基于python3.7利用Motor來異步讀寫Mongodb提高效率(推薦)
如果使用Python做大型海量數據批量任務時,并且backend用mongodb做數據儲存時,常常面臨大量讀寫數據庫的情況。尤其是大量更新任務,由于不能批量操作,我們知道pymongo是同步任務機制,相當耗時。
如果采用多線程、多進程的方案確實有效,但編寫麻煩、消耗系統資源大(pymongo還不允許fork線程中共用連接)。這里主要瓶頸在于IO,使用單線程異步操作就會效果很好。
Motor是一個異步mongodb driver,支持異步讀寫mongodb。它通常用在基于Tornado的異步web服務器中。
Motor同時支持使用asyncio(Python3.4以上標準庫)作為異步模型,使用起來十分方便。
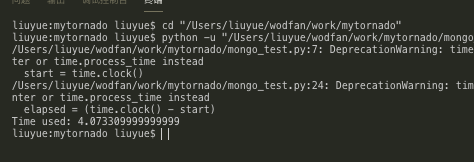
我們來測試一下效率,使用傳統pymongo來進行批量讀寫 mongo_test.py:
host = ’127.0.0.1’port = 27017database = ’LiePin’import timestart = time.clock()from pymongo import MongoClientconnection = MongoClient( host, port)db = connection[database]for doc in db.LiePin_Analysis1.find({}, [’_id’, ’JobTitle’, ’is_end’]): db.LiePin_Analysis1.update_one({’_id’: doc.get(’_id’)}, { ’$set’: { ’is_end’: 1 } })elapsed = (time.clock() - start)print('Time used:',elapsed)
運行一下,發現用了4秒左右
再使用motor以異步的形式來編寫腳本 motor_test.py
host = ’127.0.0.1’port = 27017database = ’LiePin’import timestart = time.clock()import asynciofrom motor.motor_asyncio import AsyncIOMotorClientconnection = AsyncIOMotorClient( host, port)db = connection[database]async def run(): async for doc in db.LiePin_Analysis1.find({}, [’_id’, ’JobTitle’, ’is_end’]): db.LiePin_Analysis1.update_one({’_id’: doc.get(’_id’)}, {’$set’: {’is_end’:0}})asyncio.get_event_loop().run_until_complete(run())elapsed = (time.clock() - start)print('Time used:',elapsed)
僅僅1秒左右就完成了任務

效率由此可見一斑
到此這篇關于基于python3.7利用Motor來異步讀寫Mongodb提高效率(推薦)的文章就介紹到這了,更多相關python異步讀寫Mongodb內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備