MySQL Shell import_table數據導入的實現
上期技術分享我們介紹了MySQL Load Data的4種常用的方法將文本數據導入到MySQL,這一期我們繼續介紹另一款更加高效的數據導入工具,MySQL Shell 工具集中的import_table,該工具的全稱是Parallel Table Import Utility,顧名思義,支持并發數據導入,該工具在MySQL Shell 8.0.23版本后,功能更加完善, 以下列舉該工具的核心功能
基本覆蓋了MySQL Data Load的所有功能,可以作為替代品使用 默認支持并發導入(支持自定義chunk大小) 支持通配符匹配多個文件同時導入到一張表(非常適用于相同結構數據匯總到一張表) 支持限速(對帶寬使用有要求的場景,非常合適) 支持對壓縮文件處理 支持導入到5.7及以上MySQL2. Load Data 與 import table功能示例該部分針對import table和Load Data相同的功能做命令示例演示,我們依舊以導入employees表的示例數據為例,演示MySQL Load Data的綜合場景
數據自定義順序導入 數據函數處理 自定義數據取值## 示例數據如下[root@10-186-61-162 tmp]# cat employees_01.csv'10001','1953-09-02','Georgi','Facello','M','1986-06-26''10003','1959-12-03','Parto','Bamford','M','1986-08-28''10002','1964-06-02','Bezalel','Simmel','F','1985-11-21''10004','1954-05-01','Chirstian','Koblick','M','1986-12-01''10005','1955-01-21','Kyoichi','Maliniak','M','1989-09-12''10006','1953-04-20','Anneke','Preusig','F','1989-06-02''10007','1957-05-23','Tzvetan','Zielinski','F','1989-02-10''10008','1958-02-19','Saniya','Kalloufi','M','1994-09-15''10009','1952-04-19','Sumant','Peac','F','1985-02-18''10010','1963-06-01','Duangkaew','Piveteau','F','1989-08-24'## 示例表結構 10.186.61.162:3306 employees SQL > desc emp;+-------------+---------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-------------+---------------+------+-----+---------+-------+| emp_no | int | NO | PRI | NULL | || birth_date | date | NO | | NULL | || first_name | varchar(14) | NO | | NULL | || last_name | varchar(16) | NO | | NULL | || full_name | varchar(64) | YES | | NULL | | -- 表新增字段,導出數據文件中不存在| gender | enum(’M’,’F’) | NO | | NULL | || hire_date | date | NO | | NULL | || modify_date | datetime | YES | | NULL | | -- 表新增字段,導出數據文件中不存在| delete_flag | varchar(1) | YES | | NULL | | -- 表新增字段,導出數據文件中不存在+-------------+---------------+------+-----+---------+-------+2.1 用Load Data方式導入數據
具體參數含義不做說明,需要了解語法規則及含義可查看系列上一篇文章<MySQL Load Data的多種用法>
load data infile ’/data/mysql/3306/tmp/employees_01.csv’into table employees.empcharacter set utf8mb4fields terminated by ’,’enclosed by ’'’lines terminated by ’n’(@C1,@C2,@C3,@C4,@C5,@C6)set emp_no=@C1, birth_date=@C2, first_name=upper(@C3), last_name=lower(@C4), full_name=concat(first_name,’ ’,last_name), gender=@C5, hire_date=@C6 , modify_date=now(), delete_flag=if(hire_date<’1988-01-01’,’Y’,’N’);
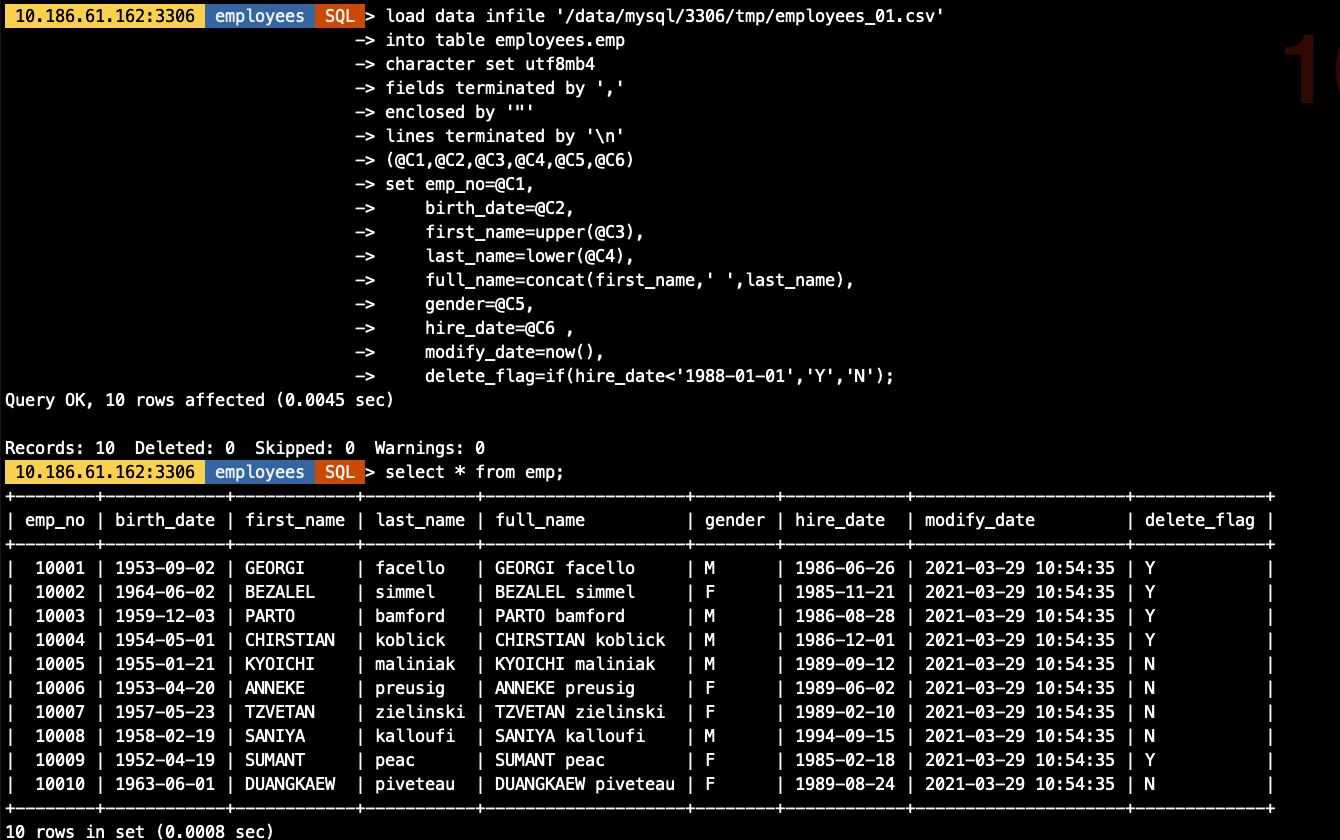
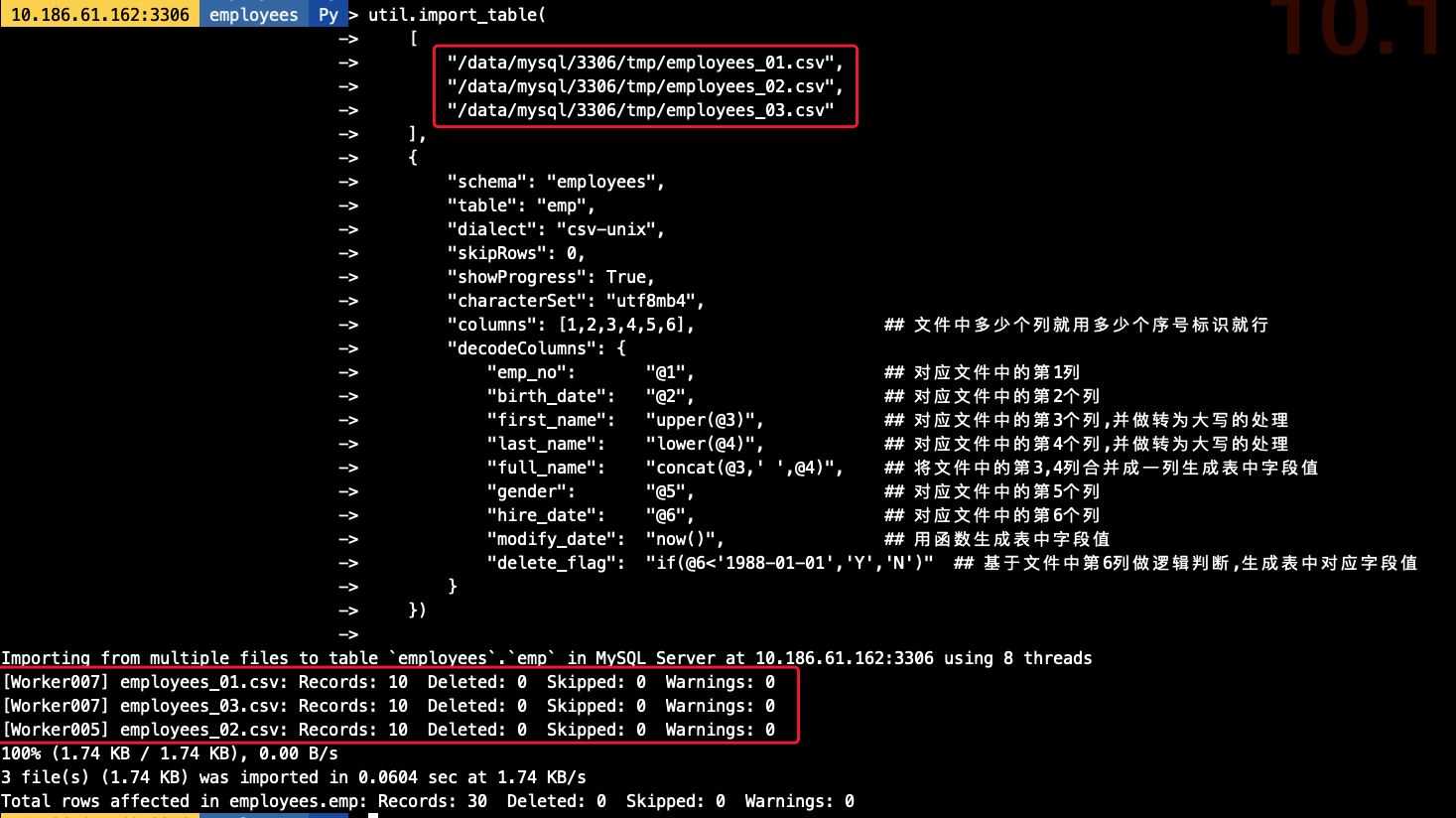
util.import_table( ['/data/mysql/3306/tmp/employees_01.csv', ], {'schema': 'employees', 'table': 'emp','dialect': 'csv-unix','skipRows': 0,'showProgress': True,'characterSet': 'utf8mb4','columns': [1,2,3,4,5,6], ## 文件中多少個列就用多少個序號標識就行'decodeColumns': { 'emp_no': '@1', ## 對應文件中的第1列 'birth_date': '@2', ## 對應文件中的第2個列 'first_name': 'upper(@3)', ## 對應文件中的第3個列,并做轉為大寫的處理 'last_name': 'lower(@4)', ## 對應文件中的第4個列,并做轉為大寫的處理 'full_name': 'concat(@3,’ ’,@4)', ## 將文件中的第3,4列合并成一列生成表中字段值 'gender': '@5', ## 對應文件中的第5個列 'hire_date': '@6', ## 對應文件中的第6個列 'modify_date': 'now()',## 用函數生成表中字段值 'delete_flag': 'if(@6<’1988-01-01’,’Y’,’N’)' ## 基于文件中第6列做邏輯判斷,生成表中對應字段值} })
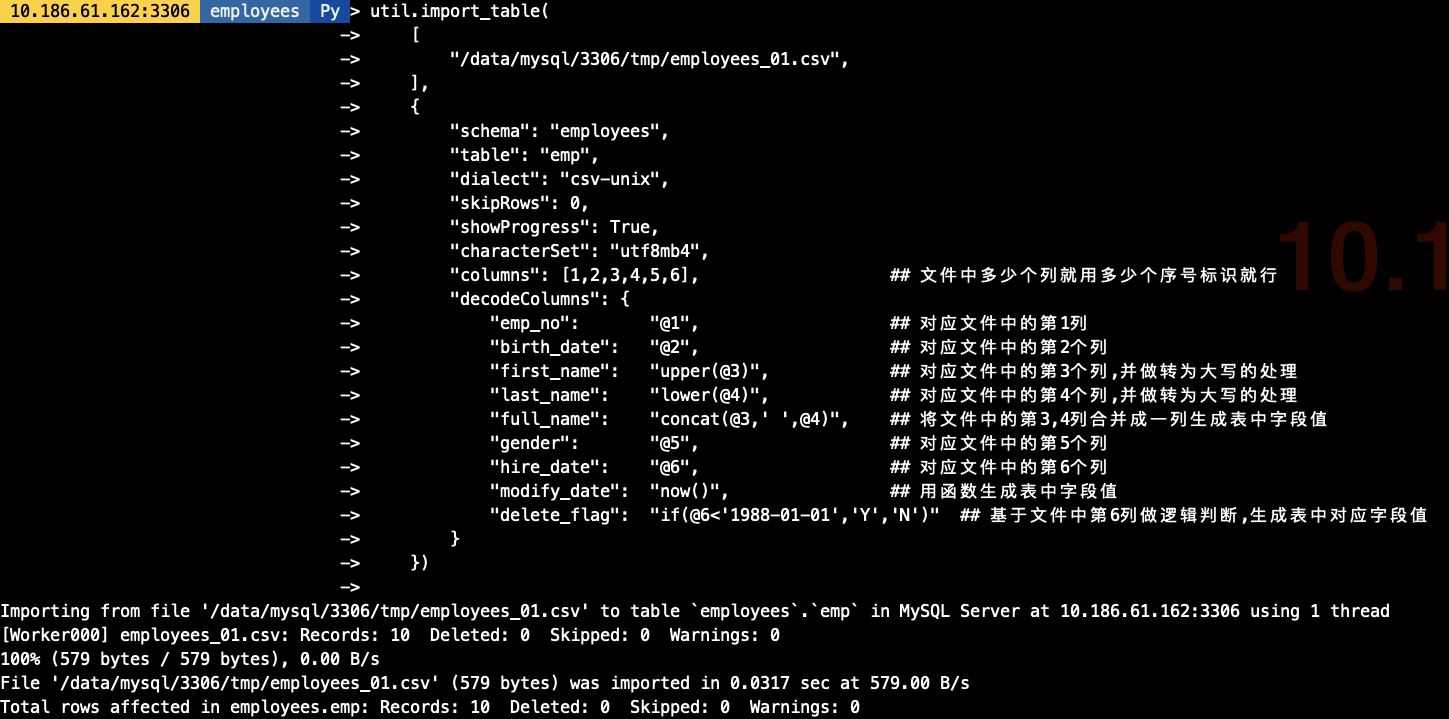
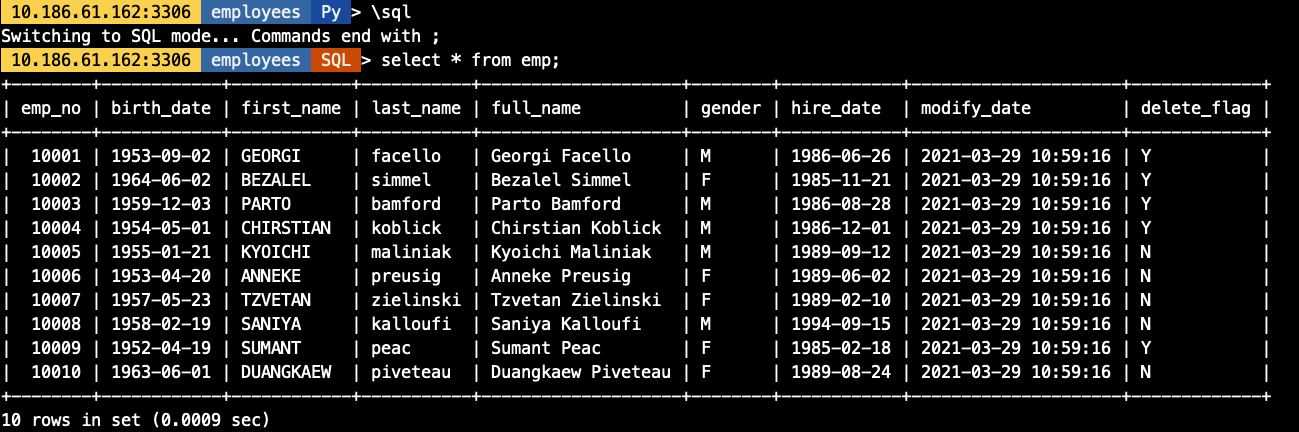
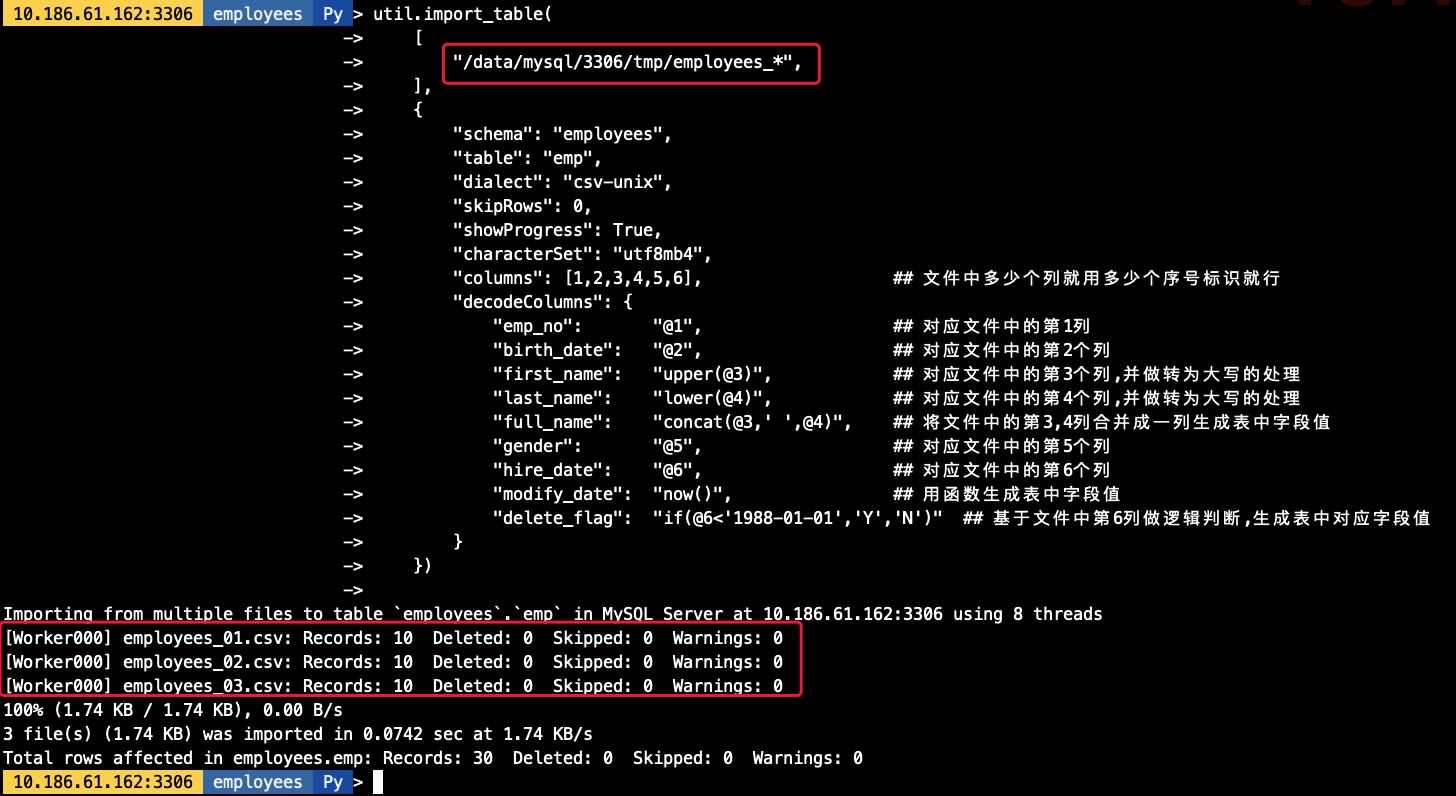
## 在導入前我生成好了3分單獨的employees文件,導出的結構一致[root@10-186-61-162 tmp]# ls -lh總用量 1.9G-rw-r----- 1 mysql mysql 579 3月 24 19:07 employees_01.csv-rw-r----- 1 mysql mysql 584 3月 24 18:48 employees_02.csv-rw-r----- 1 mysql mysql 576 3月 24 18:48 employees_03.csv-rw-r----- 1 mysql mysql 1.9G 3月 26 17:15 sbtest1.csv## 導入命令,其中對對文件用employees_*做模糊匹配util.import_table( ['/data/mysql/3306/tmp/employees_*', ], {'schema': 'employees', 'table': 'emp','dialect': 'csv-unix','skipRows': 0,'showProgress': True,'characterSet': 'utf8mb4','columns': [1,2,3,4,5,6], ## 文件中多少個列就用多少個序號標識就行'decodeColumns': { 'emp_no': '@1', ## 對應文件中的第1列 'birth_date': '@2', ## 對應文件中的第2個列 'first_name': 'upper(@3)', ## 對應文件中的第3個列,并做轉為大寫的處理 'last_name': 'lower(@4)', ## 對應文件中的第4個列,并做轉為大寫的處理 'full_name': 'concat(@3,’ ’,@4)', ## 將文件中的第3,4列合并成一列生成表中字段值 'gender': '@5', ## 對應文件中的第5個列 'hire_date': '@6', ## 對應文件中的第6個列 'modify_date': 'now()',## 用函數生成表中字段值 'delete_flag': 'if(@6<’1988-01-01’,’Y’,’N’)' ## 基于文件中第6列做邏輯判斷,生成表中對應字段值} }) ## 導入命令,其中對要導入的文件均明確指定其路徑util.import_table( ['/data/mysql/3306/tmp/employees_01.csv','/data/mysql/3306/tmp/employees_02.csv','/data/mysql/3306/tmp/employees_03.csv' ], {'schema': 'employees', 'table': 'emp','dialect': 'csv-unix','skipRows': 0,'showProgress': True,'characterSet': 'utf8mb4','columns': [1,2,3,4,5,6], ## 文件中多少個列就用多少個序號標識就行'decodeColumns': { 'emp_no': '@1', ## 對應文件中的第1列 'birth_date': '@2', ## 對應文件中的第2個列 'first_name': 'upper(@3)', ## 對應文件中的第3個列,并做轉為大寫的處理 'last_name': 'lower(@4)', ## 對應文件中的第4個列,并做轉為大寫的處理 'full_name': 'concat(@3,’ ’,@4)', ## 將文件中的第3,4列合并成一列生成表中字段值 'gender': '@5', ## 對應文件中的第5個列 'hire_date': '@6', ## 對應文件中的第6個列 'modify_date': 'now()',## 用函數生成表中字段值 'delete_flag': 'if(@6<’1988-01-01’,’Y’,’N’)' ## 基于文件中第6列做邏輯判斷,生成表中對應字段值} })
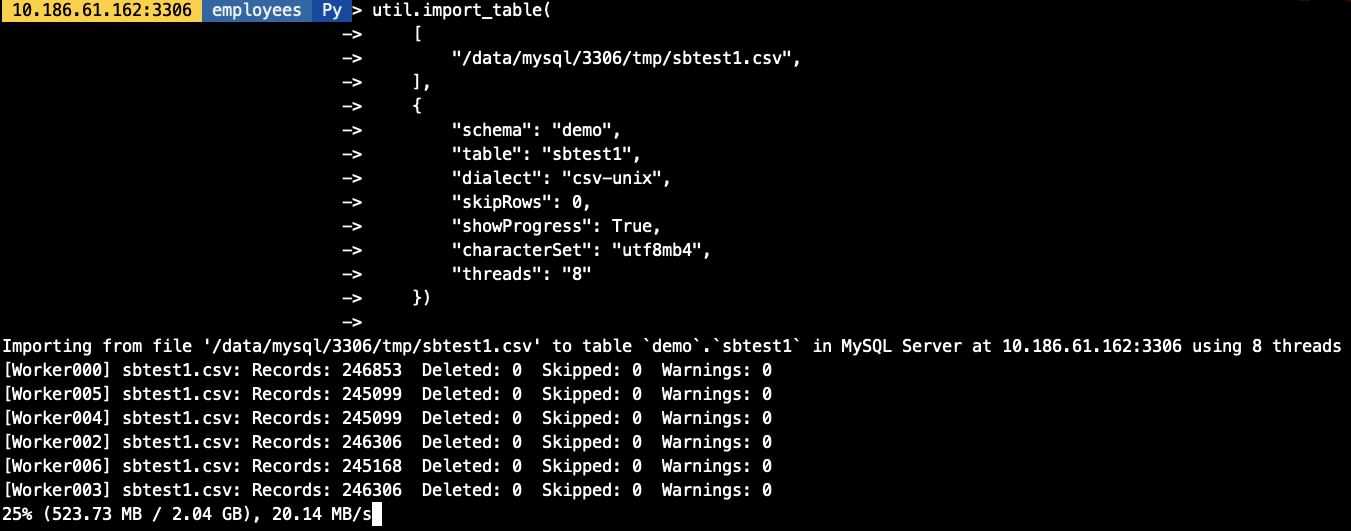
在實驗并發導入前我們創建一張1000W的sbtest1表(大約2G數據),做并發模擬,import_table用threads參數作為并發配置, 默認為8個并發.
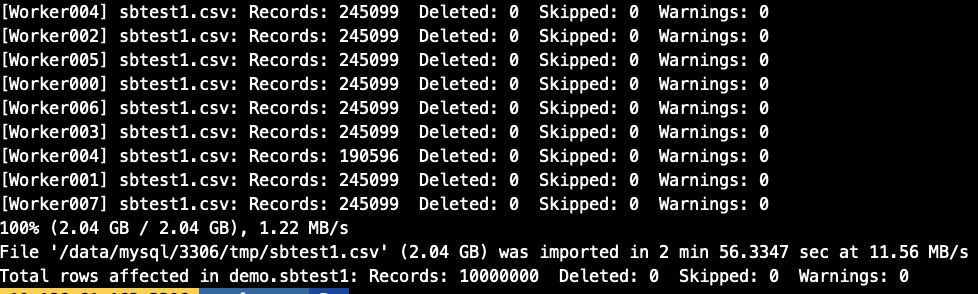
## 導出測試需要的sbtest1數據[root@10-186-61-162 tmp]# ls -lh總用量 1.9G-rw-r----- 1 mysql mysql 579 3月 24 19:07 employees_01.csv-rw-r----- 1 mysql mysql 584 3月 24 18:48 employees_02.csv-rw-r----- 1 mysql mysql 576 3月 24 18:48 employees_03.csv-rw-r----- 1 mysql mysql 1.9G 3月 26 17:15 sbtest1.csv## 開啟threads為8個并發util.import_table( ['/data/mysql/3306/tmp/sbtest1.csv', ], {'schema': 'demo', 'table': 'sbtest1','dialect': 'csv-unix','skipRows': 0,'showProgress': True,'characterSet': 'utf8mb4','threads': '8' })
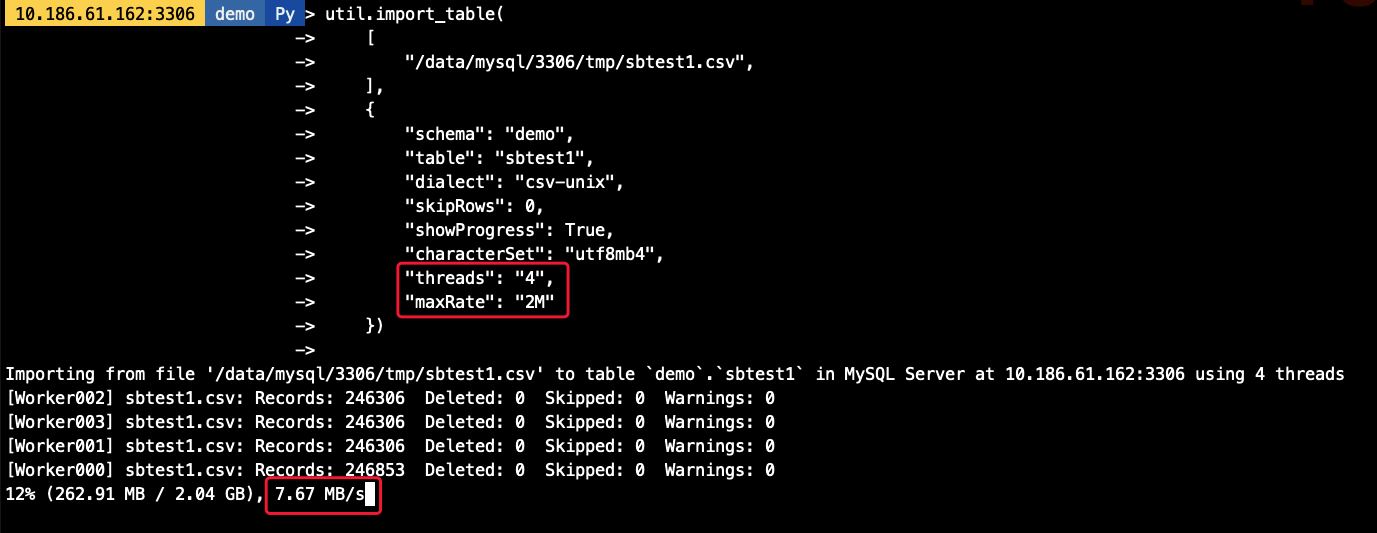
可以通過maxRate和threads來控制每個并發線程的導入數據,如,當前配置線程為4個,每個線程的速率為2M/s,則最高不會超過8M/s
util.import_table( ['/data/mysql/3306/tmp/sbtest1.csv', ], {'schema': 'demo', 'table': 'sbtest1','dialect': 'csv-unix','skipRows': 0,'showProgress': True,'characterSet': 'utf8mb4','threads': '4','maxRate': '2M' })
默認的chunk大小為50M,我們可以調整chunk的大小,減少事務大小,如我們將chunk大小調整為1M,則每個線程每次導入的數據量也相應減少
util.import_table( ['/data/mysql/3306/tmp/sbtest1.csv', ], {'schema': 'demo', 'table': 'sbtest1','dialect': 'csv-unix','skipRows': 0,'showProgress': True,'characterSet': 'utf8mb4','threads': '4','bytesPerChunk': '1M','maxRate': '2M' })
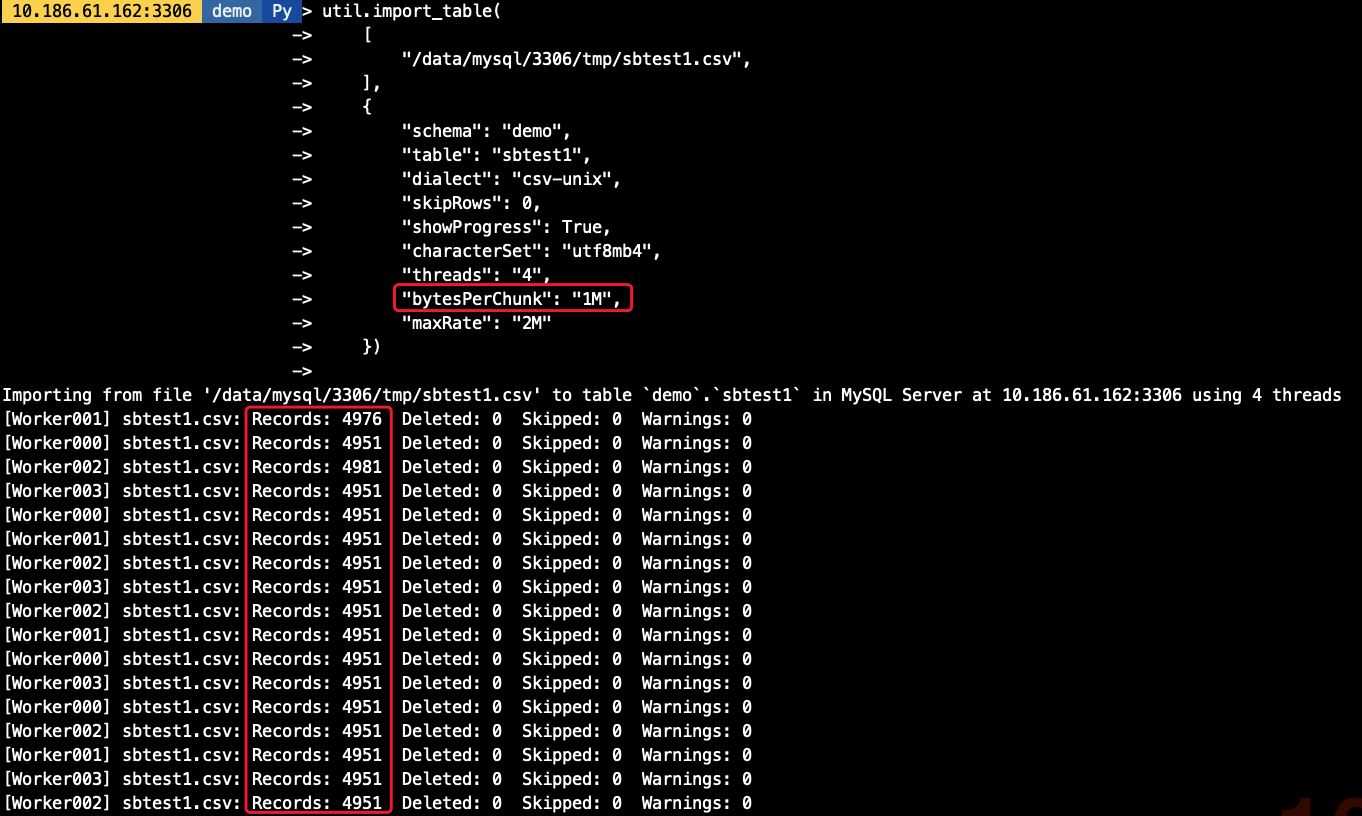
-- Load Data語句load data infile ’/data/mysql/3306/tmp/sbtest1.csv’into table demo.sbtest1character set utf8mb4fields terminated by ’,’enclosed by ’'’lines terminated by ’n’-- import_table語句util.import_table( ['/data/mysql/3306/tmp/sbtest1.csv', ], {'schema': 'demo', 'table': 'sbtest1','dialect': 'csv-unix','skipRows': 0,'showProgress': True,'characterSet': 'utf8mb4' })
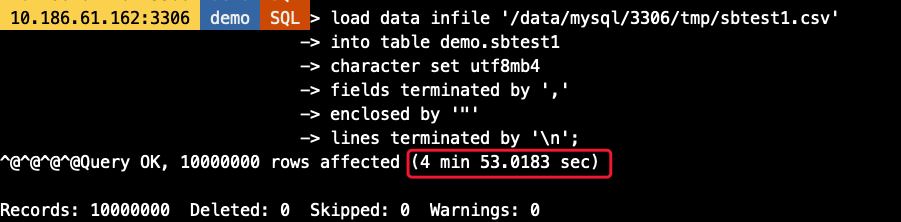

可以看到,Load Data耗時約5分鐘,而import_table則只要不到一半的時間即可完成數據導入,效率高一倍以上(虛擬機環境磁盤IO能力有限情況下)
5. 技術總結 import_table包含了Load Data幾乎所有的功能 import_table導入的效率比Load Data更高 import_table支持對導入速度,并發以及每次導入的數據大小做精細控制 import_table的導入進度報告更加詳細,便于排錯及時間評估,包括 導入速度導入總耗時每批次導入的數據量,是否存在Warning等等導入最終的匯總報告到此這篇關于MySQL import_table數據導入的實現的文章就介紹到這了,更多相關MySQL import_table數據導入內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備