詳解Python爬蟲爬取博客園問題列表所有的問題
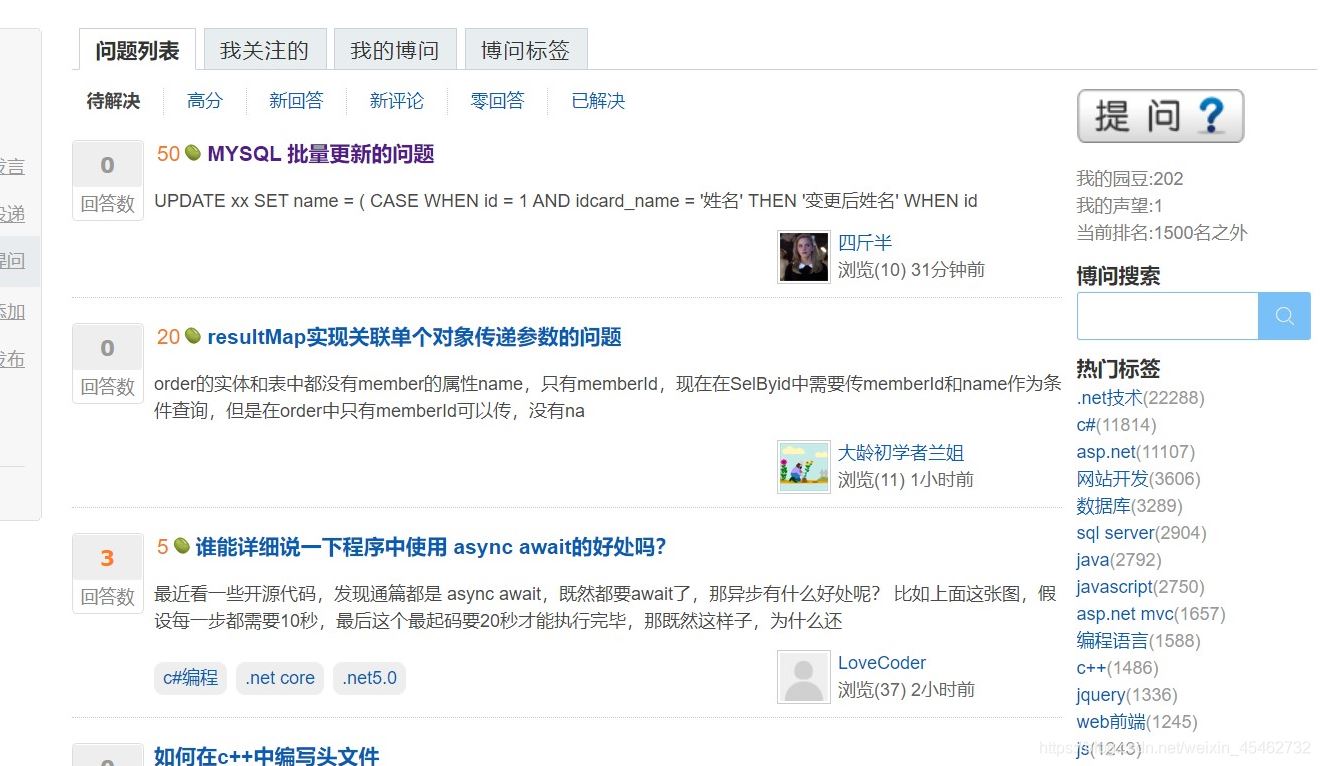
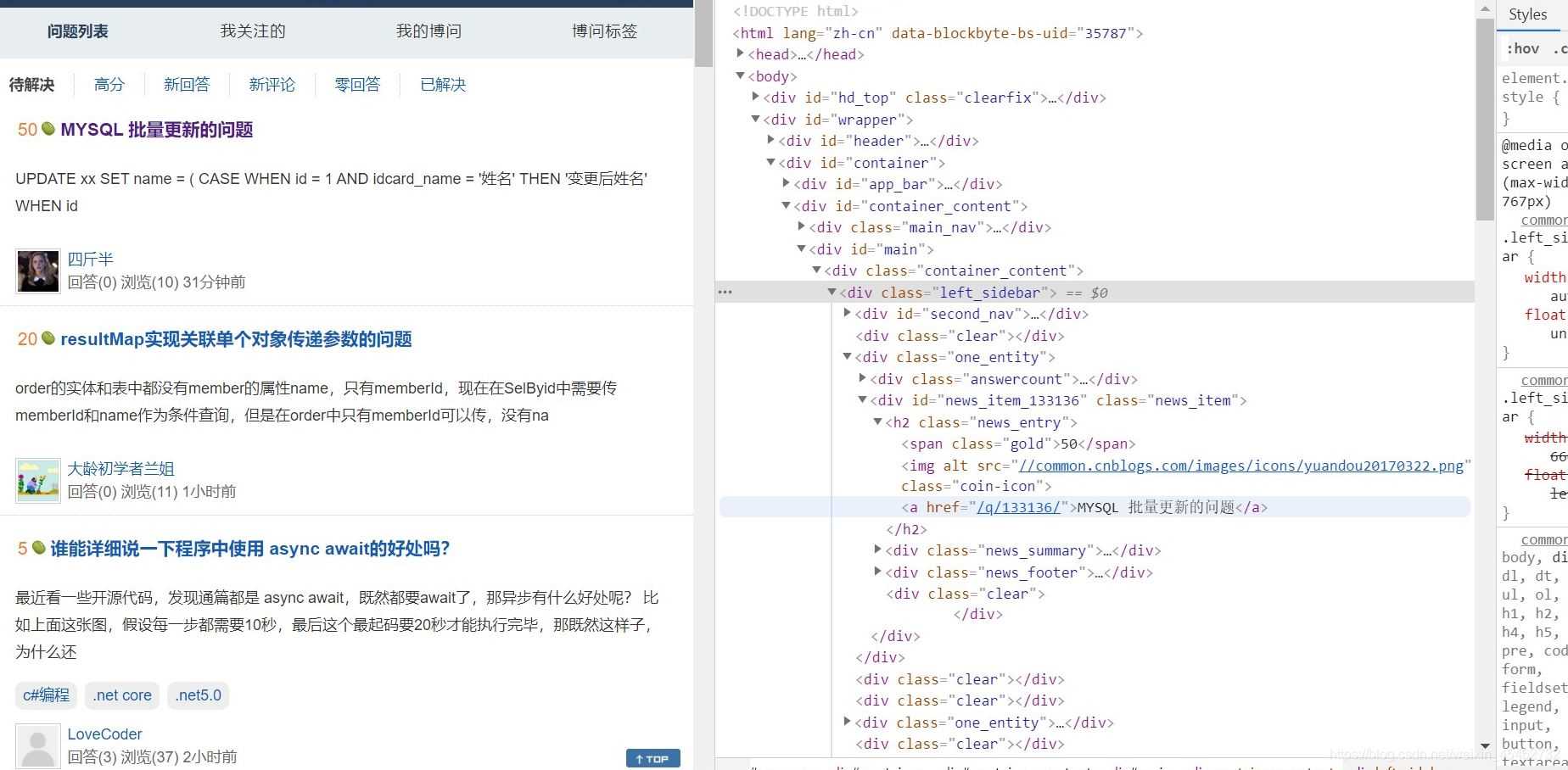
可以發現在div class ='one_entity'中存在頁面中分別對應每一個問題接著div class ='news_item'中h2標簽下是我們想要拿到的數據
三.代碼實現首先導入requests和BeautifulSoup
import requestsfrom bs4 import BeautifulSoup
由于很多網站定義了反爬策略,所以進行偽裝一下
headers = { ’User-Agent’: ’Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 87.0.4280.141Safari / 537.36’ }
在這里User-Agent只是其中的一種方式,而且大家的User-Agent可能不同。
爬取數據main代碼
url = ’https://q.cnblogs.com/list/unsolved?’ fp = open(’blog’, ’w’, encoding=’utf-8’) for page in range(1,26): page = str(page) param = { ’page’:page } page_text = requests.get(url=url,params=param,headers=headers).text page_soup = BeautifulSoup(page_text,’lxml’) text_list = page_soup.select(’.one_entity > .news_item > h2’) for h2 in text_list: text = h2.a.string fp.write(text+’n’) print(’第’+page+’頁爬取成功!’)
注意一下這里,由于我們需要的是多張頁面的數據,所以在發送請求的url中我們就要針對不同的頁面發送請求,https://q.cnblogs.com/list/unsolved?page=我們要做的是在發送請求的url時候,根據參數來填充頁數page,代碼實現:
url = ’https://q.cnblogs.com/list/unsolved?’ for page in range(1,26): page = str(page) param = { ’page’:page } page_text = requests.get(url=url,params=param,headers=headers).text
將所有的h2數組拿到,進行遍歷,通過取出h2中a標簽中的文本,并將每取出來的文本寫入到文件中,由于要遍歷多次,所以保存文件在上面的代碼中。
text_list = page_soup.select(’.one_entity > .news_item > h2’) for h2 in text_list: text = h2.a.string fp.write(text+’n’)
完整代碼如下:
import requestsfrom bs4 import BeautifulSoupif __name__ == ’__main__’: headers = { ’User-Agent’: ’Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 87.0.4280.141Safari / 537.36’ } url = ’https://q.cnblogs.com/list/unsolved?’ fp = open(’blog’, ’w’, encoding=’utf-8’) for page in range(1,26): page = str(page) param = { ’page’:page } page_text = requests.get(url=url,params=param,headers=headers).text page_soup = BeautifulSoup(page_text,’lxml’) text_list = page_soup.select(’.one_entity > .news_item > h2’) for h2 in text_list: text = h2.a.string fp.write(text+’n’) print(’第’+page+’頁爬取成功!’)四.運行結果
運行代碼:
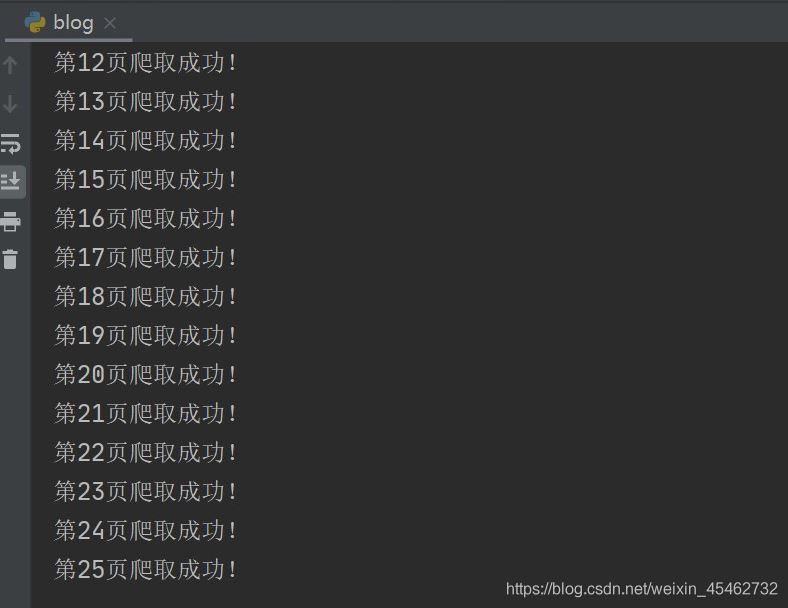
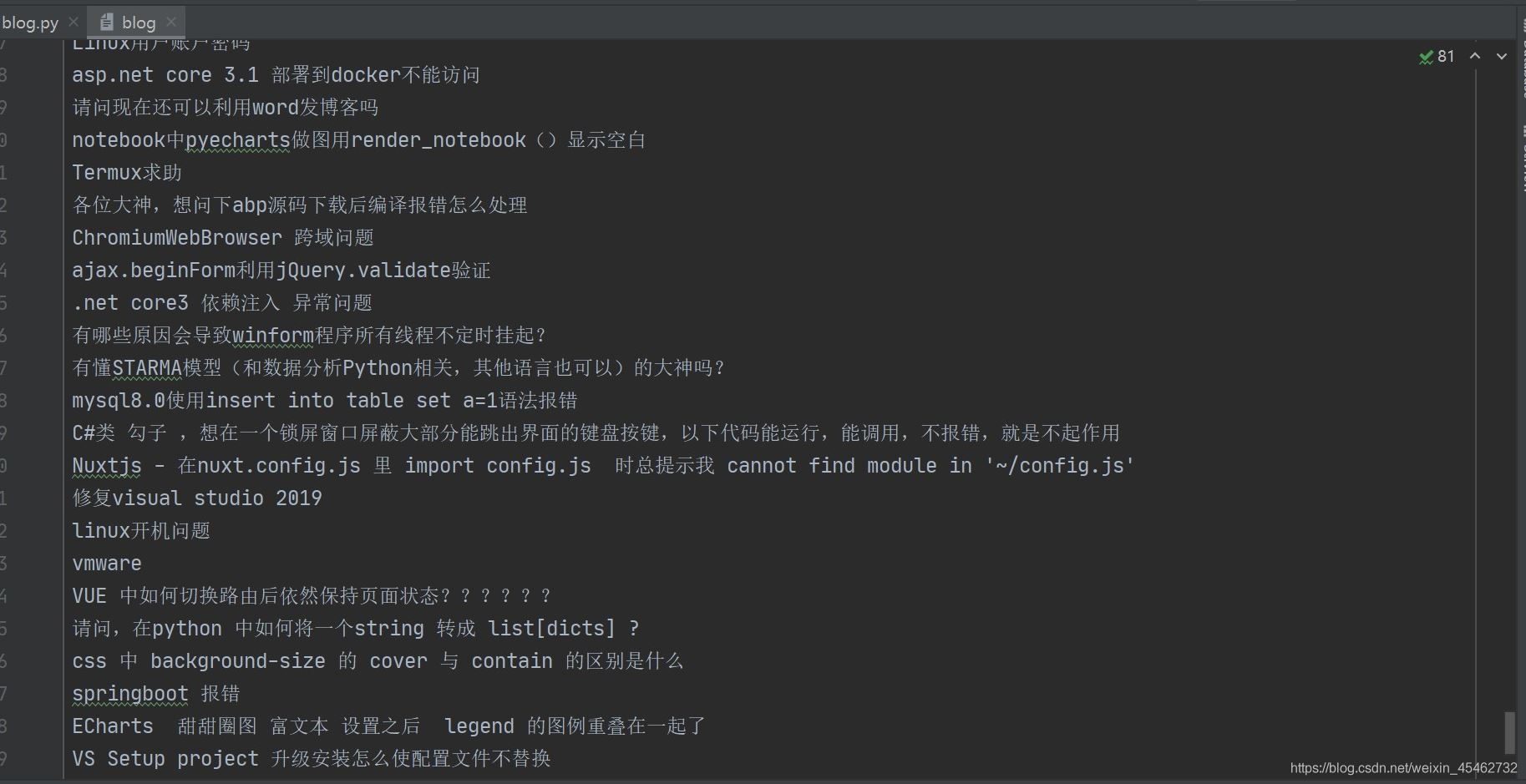
到此這篇關于詳解Python爬蟲爬取博客園問題列表所有的問題的文章就介紹到這了,更多相關Python爬蟲爬取列表內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備