。例如,把P1設(shè)為非守護進程:
import multiprocessingimport time def task1(): i = 1 while i < 5:time.sleep(1)i += 1print('I am task1') def task2(): while True:time.sleep(2)print('I am task2') if __name__ == ’__main__’: p1 = multiprocessing.Process(target=task1) p2 = multiprocessing.Process(target=task2) p2.daemon = True # 設(shè)置p2子進程為守護進程 p1.start() p2.start() print('I am main task')
輸出:
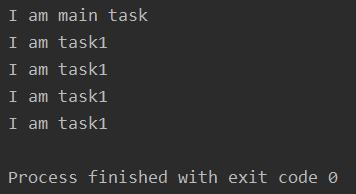
里面涉及到兩個知識點:
(1)當(dāng)主進程結(jié)束后,會發(fā)一個消息給子進程(守護進程),守護進程收到消息,則立即結(jié)束
(2)CPU是按照時間片輪詢的方式來運行多進程的。哪個合適的哪個運行,如果你的子進程里都有time.sleep。那我CPU為了不浪費資源,肯定先去干點其他的事情啊。
那么,守護進程隨時會被中斷,他的存在意義在哪里的?
其實,守護進程主要用來做與業(yè)務(wù)無關(guān)的任務(wù),無關(guān)緊要的任務(wù),可有可無的任務(wù),比如內(nèi)存垃圾回收,某些方法的執(zhí)行時間的計時等。
2.3 創(chuàng)建的子進程要傳入?yún)?shù)import multiprocessing def task(a,b,*args,**kwargs): print('a') print('b') print(args) print(kwargs) if __name__ == ’__main__’: p1 = multiprocessing.Process(target=task,args=(1,2,3,4,5,6),kwargs={'name':'chichung','age':23}) p1.start() print('主進程已經(jīng)運行完最后一行代碼啦')
輸出:

子進程要運行的函數(shù)需要傳入變量a,b,一個元組,一個字典。我們創(chuàng)建子進程的時候,變量a,b要放進元組里面,task函數(shù)取的時候會把前兩個取出來,分別賦值給a,b了。
2.4 子進程幾個常用的方法p.start 開始執(zhí)行子線程 p.name 查看子進程的名稱 p.pid 查看子進程的id p.is_alive 判斷子進程是否存活 p.join(timeout)
阻塞主進程,當(dāng)子進程p運行完畢后,再解開阻塞,讓主進程運行后續(xù)的代碼
如果timeout=2,就是阻塞主進程2s,這2s內(nèi)主進程不能運行后續(xù)的代碼。過了2s后,就算子進程沒有運行完畢,主進程也能運行后續(xù)的代碼
p.terminate 終止子進程p的運行import multiprocessing def task(a,b,*args,**kwargs): print('a') print('b') print(args) print(kwargs) if __name__ == ’__main__’: p1 = multiprocessing.Process(target=task,args=(1,2,3,4,5,6),kwargs={'name':'chichung','age':23}) p1.start() print('p1子進程的名字:%s' % p1.name) print('p1子進程的id:%d' % p1.pid) p1.join() print(p1.is_alive())
輸出:

進程之間是不可以共享全局變量的,即使子進程與主進程。道理很簡單,一個新的進程,其實就是占用一個新的內(nèi)存空間,不同的內(nèi)存空間,里面的變量肯定不能夠共享的。實驗證明如下:
示例一:
import multiprocessing g_list = [123] def task1(): g_list.append('task1') print(g_list) def task2(): g_list.append('task2') print(g_list) def main_process(): g_list.append('main_processs') print(g_list) if __name__ == ’__main__’: p1 = multiprocessing.Process(target=task1) p2 = multiprocessing.Process(target=task2) p1.start() p2.start() main_process() print('11111: ', g_list)
輸出:
[123, ’main_processs’]11111: [123, ’main_processs’][123, ’task1’][123, ’task2’]
示例二:
import multiprocessingimport time def task1(loop): global num for i in range(loop):# 等價于 num += 1temp = numnum = temp + 1 print(num) print('I am task1') def task2(loop): global num for i in range(loop):# 等價于 num += 1temp = numnum = temp + 1 print(num) print('I am task2') if __name__ == ’__main__’: p1 = multiprocessing.Process(target=task1, args=(100000,) # multiprocessing.Process創(chuàng)建了子進程對象p1 p2 = multiprocessing.Process(target=task2, args=(100000,) # multiprocessing.Process創(chuàng)建了子進程對象p2 p1.start() # 子進程p1啟動 p2.start() # 子進程p2啟動 print('I am main task') # 這是主進程的任務(wù)
輸出:

進程池可以理解成一個隊列,該隊列可以容易指定數(shù)量的子進程,當(dāng)隊列被任務(wù)占滿之后,后續(xù)新增的任務(wù)就得排隊,直到舊的進程有任務(wù)執(zhí)行完空余出來,才會去執(zhí)行新的任務(wù)。
在利用Python進行系統(tǒng)管理的時候,特別是同時操作多個文件目錄,或者遠程控制多臺主機,并行操作可以節(jié)約大量的時間。當(dāng)被操作對象數(shù)目不大時,可以直接利用multiprocessing中的Process動態(tài)成生多個進程,十幾個還好,但如果是上百個,上千個目標(biāo),手動的去限制進程數(shù)量卻又太過繁瑣,此時可以發(fā)揮進程池的功效。
Pool可以提供指定數(shù)量的進程供用戶調(diào)用,當(dāng)有新的請求提交到pool中時,如果池還沒有滿,那么就會創(chuàng)建一個新的進程用來執(zhí)行該請求;但如果池中的進程數(shù)已經(jīng)達到規(guī)定最大值,那么該請求就會等待,直到池中有進程結(jié)束,才會創(chuàng)建新的進程來它。
2.6.1 使用進程池(非阻塞)#coding: utf-8import multiprocessingimport time def func(msg): print('msg:', msg) time.sleep(3) print('end') if __name__ == '__main__': pool = multiprocessing.Pool(processes = 3) # 設(shè)定進程的數(shù)量為3 for i in range(4):msg = 'hello %d' %(i)pool.apply_async(func, (msg, )) #維持執(zhí)行的進程總數(shù)為processes,當(dāng)一個進程執(zhí)行完畢后會添加新的進程進去 print('Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~') pool.close() pool.join() #調(diào)用join之前,先調(diào)用close函數(shù),否則會出錯。執(zhí)行完close后不會有新的進程加入到pool,join函數(shù)等待所有子進程結(jié)束 print('Sub-process(es) done.')
輸出:
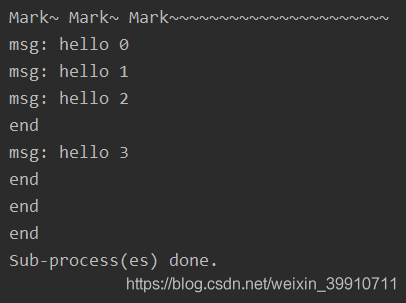
函數(shù)解釋:
apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞,apply(func[, args[, kwds]])是阻塞的(理解區(qū)別,看例1例2結(jié)果區(qū)別) close() 關(guān)閉pool,使其不在接受新的任務(wù)。 terminate() 結(jié)束工作進程,不在處理未完成的任務(wù)。 join() 主進程阻塞,等待子進程的退出, join方法要在close或terminate之后使用。apply(), apply_async():
apply(): 阻塞主進程, 并且一個一個按順序地執(zhí)行子進程, 等到全部子進程都執(zhí)行完畢后 ,繼續(xù)執(zhí)行 apply()后面主進程的代碼 apply_async() 非阻塞異步的, 他不會等待子進程執(zhí)行完畢, 主進程會繼續(xù)執(zhí)行, 他會根據(jù)系統(tǒng)調(diào)度來進行進程切換執(zhí)行說明:創(chuàng)建一個進程池pool,并設(shè)定進程的數(shù)量為3,xrange(4)會相繼產(chǎn)生四個對象[0, 1, 2, 4],四個對象被提交到pool中,因pool指定進程數(shù)為3,所以0、1、2會直接送到進程中執(zhí)行,當(dāng)其中一個執(zhí)行完事后才空出一個進程處理對象3,所以會出現(xiàn)輸出“msg: hello 3”出現(xiàn)在'end'后。因為為非阻塞,主函數(shù)會自己執(zhí)行自個的,不搭理進程的執(zhí)行,所以運行完for循環(huán)后直接輸出“mMsg: hark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~”,主程序在pool.join()處等待各個進程的結(jié)束。
2.6.2 使用進程池(阻塞)#coding: utf-8import multiprocessingimport time def func(msg): print('msg:', msg) time.sleep(3) print('end') if __name__ == '__main__': pool = multiprocessing.Pool(processes = 3) # 設(shè)定進程的數(shù)量為3 for i in range(4):msg = 'hello %d' %(i)pool.apply(func, (msg, )) #維持執(zhí)行的進程總數(shù)為processes,當(dāng)一個進程執(zhí)行完畢后會添加新的進程進去 print('Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~') pool.close() pool.join() #調(diào)用join之前,先調(diào)用close函數(shù),否則會出錯。執(zhí)行完close后不會有新的進程加入到pool,join函數(shù)等待所有子進程結(jié)束 print('Sub-process(es) done.')
輸出:

import multiprocessingimport time def func(msg): print('msg:', msg) time.sleep(3) print('end') return 'done' + msg if __name__ == '__main__': pool = multiprocessing.Pool(processes=4) result = [] for i in range(3):msg = 'hello %d' %(i)result.append(pool.apply_async(func, (msg, ))) pool.close() pool.join() for res in result:print(':::', res.get()) print('Sub-process(es) done.')
輸出:
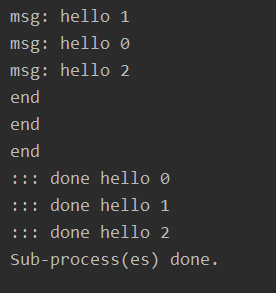
注:get()函數(shù)得出每個返回結(jié)果的值
3 python多線程與多進程比較先來看兩個例子:
(1)示例一,多線程與單線程,開啟兩個python線程分別做一億次加一操作,和單獨使用一個線程做一億次加一操作:
import threadingimport time def tstart(arg): var = 0 for i in range(100000000):var += 1 print(arg, var) if __name__ == ’__main__’: t1 = threading.Thread(target=tstart, args=(’This is thread 1’,)) t2 = threading.Thread(target=tstart, args=(’This is thread 2’,)) start_time = time.time() t1.start() t2.start() t1.join() t2.join() print('Two thread cost time: %s' % (time.time() - start_time)) start_time = time.time() tstart('This is thread 0') print('Main thread cost time: %s' % (time.time() - start_time))
輸出:
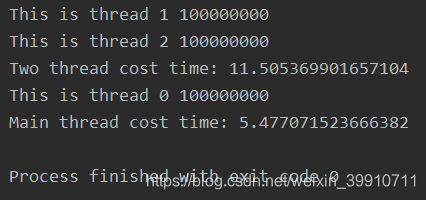
上面的例子如果只開啟t1和t2兩個線程中的一個,那么運行時間和主線程基本一致。
(2)示例二,使用兩個進程
from multiprocessing import Process import os, time def pstart(arg): var = 0 for i in range(100000000):var += 1 print(arg, var) if __name__ == ’__main__’: p1 = Process(target = pstart, args = ('1', )) p2 = Process(target = pstart, args = ('2', )) start_time = time.time() p1.start() p2.start() p1.join() p2.join() print('Two process cost time: %s' % (time.time() - start_time)) start_time = time.time() pstart('0') print('Current process cost time: %s' % (time.time() - start_time))
輸出:
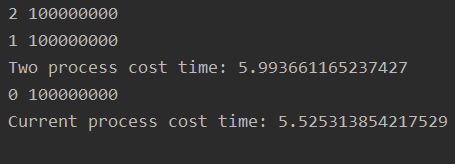
對比分析:
雙進程并行執(zhí)行和單進程執(zhí)行相同的運算代碼,耗時基本相同,雙進程耗時會稍微多一些,可能的原因是進程創(chuàng)建和銷毀會進行系統(tǒng)調(diào)用,造成額外的時間開銷。
但是對于python線程,雙線程并行執(zhí)行耗時比單線程要高的多,效率相差近10倍。如果將兩個并行線程改成串行執(zhí)行,即:
import threadingimport time def tstart(arg): var = 0 for i in range(100000000):var += 1 print(arg, var) if __name__ == ’__main__’: t1 = threading.Thread(target=tstart, args=(’This is thread 1’,)) t2 = threading.Thread(target=tstart, args=(’This is thread 2’,)) start_time = time.time() t1.start() t1.join() print('thread1 cost time: %s' % (time.time() - start_time)) start_time = time.time() t2.start() t2.join() print('thread2 cost time: %s' % (time.time() - start_time)) start_time = time.time() tstart('This is thread 0') print('Main thread cost time: %s' % (time.time() - start_time))
輸出:
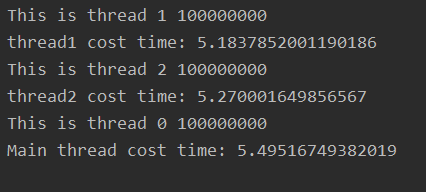
可以看到三個線程串行執(zhí)行,每一個執(zhí)行的時間基本相同。
本質(zhì)原因雙線程是并發(fā)執(zhí)行的,而不是真正的并行執(zhí)行。原因就在于GIL鎖。
4 GIL鎖提起python多線程就不得不提一下GIL(Global Interpreter Lock 全局解釋器鎖),這是目前占統(tǒng)治地位的python解釋器CPython中為了保證數(shù)據(jù)安全所實現(xiàn)的一種鎖。不管進程中有多少線程,只有拿到了GIL鎖的線程才可以在CPU上運行,即使是多核處理器。對一個進程而言,不管有多少線程,任一時刻,只會有一個線程在執(zhí)行。對于CPU密集型的線程,其效率不僅僅不高,反而有可能比較低。python多線程比較適用于IO密集型的程序。對于的確需要并行運行的程序,可以考慮多進程。
多線程對鎖的爭奪,CPU對線程的調(diào)度,線程之間的切換等均會有時間開銷。
5 線程和進程比較5.1 線程和進程的區(qū)別下面簡單的比較一下線程與進程
進程是資源分配的基本單位,線程是CPU執(zhí)行和調(diào)度的基本單位; 通信/同步方式: 進程: 通信方式:管道,F(xiàn)IFO,消息隊列,信號,共享內(nèi)存,socket,stream流; 同步方式:PV信號量,管程線程: 同步方式:互斥鎖,遞歸鎖,條件變量,信號量 通信方式:位于同一進程的線程共享進程資源,因此線程間沒有類似于進程間用于數(shù)據(jù)傳遞的通信方式,線程間的通信主要是用于線程同步。 CPU上真正執(zhí)行的是線程,線程比進程輕量,其切換和調(diào)度代價比進程要小; 線程間對于共享的進程數(shù)據(jù)需要考慮線程安全問題,由于進程之間是隔離的,擁有獨立的內(nèi)存空間資源,相對比較安全,只能通過上面列出的IPC(Inter-Process Communication)進行數(shù)據(jù)傳輸; 系統(tǒng)有一個個進程組成,每個進程包含代碼段、數(shù)據(jù)段、堆空間和棧空間,以及操作系統(tǒng)共享部分 ,有等待,就緒和運行三種狀態(tài); 一個進程可以包含多個線程,線程之間共享進程的資源(文件描述符、全局變量、堆空間等),寄存器變量和棧空間等是線程私有的; 操作系統(tǒng)中一個進程掛掉不會影響其他進程,如果一個進程中的某個線程掛掉而且OS對線程的支持是多對一模型,那么會導(dǎo)致當(dāng)前進程掛掉; 如果CPU和系統(tǒng)支持多線程與多進程,多個進程并行執(zhí)行的同時,每個進程中的線程也可以并行執(zhí)行,這樣才能最大限度的榨取硬件的性能;
進程切換過程切換牽涉到非常多的東西,寄存器內(nèi)容保存到任務(wù)狀態(tài)段TSS,切換頁表,堆棧等。簡單來說可以分為下面兩步:
頁全局目錄切換,使CPU到新進程的線性地址空間尋址; 切換內(nèi)核態(tài)堆棧和硬件上下文,硬件上下文包含CPU寄存器的內(nèi)容,存放在TSS中;線程運行于進程地址空間,切換過程不涉及到空間的變換,只牽涉到第二步;
5.3 使用多線程還是多進程? CPU密集型:程序需要占用CPU進行大量的運算和數(shù)據(jù)處理;適合多進程; I/O密集型:程序中需要頻繁的進行I/O操作;例如網(wǎng)絡(luò)中socket數(shù)據(jù)傳輸和讀取等;適合多線程由于python多線程并不是并行執(zhí)行,因此較適合與I/O密集型程序,多進程并行執(zhí)行適用于CPU密集型程序;
python多線程實現(xiàn)多任務(wù):https://www.cnblogs.com/chichung/p/9566734.html
python通過多進程實行多任務(wù):https://www.cnblogs.com/chichung/p/9532962.html
python多線程與多進程及其區(qū)別:https://www.cnblogs.com/yssjun/p/11302500.html
python進程池:multiprocessing.pool:https://www.cnblogs.com/kaituorensheng/p/4465768.html
到此這篇關(guān)于python 多線程實現(xiàn)多任務(wù)的方法示例的文章就介紹到這了,更多相關(guān)python 多線程實現(xiàn)多任務(wù)的方法示例內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Python多線程多進程實例對比解析2. Python多線程操作之互斥鎖、遞歸鎖、信號量、事件實例詳解3. 淺談python多線程和多線程變量共享問題介紹4. Python多線程threading創(chuàng)建及使用方法解析5. Python多線程:主線程等待所有子線程結(jié)束代碼6. 解決python多線程報錯:AttributeError: Can't pickle local object問題7. python多線程semaphore實現(xiàn)線程數(shù)控制的示例8. Python多線程實現(xiàn)支付模擬請求過程解析9. python多線程爬取西刺代理的示例代碼10. Python多線程 Queue 模塊常見用法
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備