SQLSERVER 臨時表和表變量的區(qū)別匯總
目錄
- 一:背景
- 1. 講故事
- 二:到底有什么區(qū)別
- 1. 前置思考
- 2. 如何驗證都存儲在 tempdb 中 ?
- 3. 不同點在哪里
- 三:總結(jié)
一:背景
1. 講故事
今天和大家聊一套面試中經(jīng)常被問到的高頻題,對,就是 臨時表 和 表變量 這倆玩意,如果有朋友在面試中回答的不好,可以嘗試看下這篇能不能幫你成功邁過。
二:到底有什么區(qū)別
1. 前置思考
不管是 臨時表 還是 表變量 都帶了 表 這個詞,既然提到了 表 ,按推理自然會落到某一個 數(shù)據(jù)庫 中,如果真在一個 數(shù)據(jù)庫 中,那自然就有它的存儲文件 .mdf 和 .ldf,那是不是如我推理的那樣呢? 查閱 MSDN 的官方文檔可以發(fā)現(xiàn),臨時表 和 表變量 確實都會使用 tempdb 這個臨時存儲數(shù)據(jù)庫,而且 tempdb 也有自己的 mdf,ndf,ldf 文件,截圖如下:
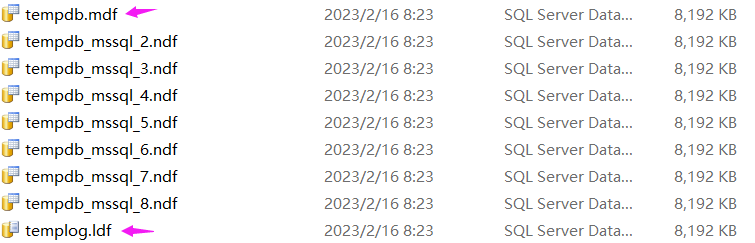
有了這個大思想之后,接下來就可以進行驗證了。
2. 如何驗證都存儲在 tempdb 中 ?
要想驗證其實很簡單,sqlserver 提供了多種方式觀察。
- 查詢的過程中觀察 tempdb 下是否存在
xxx表。 - 使用動態(tài)管理視圖
sys.dm_db_session_space_usage查詢當(dāng)前sql占用tempdb下的數(shù)據(jù)頁個數(shù)。
為了讓測試效果明顯,我分別插入 10w 條記錄觀察 數(shù)據(jù)頁 占用情況。
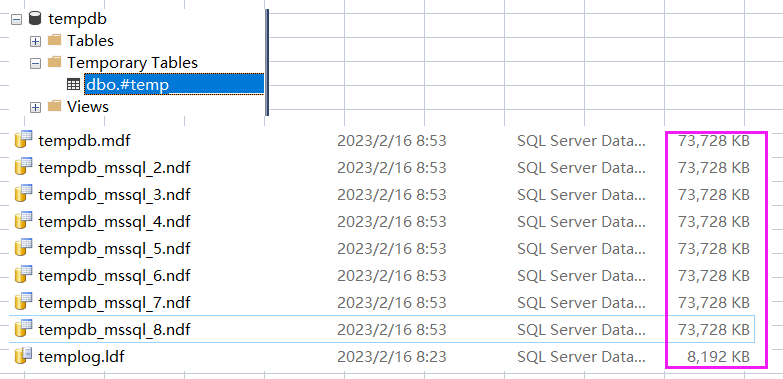
1.臨時表插入 10w 條記錄
CREATE TABLE #temp( id INT, content CHAR(4000) DEFAULT "aaaaaaaaaa");GOINSERT INTO #temp(id)SELECT TOP 100000 ROW_NUMBER() OVER (ORDER BY o1.object_id) AS idFROM sys.objects AS o1,sys.objects AS o2;GOSELECT * FROM sys.dm_db_session_space_usageWHERE session_id=@@SPID;

從圖中的 user_objects_alloc_page_count=50456 看,當(dāng)前的 insert 操作占用了 50456 個數(shù)據(jù)頁。
接下來展開 tempdb 數(shù)據(jù)庫以及觀察到的 mdf 文件大小,都驗證了存儲到 tempdb 這個結(jié)論。
2.表變量插入 10w 條記錄
因為表變量的特殊性,這里我故意暫停 1min 讓查詢遲遲得不到結(jié)束,在這期間方便展開 tempdb,重啟 sqlserver 恢復(fù)初始狀態(tài)后,執(zhí)行如下 sql:
DECLARE @temp TABLE( id INT, content CHAR(4000) DEFAULT "aaaaaaaaaa");INSERT INTO @temp(id)SELECT TOP 100000 ROW_NUMBER() OVER (ORDER BY o1.object_id) AS idFROM sys.objects AS o1,sys.objects AS o2;SELECT * FROM sys.dm_db_session_space_usageWHERE session_id=@@SPID; WAITFOR DELAY "00:01:00"
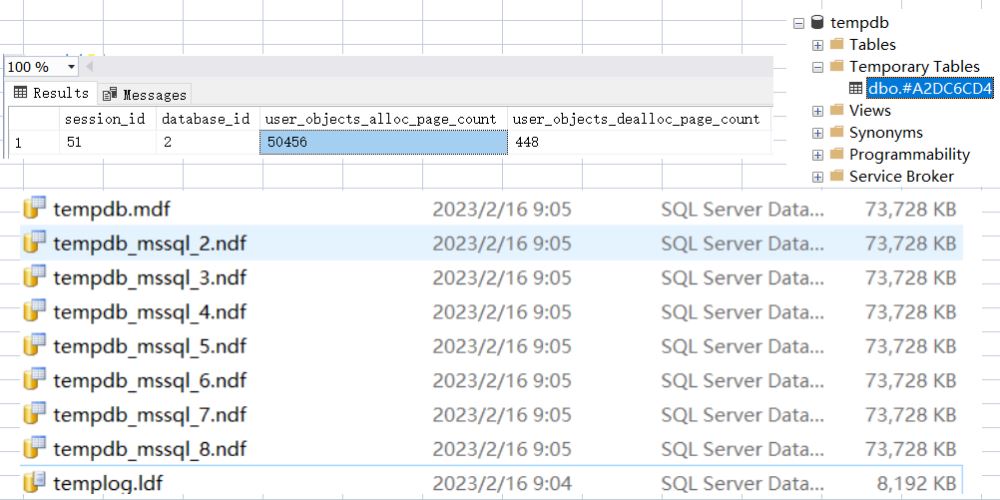
從圖中可以看到 表變量 也會占用 5w+ 的數(shù)據(jù)頁并且數(shù)據(jù)文件會膨脹。
3. 不同點在哪里
對底層存儲有了了解之后,接下來按照重要度從高到低來了解一下區(qū)別吧。
1.臨時表有統(tǒng)計信息,而表變量沒有
所謂的 統(tǒng)計信息,就是對表數(shù)據(jù)繪制一個 直方圖 來掌握數(shù)據(jù)的分布情況,sqlserver 在擇取較優(yōu)的執(zhí)行計劃時會嚴重依賴于這個 直方圖,由于展開不了 Statistics 列,這里就從執(zhí)行計劃上觀察,如下圖所示:
- 臨時表下的執(zhí)行計劃
選中 SELECT * FROM #temp WHERE id > 10 AND id<20; 之后點擊 SSMS 的評估執(zhí)行計劃按鈕來觀察下評估執(zhí)行計劃,可以清晰的看到 sqlserver 知道表中有多少條記錄,截圖如下:

- 表變量下的執(zhí)行計劃
由于表變量的批處理性,我們用 SET STATISTICS XML ON 把 xml 查詢出來,然后點擊觀察可視化視圖,參考sql 如下:
DECLARE @temp TABLE( id INT, content CHAR(4000) DEFAULT "aaaaaaaaaa");INSERT INTO @temp(id)SELECT TOP 100000 ROW_NUMBER() OVER (ORDER BY o1.object_id) AS idFROM sys.objects AS o1,sys.objects AS o2;SET STATISTICS XML ONSELECT * FROM @temp WHERE id > 10 AND id<20;SET STATISTICS XML OFF
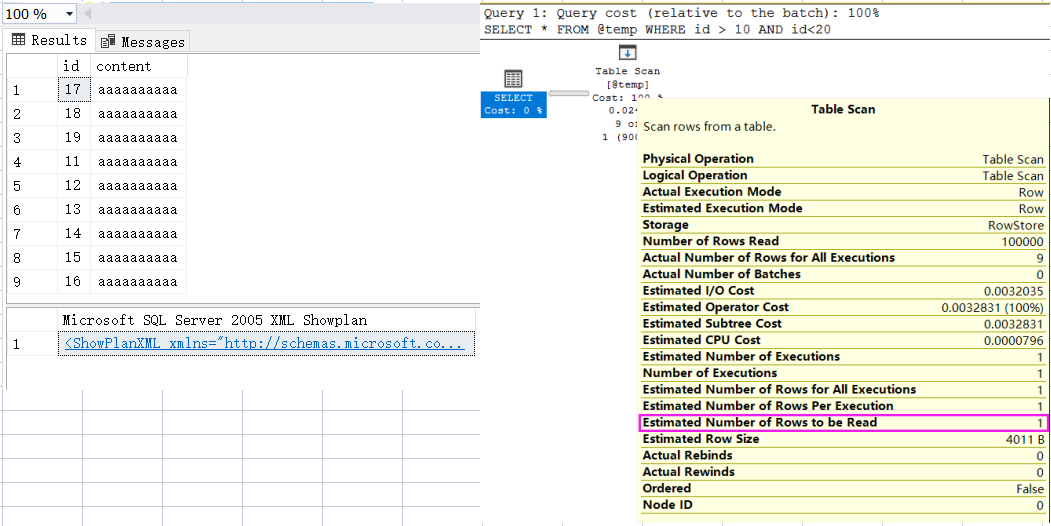
從圖中可以清晰的看到,雖然表變量有 10w 條記錄,但由于沒有統(tǒng)計信息,sqlserver 也就無法知道這張表的數(shù)據(jù)分布,所以就按照默認值 1 條來計算。
從這里大家也能看得出來,如果 表記錄 的真實條數(shù) 和 默認的 1 嚴重偏移的話,會給生成執(zhí)行計劃 造成重大失誤,這個大家一定要當(dāng)心了。
2.其它使用上的區(qū)別
除了上一個本質(zhì)上的不同,接下來就是一些使用上的不同了,比如:
- 臨時表是 session 級的,表變量是 批處理 級
所謂的批處理,就是以 go 為界定,兩者就是作用域上的不同。
- 臨時表可以后續(xù)修改,表變量不能后續(xù)修改。
這里的修改涉及到 字段,索引,整體上來說臨時表在使用上和普通表趨同,表變量不能進行后續(xù)修改。
三:總結(jié)
總的來說,表變量 沒有統(tǒng)計信息,也不可以后續(xù)做 DDL 操作,這種情況下 表變量 比 臨時表 更輕量級,不會有如下副作用:
- DDL 修改導(dǎo)致執(zhí)行計劃過期重建
- sqlserver 對 統(tǒng)計信息 的維護壓力
其實在這種作用域下高頻的創(chuàng)建和刪除表的操作中,表變量會讓系統(tǒng)壓力減輕很多。
但陽事總會有陰事來均衡它,一旦 表變量 的記錄條數(shù)嚴重偏移默認的 1條,會污染sqlserver的執(zhí)行計劃擇取,可能會讓你的 sql 遭受滅頂之災(zāi),所以一定要控制 表變量 的記錄條數(shù),最好在百條內(nèi) 。
最后的建議是:如果你是個小白可以無腦使用 臨時表 ,90%的情況下都可以做到通殺,如果你是個高手可以考慮一下 表變量。
到此這篇關(guān)于SQLSERVER 臨時表和表變量到底有什么區(qū)別的文章就介紹到這了,更多相關(guān)SQLSERVER 臨時表和表變量區(qū)別內(nèi)容請搜索以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持!
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備