SQL中case?when用法及使用案例詳解
Case具有兩種格式。簡單Case函數(shù)和Case搜索函數(shù)。
簡單Case函數(shù)格式:
CASE 列名WHEN 條件值1 THEN 選項1WHEN 條件值2 THEN 選項2……ELSE 默認(rèn)值ENDCase搜索函數(shù):
CASEWHEN 條件1 THEN 選項1WHEN 條件2 THEN 選項2……ELSE 默認(rèn)值END二、case when應(yīng)用場景case when與子查詢性能比較及優(yōu)化。為了方便說明,我們先創(chuàng)建表,并造點數(shù)據(jù)。
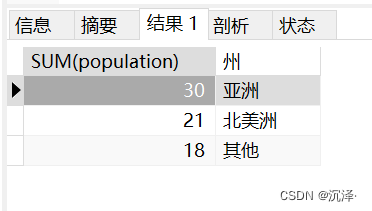
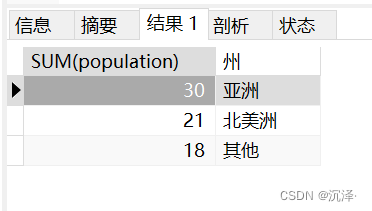
CREATE TABLE `table_a` (`id` INT NOT NULL AUTO_INCREMENT,`country` VARCHAR(50) NOT NULL,`sex` CHAR(2) not null,`population` int NOT NULL,PRIMARY KEY (`id`));insert into table_a values(null,'中國','男',10);insert into table_a values(null,'中國','女',5);insert into table_a values(null,'美國','男',2);insert into table_a values(null,'美國','女',4);insert into table_a values(null,'加拿大','男',4);insert into table_a values(null,'加拿大','女',4);insert into table_a values(null,'英國','男',6);insert into table_a values(null,'英國','女',6);insert into table_a values(null,'法國','男',2);insert into table_a values(null,'法國','女',2);insert into table_a values(null,'日本','男',7);insert into table_a values(null,'日本','女',7);insert into table_a values(null,'德國','男',2);insert into table_a values(null,'墨西哥','男',7);insert into table_a values(null,'印度','男',1);2.1 案例一統(tǒng)計亞洲和北美洲的人口數(shù)量,要求結(jié)果如下:
若第一時間沒有想到case when,我們可能會寫出下面的sql:
SELECT sum(population) from Table_A where country in ('中國','印度','日本')UNIONSELECT sum(population) from Table_A where country in ('美國','加拿大','墨西哥')UNIONSELECT sum(population) from Table_A where country not in ('中國','印度','日本','美國','加拿大','墨西哥');運行結(jié)果:
這個sql的性能效率比較低,對同一個數(shù)據(jù)表查詢了三次,也無法獲得州的那一列。
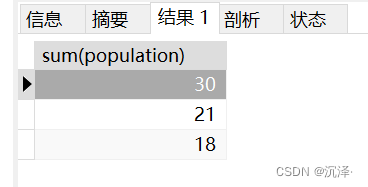
使用case when進(jìn)行改造,如下:
SELECT SUM(population)FROM Table_A GROUP BYCASE country WHEN '中國' THEN '亞洲' WHEN '印度' THEN '亞洲'WHEN '日本' THEN '亞洲' WHEN '美國' THEN '北美洲' WHEN '加拿大' THEN '北美洲' WHEN '墨西哥' THEN '北美洲' ELSE '其他' END;運行結(jié)果:
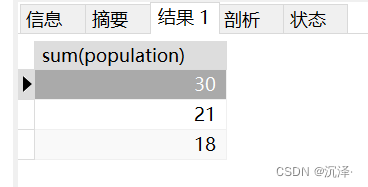
使用了case when的sql語句明顯效率高一些,因為它僅查找了一次表而已,若想獲得州的那一列,只需改寫如下:
SELECT SUM(population), (CASE country WHEN '中國' THEN '亞洲' WHEN '印度' THEN '亞洲' WHEN '日本' THEN '亞洲' WHEN '美國' THEN '北美洲' WHEN '加拿大' THEN '北美洲' WHEN '墨西哥' THEN '北美洲' ELSE '其他' END ) as 州FROM Table_A GROUP BYCASE country WHEN '中國' THEN '亞洲' WHEN '印度' THEN '亞洲'WHEN '日本' THEN '亞洲' WHEN '美國' THEN '北美洲' WHEN '加拿大' THEN '北美洲' WHEN '墨西哥' THEN '北美洲' ELSE '其他' END;運行結(jié)果:
統(tǒng)計每個國家的男生人數(shù)和女生人數(shù),要求結(jié)果如下:
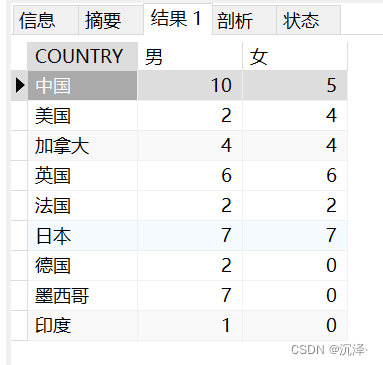
同樣的,不使用case when的寫法如下:
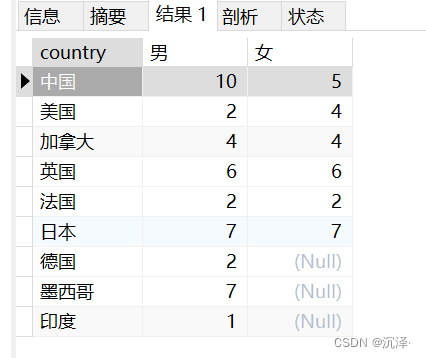
SELECTa.country,(SELECTSUM( a1.population ) FROMtable_a a1 WHEREa1.country = a.country AND a1.sex = '男' ) 男,(SELECTSUM( a1.population ) FROMtable_a a1 WHEREa1.country = a.country AND a1.sex = '女' ) 女 FROMtable_a a GROUP BYa.country;執(zhí)行結(jié)果:
使用case when進(jìn)行優(yōu)化:
SELECT COUNTRY,SUM(CASE SEX WHEN '男' THEN population ELSE 0 END) AS '男',SUM(CASE SEX WHEN '女' THEN population ELSE 0 END) AS '女'FROM table_a GROUP BY COUNTRY;執(zhí)行結(jié)果:
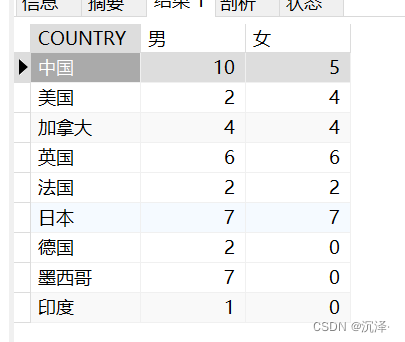
兩者對比,顯然的case when的效率既簡潔,效率也高。
2.3 案例三上述兩個案例也許不夠貼近日常的工作內(nèi)容,下面舉個現(xiàn)實工作遇到的案例。
建表sql如下:
-- 貨架表CREATE TABLE `shelves` (`shelves_id` INT NOT NULL AUTO_INCREMENT, -- 貨架id`shelves_num` VARCHAR(50) NOT NULL UNIQUE,-- 貨架號`shelves_area` VARCHAR(50) NOT NULL,--貨架區(qū)域PRIMARY KEY (`shelves_id`));-- 物品表CREATE TABLE `goods` (`goods_id` INT NOT NULL AUTO_INCREMENT, -- 物品id`goods_name` VARCHAR(50) NOT NULL UNIQUE,-- 物品名稱`goods_type` VARCHAR(20) NOT NULL,-- 物品類型`goods_quantity` int NOT NULL,-- 物品數(shù)量`goods_createTime` DATETIME NULL DEFAULT NULL,-- 創(chuàng)建時間`goods_expiryTime` DATETIME NULL DEFAULT NULL,-- 過期時間`goods_shelvesId` INT NULL DEFAULT NULL,-- 貨架idPRIMARY KEY (`goods_id`));需求說明:統(tǒng)計每個貨架上的物品數(shù)量,要求統(tǒng)計結(jié)果如下

使用子查詢的寫法:
SELECTshelves_area shelvesArea,shelves_num shelvesNum,COUNT( DISTINCT goods_type ) goodsTypeSum,COUNT( goods_id ) goodsSum,(SELECTCOUNT(*)FROMgoodsWHEREgoods_expiryTime < NOW()AND goods_shelvesId = shelves_id ) isNotExpiry,(SELECTCOUNT(*)FROMgoodsWHEREgoods_expiryTime > NOW()AND goods_shelvesId = shelves_id) isExpiryFROMshelvesLEFT JOIN goods ON shelves_id = goods_shelvesIdGROUP BY shelves_id;使用case when的寫法:
SELECTshelves_area shelvesArea,shelves_num shelvesNum,COUNT( DISTINCT goods_type ) goodsTypeSum,COUNT( goods_id ) goodsSum,SUM(CASE WHEN (shelves_id = goods_shelvesId AND goods_expiryTime < NOW()) THEN 1 ELSE 0 END) isNotExpiry,SUM(CASE WHEN (shelves_id = goods_shelvesId AND goods_expiryTime > NOW()) THEN 1 ELSE0 END) isExpiryFROMshelvesLEFT JOIN goods ON shelves_id = goods_shelvesIdGROUP BY shelves_id;兩個不同寫法的運行結(jié)果是一樣的,但是性能效率上case when 顯然比子查詢的高一些。運行結(jié)果如下(本人未造相關(guān)測試數(shù)據(jù)):

例,有如下更新條件1.工資5000以上的職員,工資減少10%2.工資在2000到4600之間的職員,工資增加15%
很容易考慮的是選擇執(zhí)行兩次UPDATE語句,如下所示
--條件1 UPDATE Personnel SET salary = salary * 0.9 WHERE salary >= 5000; --條件2 UPDATE Personnel SET salary = salary * 1.15 WHERE salary >= 2000 AND salary < 4600;但是事情沒有想象得那么簡單,假設(shè)有個人工資5000塊。首先,按照條件1,工資減少10%,變成工資4500。接下來運行第二個SQL時候,因為這個人的工資是4500在2000到4600的范圍之內(nèi),需增加15%,最后這個人的工資結(jié)果是5175,不但沒有減少,反而增加了。如果要是反過來執(zhí)行,那么工資4600的人相反會變成減少工資。暫且不管這個規(guī)章是多么荒誕,如果想要一個SQL 語句實現(xiàn)這個功能的話,我們需要用到Case函數(shù)。代碼如下:
UPDATE Personnel SET salary = CASE WHEN salary >= 5000 THEN salary * 0.9 WHEN salary >= 2000 AND salary < 4600 THEN salary * 1.15ELSE salary END;這里要注意一點,最后一行的ELSE salary是必需的,要是沒有這行,不符合這兩個條件的人的工資將會被寫成NUll,那可就大事不妙了。在Case函數(shù)中Else部分的默認(rèn)值是NULL,這點是需要注意的地方。
這種方法還可以在很多地方使用,比如說變更主鍵這種累活。一般情況下,要想把兩條數(shù)據(jù)的Primary key,a和b交換,需要經(jīng)過臨時存儲,拷貝,讀回數(shù)據(jù)的三個過程,要是使用Case函數(shù)的話,一切都變得簡單多了。p_key col_1 col_2a 1 張三b 2 李四c 3 王五假設(shè)有如上數(shù)據(jù),需要把主鍵a和b相互交換。用Case函數(shù)來實現(xiàn)的話,代碼如下
UPDATE SomeTable SET p_key = CASE WHEN p_key = 'a' THEN 'b' WHEN p_key = 'b' THEN 'a'ELSE p_key ENDWHERE p_key IN('a', 'b');四、參考來源https://blog.csdn.net/Max_Rzdq/article/details/79418893
到此這篇關(guān)于SQL中case when用法詳解及使用案例的文章就介紹到這了,更多相關(guān)sql case when用法內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備