如何基于Python實現(xiàn)word文檔重新排版
介紹
舍友從網(wǎng)上下載的word題庫文檔很亂,手動改了大半天才改了一點,想起python是大名鼎鼎的自動化腳本,于是乎開始了python對word的一頓瞎操作。
分析需求
對文檔中的內(nèi)容進(jìn)行分析,只留下題目,選項,并且題號要從1開始。
編寫代碼
pip安裝python-docx模塊
讀取word文檔內(nèi)容(如果是以.doc后綴的文件需另存為.docx文件!)
from docx import Document# 打開文件srcdocx = Document(‘src.docx‘)# 遍歷所有段落for p in srcdocx.paragraphs: print(p.text)
輸出效果:

分析所需要刪除的內(nèi)容:
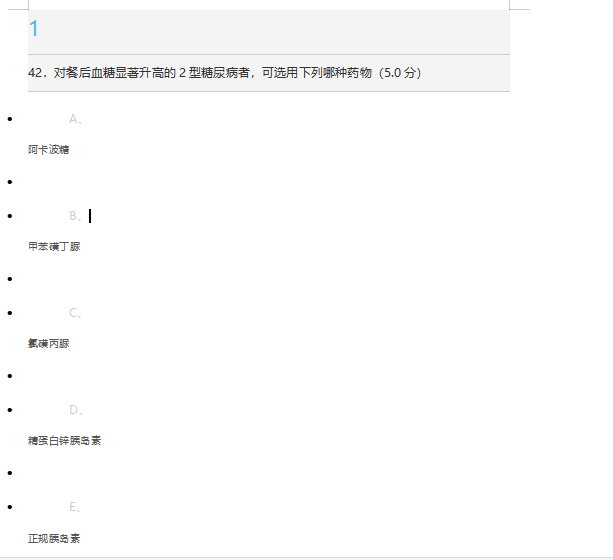
需求1:
142.對餐后血糖顯著升高的2型糖尿病者,可選用下列哪種藥物(5.0分)
刪除多余數(shù)字行
需求2:
42.對餐后血糖顯著升高的2型糖尿病者,可選用下列哪種藥物(5.0分)修改正確的題目序號
需求3:
刪除“窗體底端”“窗體頂端”
需求4:
A、阿卡波糖選項合成一行
需求5:
刪除多余空白行
編寫代碼
本質(zhì)上來講,實現(xiàn)就是從源文檔中取出一段文字進(jìn)行處理操作,然后保存到目標(biāo)文檔。
其中,需求1,3,5的實現(xiàn),只需要判斷一下取出的內(nèi)容是否是需要刪除的內(nèi)容,如果是,則不用保存到目標(biāo)文檔中,這樣就實現(xiàn)了“間接刪除”。
對于需求2的實現(xiàn),通過觀察我們不難發(fā)現(xiàn),序號后面總有一個'. ',所以我們只需要獲取到這個的坐標(biāo),把前面的錯誤序號刪除,插入正確的序號到處理字符串,最后保存到新文檔,這樣就完成了“修正題目序號”。
需求4的實現(xiàn)類似需求2,只需要找到 “、” 符號就行,然后進(jìn)行類似操作,就能實現(xiàn) “合并兩行”。
from docx import Document# 判斷字符串是否為數(shù)字def is_number(s): try: float(s) return True except ValueError: pass try: import unicodedata unicodedata.numeric(s) return True except (TypeError, ValueError): pass return False# 修正錯誤題目序號# src,源字符串 nPos,序號結(jié)束下標(biāo) cnt,正確序號def changeNum(src,nPos,cnt): s = src[:0] + src[nPos:] str_list = list(s) str_list.insert(0, str(cnt)) dest = ‘‘.join(str_list) return dest # 源文檔srcdocx = Document(‘src.docx‘)# 目標(biāo)文檔outDocx = Document()idx = 0 # 遍歷下標(biāo)length = len(srcdocx.paragraphs) # 總段落數(shù)cnt = 1 # 遍歷序號sum = 1 # 修改總次數(shù)while(1): if idx >= length: break src = srcdocx.paragraphs[idx].text # 實現(xiàn)需求1,3,5 if((src == '窗體底端') or (src =='窗體頂端') or (src == '') or (is_number(src))) : print(f'正在修改第{sum}處錯誤 {src}') sum = sum + 1 # 計算修改的次數(shù) idx = idx + 1 continue # 實現(xiàn)需求2 nPos1 = src.find('.') if nPos1 != -1 : # 查找到有序號的行 dest = changeNum(src,nPos1,cnt) print(f'正在修改第{sum}處錯誤 {src}') sum = sum + 1 # 計算修改的次數(shù) cnt = cnt + 1 # 序號后移 outDocx.add_paragraph(dest) # 寫入數(shù)據(jù)到新word # 實現(xiàn)需求4 nPos2 = src.find(‘、‘) if nPos2 != -1 : src2 = srcdocx.paragraphs[idx+1].text outDocx.add_paragraph(src+src2) idx = idx + 1 print(f'正在修改第{sum}處錯誤 {src},{src2}') sum = sum + 1 # 計算修改的次數(shù) idx = idx + 1 outDocx.save(‘out.docx‘)print(f'修改完成!共計{sum}個錯誤!')
運行效果:

最終效果

總結(jié)
Python還是一個極為強大的工具,并且門檻低,易入門,以后我要多多學(xué)習(xí)Python!如果我的博客能給你點思路,那就發(fā)揮了很大的作用了!人生苦短,我用Python~
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. python中scrapy處理項目數(shù)據(jù)的實例分析2. GIT相關(guān)-IDEA/ECLIPSE工具配置的教程詳解3. js抽獎轉(zhuǎn)盤實現(xiàn)方法分析4. IntelliJ IDEA導(dǎo)入jar包的方法5. 快速搭建Spring Boot+MyBatis的項目IDEA(附源碼下載)6. 教你在 IntelliJ IDEA 中使用 VIM插件的詳細(xì)教程7. Python requests庫參數(shù)提交的注意事項總結(jié)8. iOS實現(xiàn)點贊動畫特效9. SpringBoot參數(shù)校驗與國際化使用教程10. PHP橋接模式Bridge Pattern的優(yōu)點與實現(xiàn)過程
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備